组件介绍
**“文本预处理”(Preprocess Text)**控件用于对文本数据集进行一系列预处理。
**“文本预处理”(Preprocess Text)**控件支持设置一系列文本预处理操作,包括转换、词语切分、标准化、过滤、N-grams范围、词性标注等处理。用户添加一系列操作后系统会根据用户添加处理的顺序对输入数据集进行处理。
页面介绍
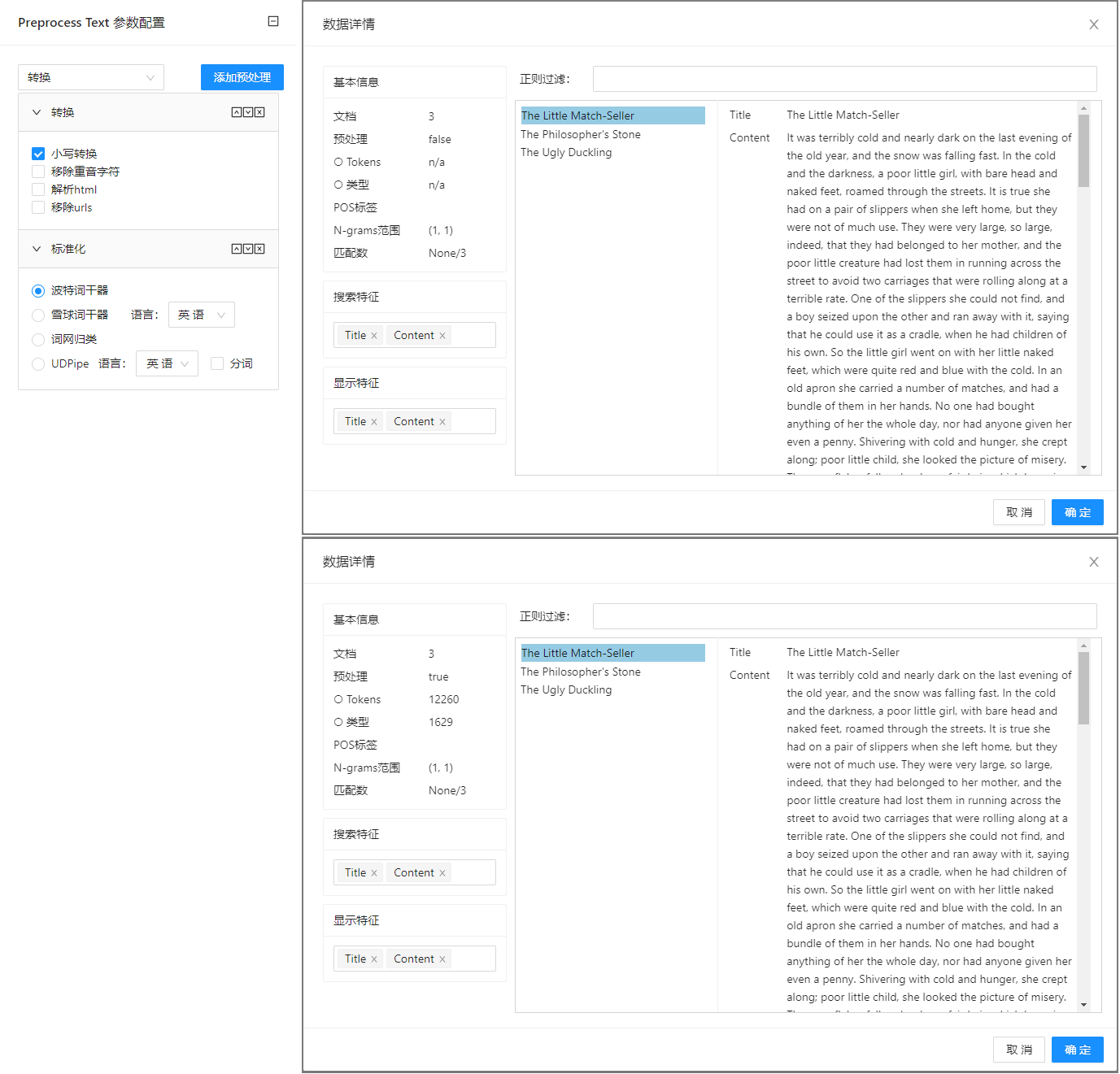
点击**“文本预处理”(Preprocess Text)**控件查看参数配置页面,如下图所示:

参数选项
| 选项 | 说明 | 取值范围 | 样例值 |
|---|
| 预处理选项 | 点击需要添加的文本处理选项,之后点击“添加预处理”按钮添加预处理操作 | 转换
词语切分
标准化
过滤
N-grams范围
词性标注 | |
| 转换 | 小写转换:在文本进行小写转换
移除重音字符:在文本中移除重音字符
解析 html:在文本中去除 html 的标签,如 <a href…>Some text</a> → Some text
移除 urls:移除文本中的 urls。如 This is a http://www.baidu.com/ url. → This is a url | 小写转换
移除重音字符
解析html
移除urls | 小写转换 |
| 词法切分 | 将文本分解成更小的单位:
单词 & 标点符号:将文本以单词和逗号进行分割,如 This example. → (This), (example), (.)
空格:使用空格分割文本,如 This example. → (This), (example.)
语句:使用句号分割文本,只保留完成的语句,如 This example. Another example. → (This example.), (Another example.)
正则表达式:使用正则表达式分割文本。 | 单词 & 标点符号
空格
语句
正则表达式 | 空格 |
| 标准化 | 进行词形还原,除英语之外的其它语言使用:
Porter Stemmer
