Hadoop File Input(旧)
组件介绍
Hadoop File Input组件用于从各种存储Hadoop集群上不同的文本文件类型的读出的数据。最常用的格式包括由电子表格生成的逗号分隔值(CSV文件)和固定宽度的平面文件。
- 输入:存储在Hadoop集群上的文件
- 输出:处理过的文件
页面介绍
运行Hadoop File Input组件得到下图所示的界面:
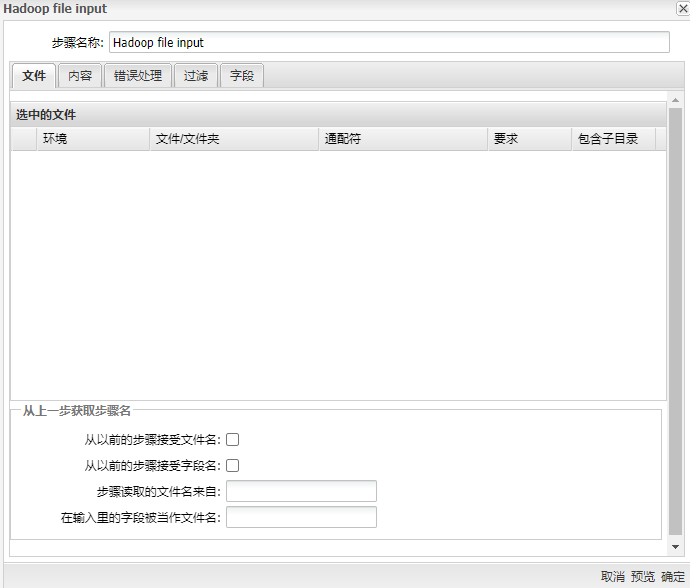

参数选项
Hadoop File Input组件页面包含如下选项:
| 选项 | 说明 | 样例值 |
|---|---|---|
| 步骤名称 | 在画布上指定Hadoop File Input步骤的唯一名称,可以自定义名称或保留默认名称。 | Hadoop File Input |
| 环境 | 表示可以在其上找到要输入的项目的文件系统或特定集群。选项是本地,静态,S3或 Hadoop群集名称。 本地:指定在“文件/文件夹”字段中指定的项目位于PDI客户端(勺子)本地的文件系统中。Static:指定在“文件/文件夹”字段中指定的项目应使用该字段中的路径名。如果您已经知道文件路径,并且想要将其复制并粘贴到窗口中,请使用此选项。S3:指定在“文件/文件夹”字段中指定的项目位于S3文件系统上的文件系统中。Hadoop群集名称:指定在“文件/文件夹”字段中指定的项目在指示的群集中。 | |
| 文件夹 | 指定要读取的文本文件的位置和/或名称。单击省略号(...)按钮以显示“打开文件”窗口并导航到文件或文件夹 | |
| 通配符(RegExp) | 在文件或目录字段中指定的目录中指定要用于选择文件的正则表达式 | |
| 要求 | 指示是否需要该文件 | |
| 包括子目录 | 指示是否包括子目录(子文件夹) | |
| 从以前的步骤接受文件名 | 选择复选框以从先前的步骤获取文件名 | |
| 从以前的步骤接受字段名 | 选择复选框以获取先前步骤中的字段信息 | |
| 步骤读取的文件名来自 | 输入从中读取文件名的步骤的名称 | |
| 在输入里的字段被当作文件名 | 文本文件输入将在此步骤中确定要使用的文件名 | |
| 文件类型 | 选择CSV或固定长度。基于此选择,当您单击**“字段**”选项卡中的“**获取字段”**时,PDI客户端将启动其他帮助程序GUI | N |
| 分隔符 | 一个或多个字符,用于在单行文本中分隔字段。通常,这是一个分号(;)或制表符 | ; |
| 文本限定符 | 某些字段可以用一对字符串括起来,以允许在字段中使用分隔符。附件字符串是可选的 | " |
| 在文本限定符里允许换行 | 在文本限定符里允许换行 | |
| 逃逸字符 | 如果数据中包含这些类型的字符,请指定一个或多个转义字符 | |
| 头部 | 选择文本文件是否具有标题行(文件的第一行) | |
| 头部数量 | 指定标题行出现的次数 | 1 |
| 尾部 | 选择文本文件是否具有页脚行(文件的最后几行) | |
