流查询
组件介绍
流查询步骤类型允许您使用来自转换中其他步骤的信息查找数据。来自 Source 步骤的数据首先读取到内存中,然后用于查找来自主流的数据。
- 输入:数据信息(表,数据库,文件等)输入内容
- 输出:查询成功的输出数据信息
组件图标

页面介绍
双击流查询组件得到下图所示的界面。
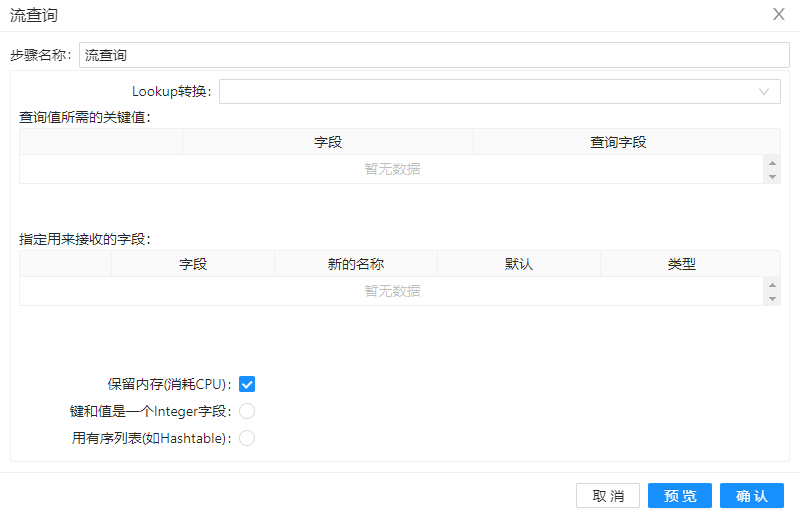
参数选项
流查询组件页面包含如下选项:
| 选项 | 说明 | 样例值 |
|---|---|---|
| 步骤名称 | 步骤的唯一名称,可以自定义名称或保留默认名称。 | 流查询 |
| Lookup 转换 | 查找数据来自的步骤名称 | |
| 查询值所需要的关键字 | 允许您指定用于查找值的字段的名称。 始终使用“等于”比较来搜索值 | |
| 指定用来接收的字段 | 您可以在此处指定要检索的字段的名称,以及在未找到值的情况下的默认值,或者在您不喜欢旧字段的情况下指定新的字段名 | |
| 保留内存(消耗CPU) | 对数据行进行编码,以在排序时保留内存。(技术背景:Hop将把查询数据作为原始字节存储在一个自定义的存储对象中,该对象使用字节的哈希码作为密钥。与计算哈希码有关的CPU成本较高,所需的内存较少) | |
| 键和值是一个 Integer 字段 | 在执行By排序时保留内存。 注意:仅在选中“保留内存”时有效。 不能与“用排序列表”选项结合使用。(技术背景:查找数据存储在类似于字节数组哈希图的自定义存储对象中,但不必转换为原始字节。它只需要长整数的哈希码。) | |
| 用有序列表(如Hashtable) | 启用使用排序列表存储值; 当处理包含宽行的数据集时,这可以提供更好的内存使用率。 注意:仅在选中“保留内存”时有效。 不能与“键和值正好是一个整数字段”选项结合使用。 (技术背景:查找数据放入一个元组中并存储在排序列表中。查找通过二叉树搜索完成。) |
案例示例
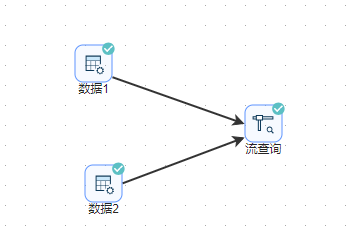
该案例主要读取来自两个“自定义常量数据”组件的数组,并按照“id”和“name”两个字段来进行匹配,并对这两个字段取一个新的字段名(id对应newId,name对应NewName)并输出。
总体流程如下图所示:
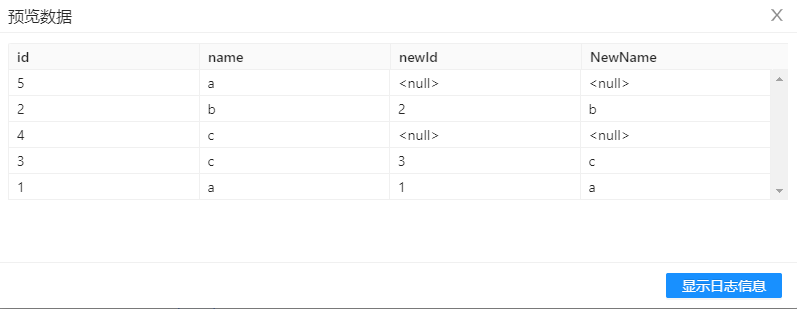
处理后的数据如下图所示:
案例数据
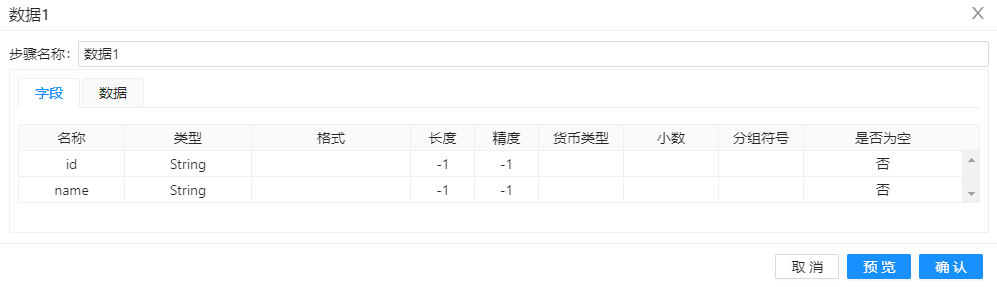
数据1来自“自定义常量组件”,包含id和name两个字段

