离群值处理
组件介绍
**“离群值处理”(Outliers)**控件根据指定离群值检测策略对输入数据集进行离群值检测。
离群值是指与其他观测值有显著差异的数据点,在数据挖掘分析中,离群值可能会导致分析出现偏差,所以有时会剔除离群值后再进行模型训练。
- 输入:
- data:数据集
- 输出:
- inl:内群值数据集
- otl:离群值数据集
页面介绍
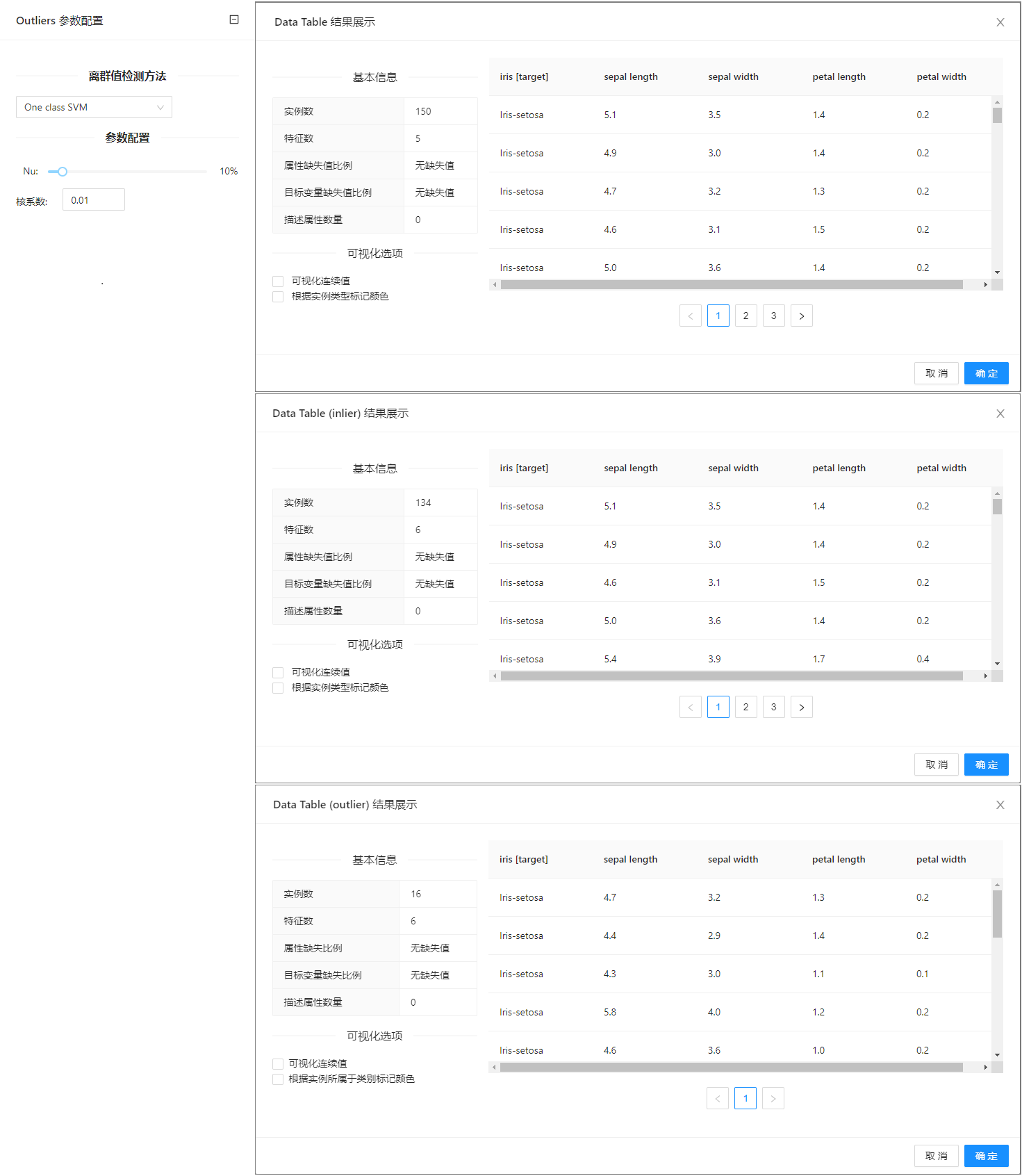
点击**“离群值处理”(Outliers)**控件查看参数配置页面,如下图所示:
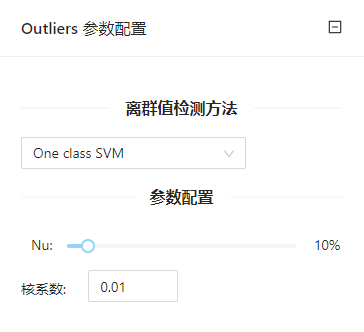
获取属性信息的逻辑如下:
- 优先解析直接上游组件的输出结果,需要您先将上游组件运行成功
- 如1不满足,将会追溯源头的File、SQL Table等加载数据的属性信息
若属性信息获取错误,可通过重置控件重新获取。
参数选项
| 选项 | 说明 | 取值范围 | 样例值 |
|---|---|---|---|
| 离群值检测方法及参数 | One class SVM:根据核心类对数据进行分类 | One class SVM | One class SVM |
使用案例
在下图所示的案例中,使用**“加载文件”(File)控件加载数据,通过“查看数据”(Data Table)控件查看加载数据的信息,同时使用“离群值处理”(Outliers)控件对数据集中离群值进行检测,之后通过“查看数据”(Data Table)**控件查看离群值数据集和内群值数据集。
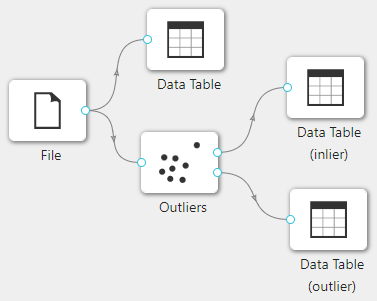
案例中��加载 iris 数据集,**“离群值处理”(Outliers)**使用默认配置。案例中控件的配置以及执行结果如下图所示。