关联规则
组件介绍
“关联规则”(Association Rules) 控件实现了 FP-growth 频繁模式挖掘算法,从输入数据中归纳关联规则。对于分类规则的推导,该控件会跳过结果不属于类取值范围的规则。
关联规则(Association Rules)是反映一个事物与其他事物之间的相互依存性和关联性,是数据挖掘的一个重要技术,用于从大量数据中挖掘出有价值的数据项之间的相关关系。通常的做法是挖掘隐藏在数据中的相互关系,当两个或多个数据项的取值相互间高概率的重复出现时,那么就会认为它们之间存在一定的关联;即两项或多项属性之间存在关联,那么其中一项的属性值就可以依据其他属性值进行预测。
关联规则可以用这样的方式来表示:A→B,其中A被称为前提、先导或者左部(LHS),而B被称为结果、后继或者右部(RHS)。如果我们要描述关于尿布和啤酒的关联规则(买尿布的人也会买啤酒),那么我们可以这样表示:买尿布→买啤酒。
- 输入:
- data:数据集
- 输出:
- data:符合判定条件的数据示例
页面介绍
点击**“关联规则”(Association Rules)**控件查看参数配置页面,如下图所示:
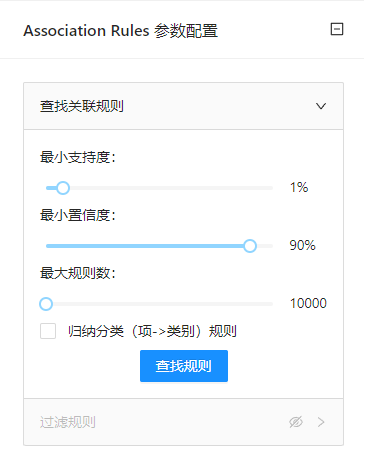
参数选项
| 选项 | 说明 | 取值范围 | 样例值 |
|---|---|---|---|
| 查找关联规则 | 向用户提供关联规则的查找条件。如果选中"归纳分类(项->类别)规则"被勾选,那么控件将只生成在规则的右侧(后继)具有类值的规则 | 最小支持度: | 最小支持度:1% |