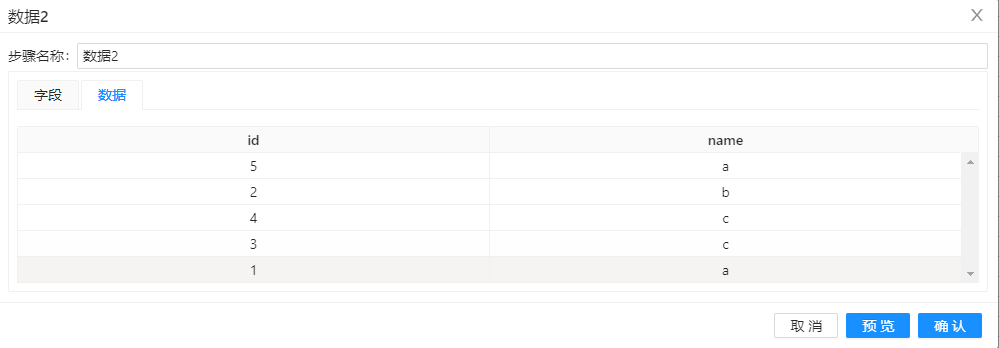
数据2也来自“自定义常量数据”,也包含id和name两个字段
通过流查询处理的输出结果为
案例操作
第一步、将自定义常量数据拖至画布,双击组件,步骤名称填入“数据1”,在“元数据”中先定义【id】、【name】两列并选择好数据类型,如下图所示:
选择“数据”标签,输入如下图所示的五条数据:
同上操作,再拖一个“自定义常量数据”组件,步骤名称填入“数据2”,在“元数据”中先定义【id】、【name】两列并选择好数据类型,如下图所示:

选择“数据”标签,输入如下图所示的五条数据:
第二步、将流查询拖至画布,并且把“数据1”和“数据2”步骤都连接到流查询组件,双击组件,按下图配置:
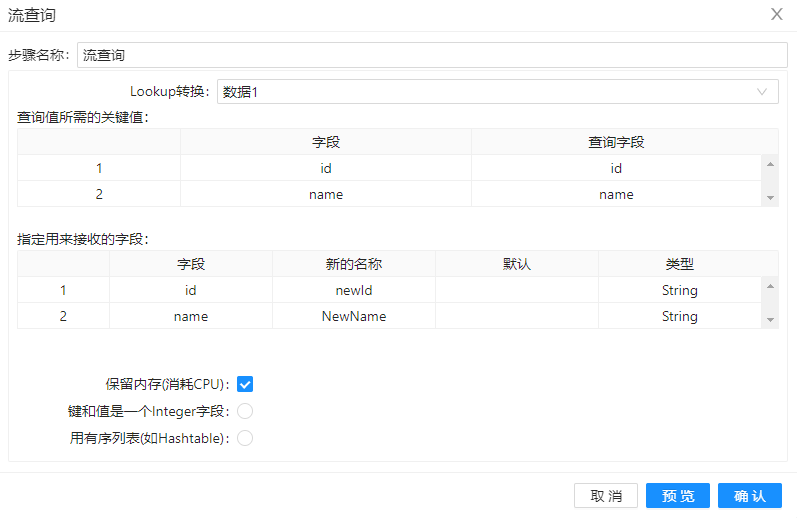
“Lookup 转换”选择从参照表也就是数据1步骤中查询数据,流查询步骤会根据设置的关键字段在参照表中查询对应的值【id】字段并将结果返回到新增的字段【newId】中去,【name】字段将结果返回到新增的字段【NewName】中去。
第三步、运行转换,结果如下图所示:
第四步、选中流查询组件,右击并选中预览查看数据。结果如下图所示:
可以看到,对于不匹配的行,新字段的值为NULL。对于匹配的行则输出对应的数据