缺失值处理
组件介绍
**“缺失值处理”(Impute)**控件用于处理数据集中的缺失值。
在构建数据挖掘分析工作流时,一些控件可能无法处理数据集中的缺失值,所以需要使用**“缺失值处理”(Impute)**控件处理(删除或替代)缺失值。
**“缺失值处理”(Impute)**控件提供了多种填补缺失值的方法,支持配置统一的缺失值处理方式,也支持对不同属性配置不同的缺失值处理方式。
- 输入:
- data:数据集
- lrn:一种学习算法,用于在基于模型估算值时使用,如果未传入,则默认为1-NN
- 输出:
- data:处理后的数据集
页面介绍
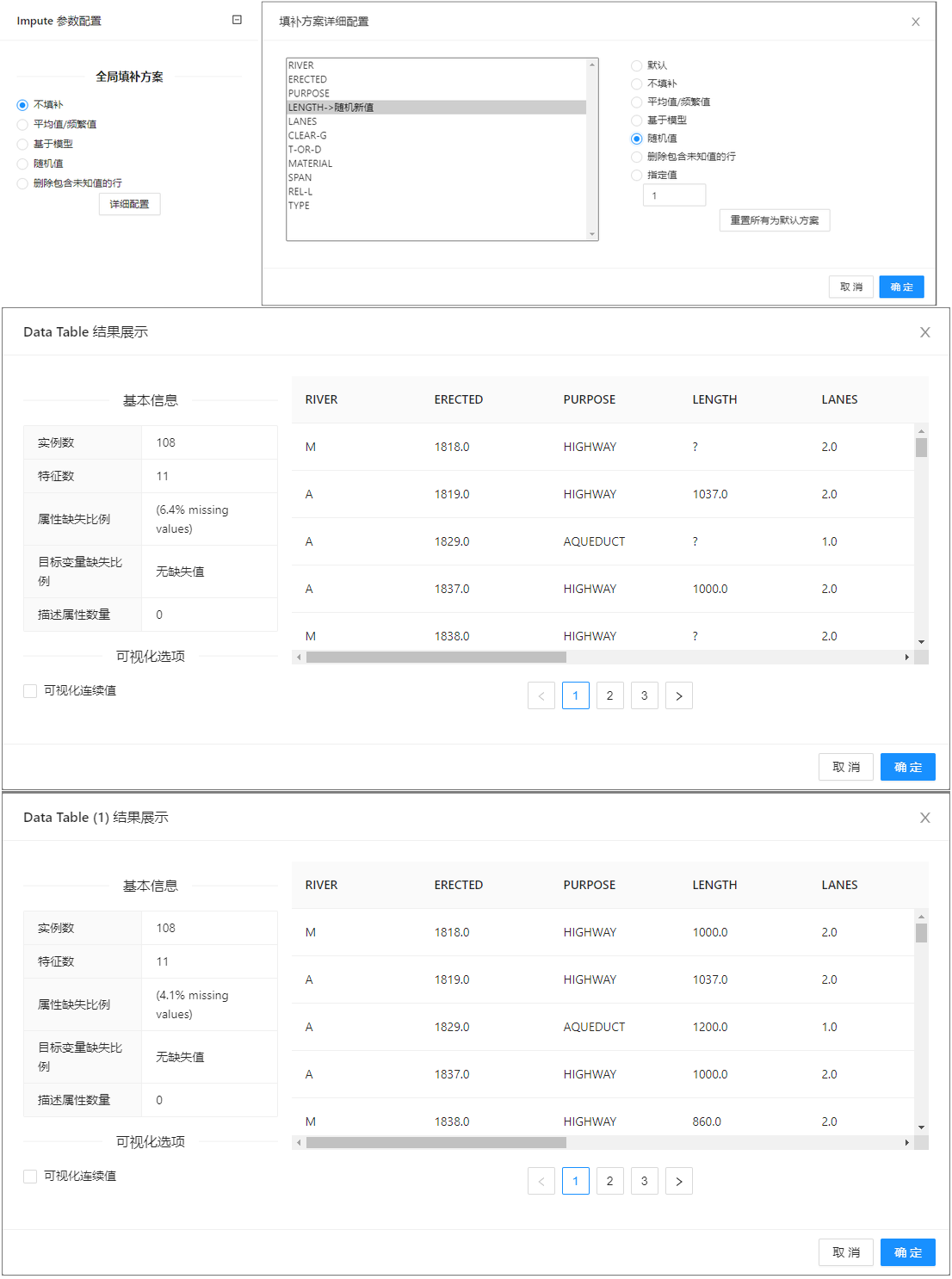
点击**“缺失值处理”(Impute)**控��件查看参数配置页面,如下图所示:
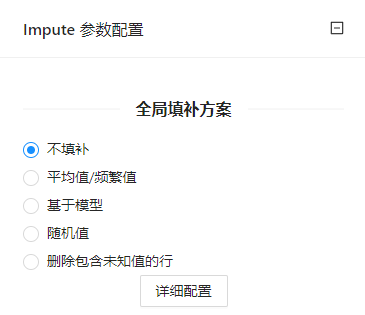
点击“详细配置”按钮,对输入数据集的属性进行详细配置:
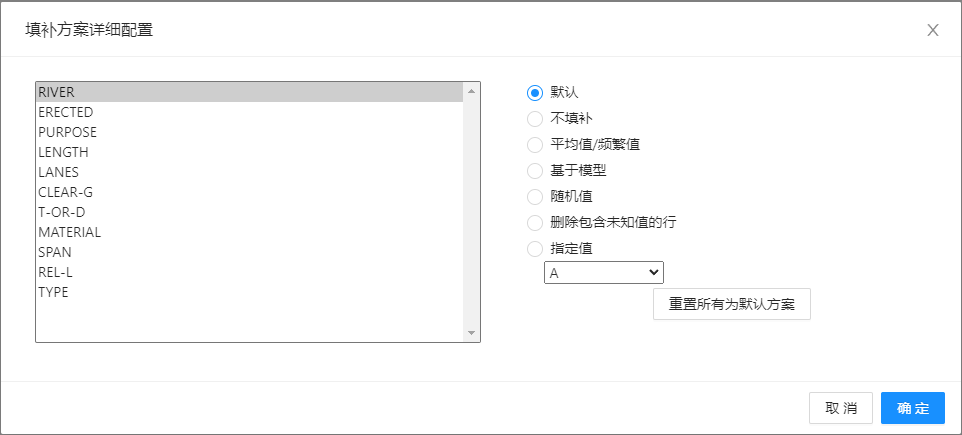
获取属性信息的逻辑如下:
- 优先解析直接上游组件的输出结果,需要您先将上游组件运行成功
- 如1不满足,将会追溯源头的File、SQL Table等加载数据的属性信息