| 过滤规则 | 先导: | 先导: | 先导: |
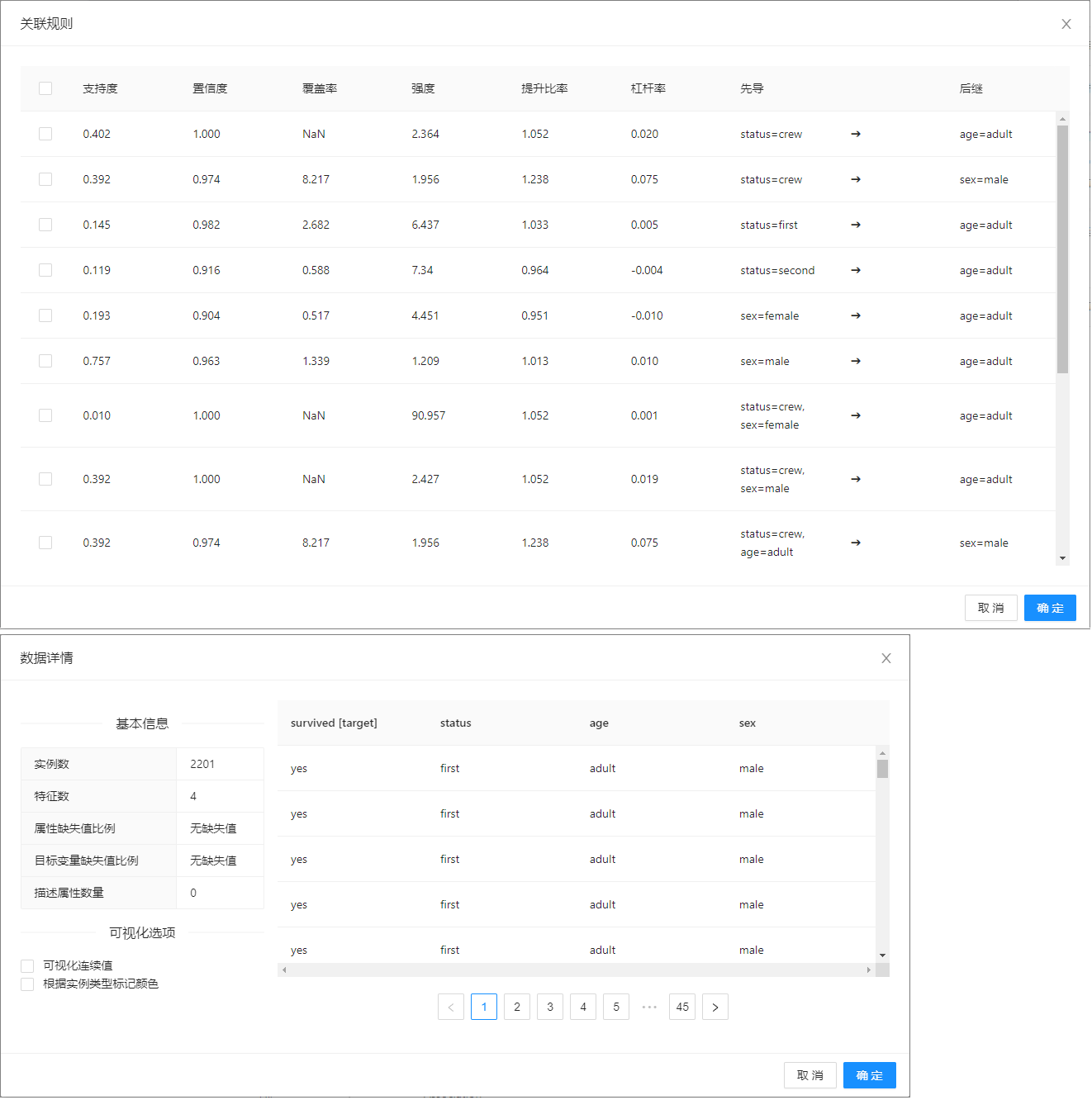
关联规则表
设置参数后,点击“查找规则”按钮,即可根据当前指定设置从输入数据中归纳关联规则。
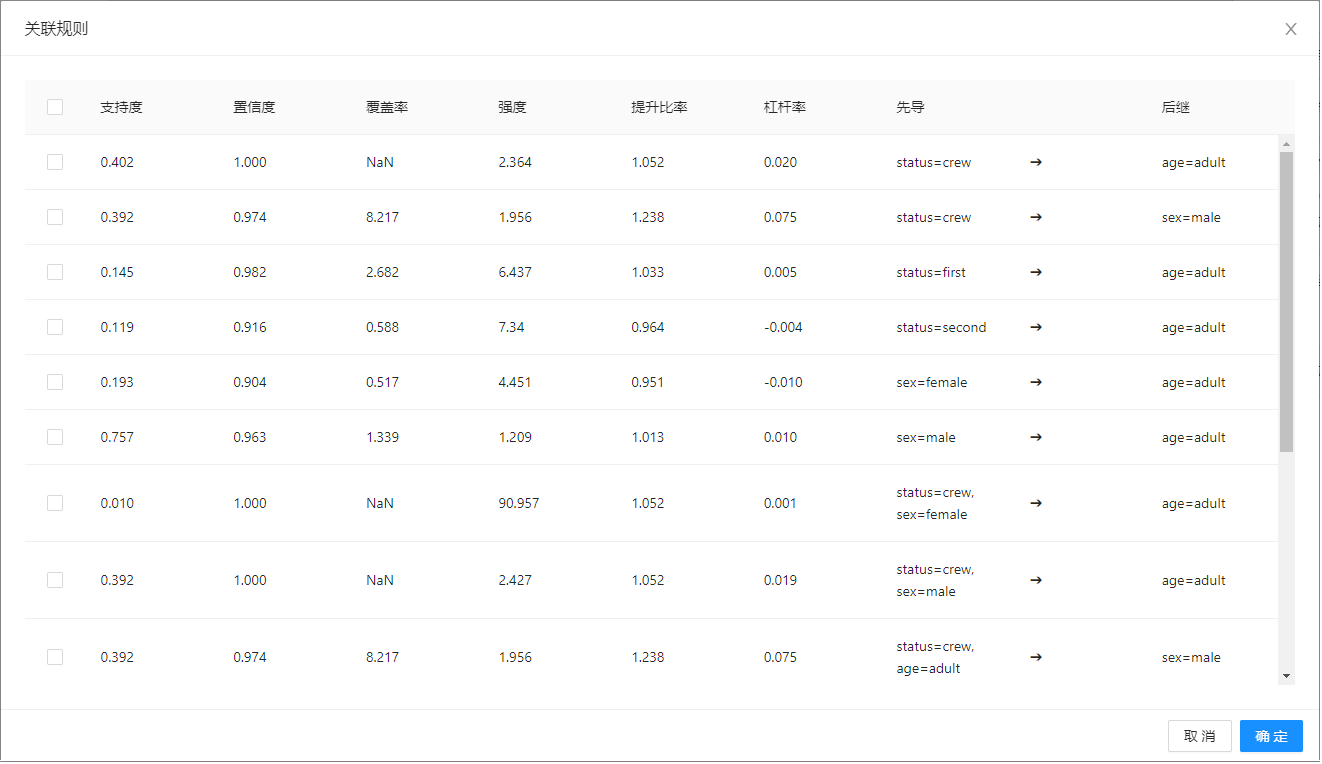
该表包含以下列:
| 列名 | 说明 |
|---|---|
| 支持度 | 项集或者规则在数据集中出现的频率,确定规则可以用于给定数据集的频繁程度 |
| 置信度 | 表明项集或规则被发现为真的概率 |
| 覆盖率 | 适用该规则的数据占比 |
| 强度 | |
| 提升比率 | 用来判断该规则是否具有实际价值,即规则出现的次数是否高于单一数据出现的次数,大于1说明该组合方式有效,小于1则说明无效 |
| 杠杆率 | 衡量数据集中同时出现X和Y的差异,以及在X和Y在统计上相关的情况下的期望值 |
| 先导 | 规则左部 |
| 后继 | 规则右部 |
使用案例
在下图所示的案例中,使用**“文件加载”(File)控件加载数据,使用“查看数据”(Data Table)控件查看数据集内容,通过“关联规则”(Association Rules)**查找满足条件的关联规则。
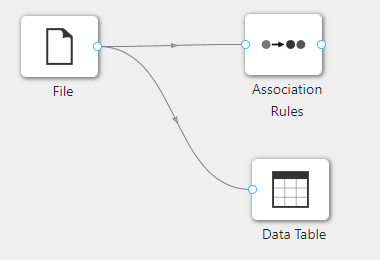
案例中加载 titanic 示例数据集,案例中控件执行结果如下图所示: