随机梯度下降
组件介绍
**“随机梯度下降”(Stochastic Gradient Descent)**控件使用梯度下降的随机逼近最小化目标函数,实现了随机梯度下降算法。可用于分类任务或回归任务。
随机梯度下降算法使用线性函数使所选择的损失函数最小化。该算法通过一次考虑一个样本逼近真实的梯度,并且同时基于损失函数的梯度来更新模型。该算法对于大规模和稀疏的数据集特别有效。
- 输入:
- data:数据集
- pre: 预处理方法
- 输出:
- lrn: 在交互页面中配置参数后的SGD学习算法
- mod: 已训练的模型(仅当输入端data存在时�,才会有输出信息)
页面介绍
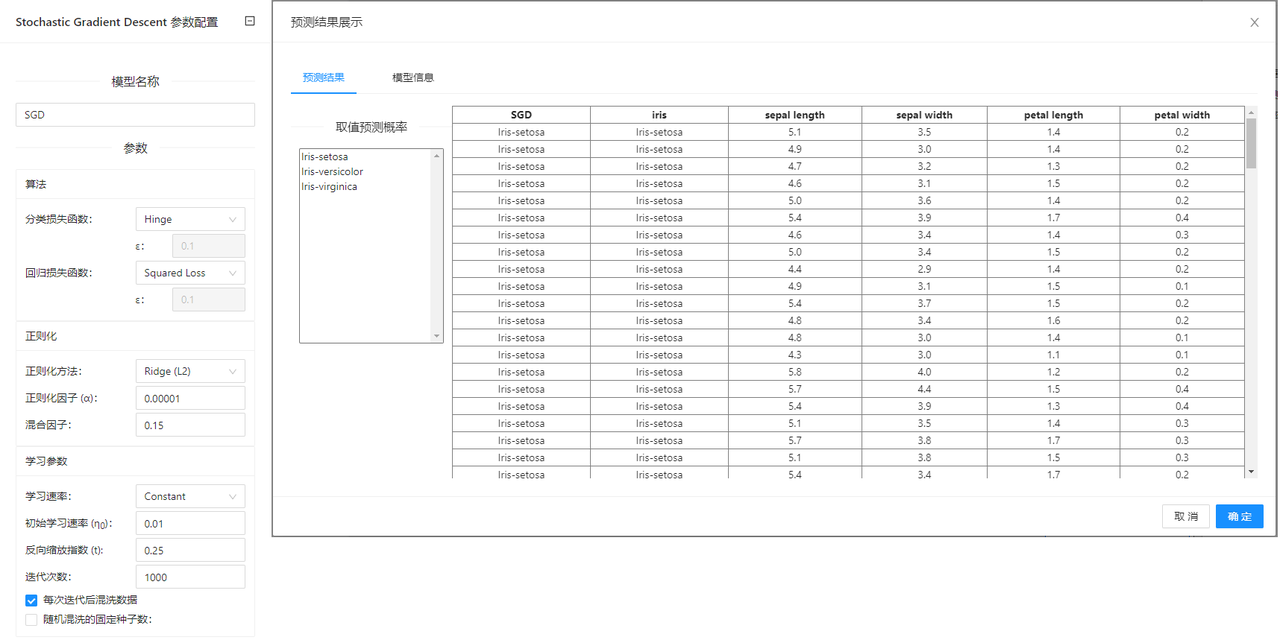
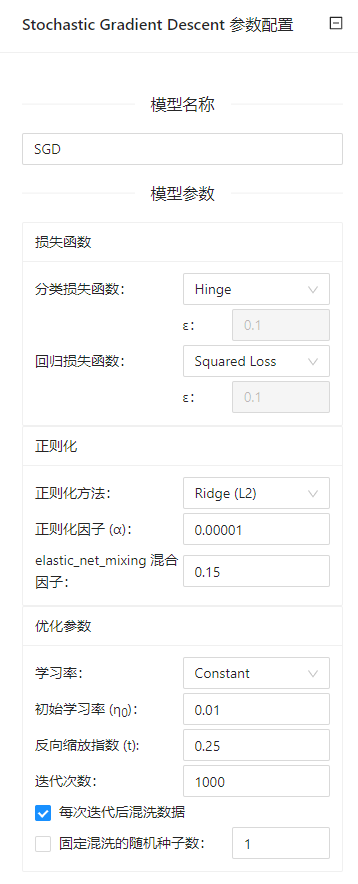
点击**“随机梯度下降”(Stochastic Gradient Descent)**控件查看参数配置页面,如下图所示:
参数选项
| 选项 | 说明 | 取值范围 | 样例值 | |
|---|---|---|---|---|
| 模型名称 | 设置模型名称,用于在其他组件中区分不同的模型 | 非空字符串 | SGD | |
| 算法 | 分类损失度函数 | 分类任务支持的损失函数 | Hinge(线性 SVM) | Hinge |
| 回归损失度函数 | 回归任务支持的损失函数 | Squared Loss(平方损失,拟合到普通的最小二乘法) | Squared Loss | |
| 正则化 | 正则化方法 | 正则化方法penalty | None | |
| 正则化因子 | 乘以正则化项的常数,值越大,正则化力度越大 | 0.00001~1 | 0.01 | |
| 混合因子 | l1 raio,为0时对应L2正则化,为1时对应L1正则化 | 0~1 | 0 | |
| 学习参数 | 学习率 | Constant:学习率保持不变 eta = eta0 | Constant | Constant |
| 初始学习率 | 学习率初始值 | 0.00001~1 | 0.01 | |
| 反向缩放指数 | 学习率逆放指数 | 0~1 | 0.25 | |
| 迭代次数 | 算法运行的最大迭代次数 | 1~1000000 | 5 | |
| 每次迭代后混洗数据 | 每次迭代时是否对训练数据进行混洗 | 勾选/不勾选 | 不勾选 | |
| 随机混洗的固定种子数 | 用于数据混洗 | 0~1000 | 1 |
使用案例
在下图所示的案例中,使用**“加载文件”(File)控件加载数据集,连接“随机梯度下降”(Stochastic Gradient Descent)控件构建模型,之后把“加载文件”(File)控件以及“随机梯度下降”(Stochastic Gradient Descent)控件与“预测”(Predictions)**控件连接起来查看预测的结果。
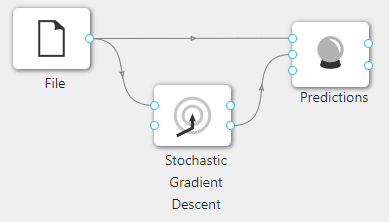
案例中加载 iris 数据集,其余参数使用默认值。案例中控件的配置以及执行结果如下图所示。