若属性信息获取错误,可通过重置控件重新获取。
参数选项
| 选项 | 说明 | 取值范围 | 样例值 |
|---|---|---|---|
| 填补方法 | Impute 控件提供了以下几种处理缺失值方式(点击后将应用于所有属性上): | 不填补 | 平均值/频繁值 |
| 详细配置 | 详细配置页面中,左侧显示了各个属性及其使用的处理缺失值的方式,当用户想要针对某个属性设定特定的处理方式时,用户可以选中某些属性,在右侧方法中选择需要的处理方式即可。点击“重置所有为默认方法”,则所有单独设定的处理方式都重置为默认的处理方式。 | 填补方式包括 | 默认 |
使用案例
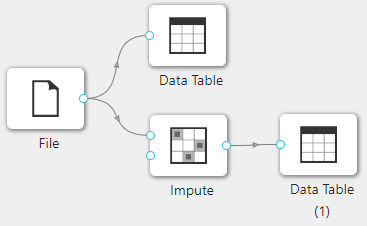
在下图所示的案例中,使用**“加载文件”(File)控件加载数据,通过“查看数据”(Data Table)控件查看加载数据的信息,同时使用“缺失值处理”(Impute)控件对数据集中包含缺失值的属性进行处理,之后通过“查看数据”(Data Table)**控件查看处理后的数据集。
案例中加载 bridges 数据集,全局填补方案选择“不填补”,打开详细配置页面,对于【LENGTH】属性指定“随机值”方法填充缺失值。案例中控件的配置以及执行结果如下图所示。