自适应提升算法
组件介绍
**“自适应提升算法”(AdaBoost)**是一种集成学习算法,将较弱的机器学习算法作为输入,可提升该算法的性能。可用于分类任务或回归任务。
AdaBoost是一种迭代算法,在每一轮中加入一个新的弱分类器,直到达到某个预定的足够小的错误率。每一个训练样本都被赋予一个权重,表明它在某个分类器选入训练集的概率。如果某个样本点已经被准确分类,那么在构造下一个训练集中,它被选中的概率就被降低;相反,如果某个样本点没有被准确分类,它的权重就会被提高。通过这种方式。AdaBoost能聚焦于那些较难分(更富信息)的样本上。
- �输入:
- data:数据集
- pre: 预处理方法
- lrn: 机器学习算法
- 输出:
- lrn: 在交互页面中配置参数后的AdaBoost学习算法
- mod: 已训练的模型(仅当输入端data存在时,才会有输出信息)
页面介绍
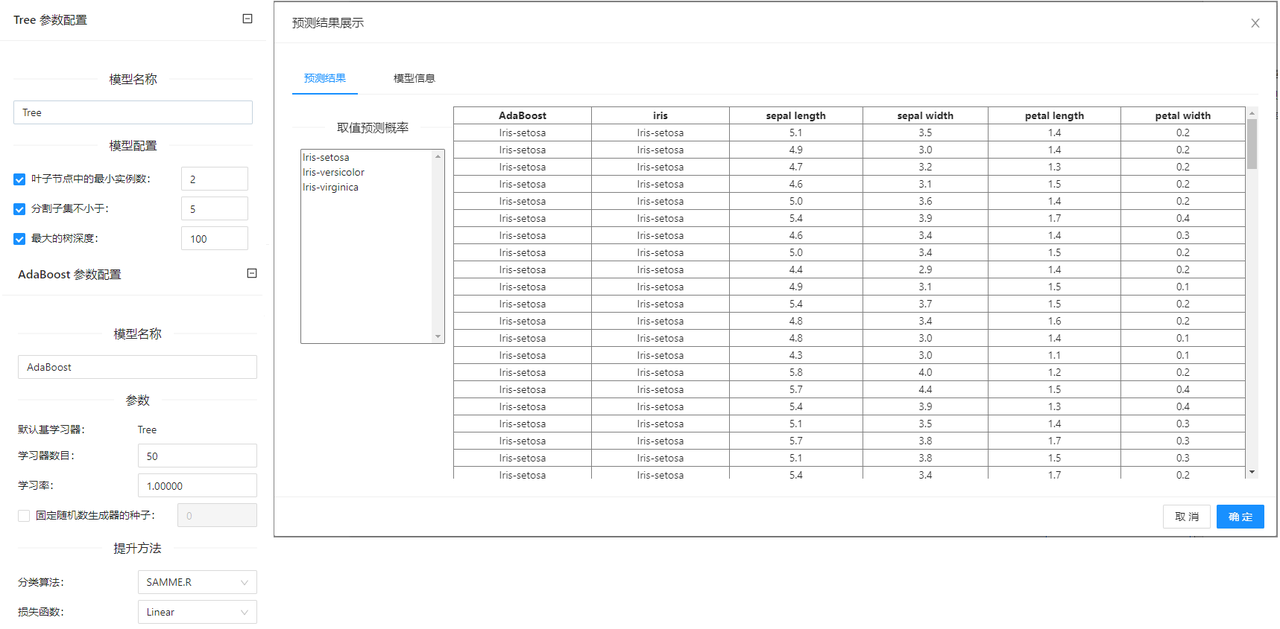
点击**“自适应提升算法”(AdaBoost)**控件查看参数配置页面,如下图所示:

参数选项
| 选项 | 说明 | 取值范围 | 样例值 |
|---|---|---|---|
| 模型名称 | 设置模型名称,用于在其他组件中区分不同的模型 | 字符串 | AdaBoost |
| 参数 | 学习器数目 | 学习器数目:1 | 学习器数目:50 |
| 提升方法 | 分类算法:当输入 lrn 是分类算法时,该参数有效;选项包括 SAMME(用分类结果更新基础估计器的权重)和 SAMME.R(用概率估计来更新基础估计器的权重) | 分类算法: | 分类算法: |
使用案例
在下图所示的案例中,使用**“加载文件”(File)控件加载数据集,连接“自适应提升算法”(AdaBoost)控件构建模型,之后把“加载文件”(File)控件以及“自适应提升算法”(AdaBoost)控件与“预测”(Predictions)**控件连接起来查看基于已经构建的 AdaBoost 模型对输入数据进行预测的结果。
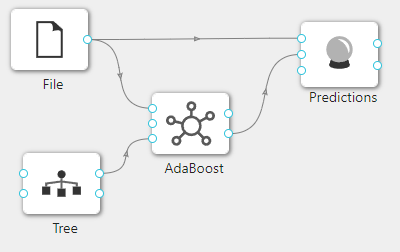
案例中加载 iris 数据集,其余使用默认配置。案例中控件的配置以及执行结果如下图所示。