CN2规则归纳
组件介绍
**“CN2规则归纳”(CN2 Rule Induction)**控件主要使用CN2算法从数据中推导出规则。可用于分类任务。
CN2归纳算法是一种用于规则归纳的学习算法,其设计目的是在训练数据不完善的情况下也能发挥作用。它基于AQ算法和ID3算法的思想。因此,它能创建类似AQ算法的规则集,但又能像ID3算法一样处理噪声数据。
- 输入:
- data:数据集
- pre: 预处理方法
- 输出:
- lrn: 在交互页面中配置参数后的CN2学习算法
- mod: 已训练的模型(仅��当输入端data存在时,才会有输出信息)
页面介绍
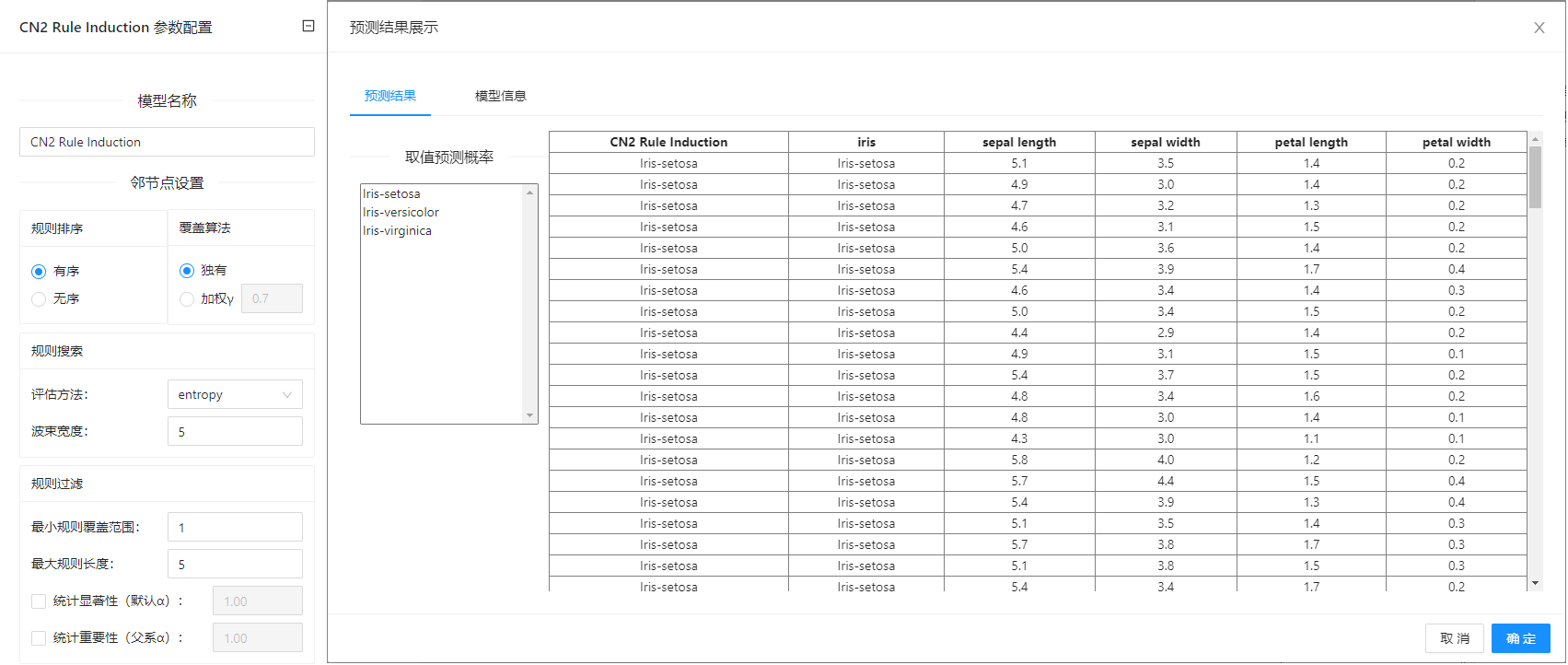
点击**“CN2规则归纳”(CN2 Rule Induction)**控件查看参数配置页面,如下图所示:
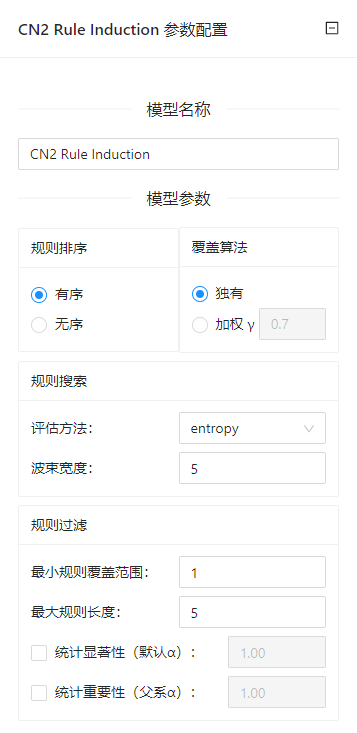
参数选项
| 选项 | 说明 | 样例值 | |
|---|---|---|---|
| 学习器名称 | 设置学习器的名称,用于在其他组件中区分不同的学习器 | 字符串 | CN2 Rule Induction |
| 规则排序 | 有序:归纳有序的规则(决策列表) 查找规则条件,大部分分类被归纳到规则的头部 | 有序 | 有序 |
| 覆盖算法 | 独有:在覆盖学习实例之后,将其从进一步考虑中移除。 | 独有 | 独有 |
| 规则搜索 | 评估方法:选择一个启发式评估找到假设: | 评估方法: | 评估方法:Entropy |
| 规则过滤 | 最小规则覆盖范围:发现的规则必须至少涵盖所要求的最小数量的例子,无序的规则必须涵盖大多数目标类的例子 | 最小规则覆盖范围:1 | 最小规则覆盖范围:1 |
使用案例
在下图所示的案例中,使用**“加载文件”(File)控件加载数据集,连接“CN2规则归纳”(CN2 Rule Induction)控件进行聚类,之后把“加载文件”(File)控件以及“CN2规则归纳”(CN2 Rule Induction)控件与“预测”(Predictions)控件连接起来查看基于已经构建的“CN2规则归纳”(CN2 Rule Induction)**模型对输入数据进行预测的结果。
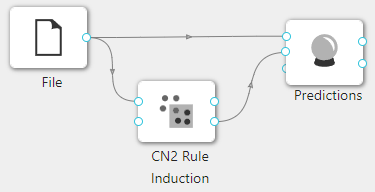
案例中加载 iris 数据集,其余参数使用默认值。案例中控件的配置以及执行结果如下图所示。