Snowball Stemmer
WordNet Leammatizer
UDPipe | 波特词干器
雪球词干器
词网归类
UDPipe | 波特词干器 |
| 过滤 | 删除或选择单词:
停止词表:从文本中删除停用词(例如删除”和“、”或“、”“...),选择过滤的语言,默认选择的是英语。可以点击“上传”按钮,添加自定义的停用词文件,文件支持 .txt 类型。
词典:仅保留所提供的文件中的字。点击“上传”按钮添加 .txt 文件。
正则表达式:删除与正则表达式匹配的字。默认设置为删除标点符号。
文件频率:文档频率使令牌出现在在不少于指定的 数量 / 比例 的文件。如果你提供整数作为参数,它仅保留令牌出现在指定数量的文件。例如 DF=(3,5)仅保留令牌出现在3或多少 5 或更少的文档。如果提供浮点数作为参数,它仅保留令牌出现在文档指定的百分比。例如 DF=(0.3,0.5)仅保留令牌出现在 30% 到 50% 的文档。默认返回所有标记。
频繁记号:�保留指定数量的最频繁的令牌。默认是 100 个最频繁的令牌。 | 停止词表
词典
正则表达式
文件频率
频繁记号 | 停止词表 |
| N-grams | 范围从 1 到 10。 | 1~10 | |
| 词性标注 | 进行词性标注操作 | Averaged Perceptron Tagger
Treebank POS Tagger (MaxEnt) | Averaged Perceptron Tagger |
使用案例
在下图所示的案例中,使用**“加载语料库”(Corpus)控件加载文本数据集,使用“语料库查看器”(Corpus Viewer)控件查看文本数据,同时连接“文本预处理”(Preprocess Text)控件对数据进行文本预处理,之后使用“语料库查看器”(Corpus Viewer)**控件查看处理后的数据。
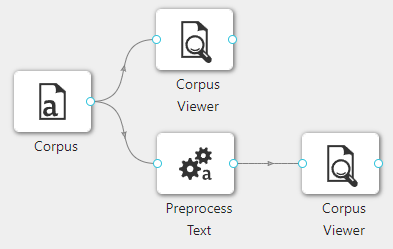
案例中加载“andersen”数据集,**“文本预处理”(Preprocess Text)**控件添加转换和标准化处理,参数使用默认参数,案例中控件的配置以及执行结果如下图所示。