| 尾部数量 | 指定页脚行出现的次数 | 1 |
| 包装行? | 选择是否使用已包装超过特定页面限制的数据行,页眉和页脚永远不会被包装 | |
| 以时间包装的行数 | 选择是否使用已包装超过特定页面限制的数据行。页眉和页脚永远不会被包装 | 1 |
| 分页布局(printout)? | 处理要在行式打印机上打印的文本处理要在行式打印机上打印的文本 | 勾选 |
| 每页记录行数 | 定位数据行 | 80 |
| 文档头部行 | 可以跳过介绍性文本使用文档标题行数可以跳过介绍性文本 | 0 |
| 没有空行 | 选择是否不想将空行发送到后续步骤选择是否不想将空行发送到后续步骤 | 勾选 |
| 在输出包括字段名? | 选择是否要将文件名包含在输出中选择是否要将文件名包含在输出中 | |
| 包含文件名的字段名称 | 输入包含文件名的字段的名称输入包含文件名的字段的名称 | |
| 输出包含行数? | 选择是否要让行号成为输出的一部分选择是否要让行号成为输出的一部分 | 勾选 |
| 行数字段名称 | 输入包含行号的字段的名称输入包含行号的字段的名称 | |
| 按文件取行号 | 可以是DOS,UNIX或混合的。UNIX文件中的行以换行符结尾。DOS文件中的行由回车符和换行符分隔。如果指定为混合,则不进行验证可以是DOS,UNIX或混合的。UNIX文件中的行以换行符结尾。DOS文件中的行由回车符和换行符分隔。如果指定为混合,则不进行验证 | |
| 编码方式 | 指定要使用的文本文件编码指定要使用的文本文件编码,保留空白以使用系统上的默认编码。要使用Unicode,请指定UTF-8或UTF-16。首次使用时,PDI客户端会在系统中搜索可用的编码保留空白以使用系统上的默认编码。要使用Unicode,请指定UTF-8或UTF-16。首次使用时,PDI客户端会在系统中搜索可用的编码 | |
| 记录数量限制 | 数量限制 | 0 |
| 解析日期时候是否严格要求? | 如果要��严格解析数据字段,请清除复选框。如果选择,则日期如1月32日变为2月1日 | 勾选 |
| 本地日期格式 | 此语言环境用于解析已完整编写的日期此语言环境用于解析已完整编写的日期 | zh_CN |
| 添加文件名 | 将文件名添加到结果文件名列表将文件名添加到结果文件名列表 | 勾选 |
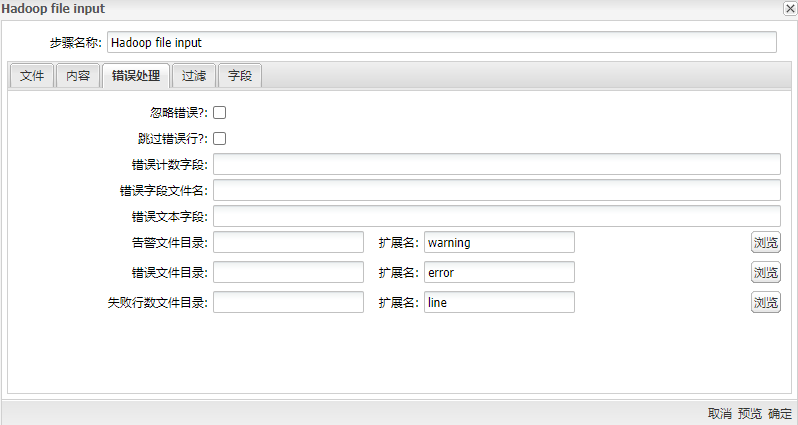
| 忽略错误? | 选择是否要在解析期间忽略错误 | |
| 跳过错误行? | 选择是否要跳过包含错误的行。您可以生成一个额外的文件,其中包含发生错误的行号。有错误的行不会被跳过。具有解析错误的字段为空 | |
| 错误计数字段 | 将字段添加到输出流行。该字段包含该行中的错误数 | |
| 错误字段文件名 | 将字段添加到输出流行。该字段包含发生错误的字段名称 | |
| 错误文本字段 | 将字段添加到输出流行。此字段包含已发生的解析错误的描述 | |
| 告警文件目录 | 生成警告时,会将它们放置在此目录中。该文件的名称为<警告目录> /文件名。<日期时间>。<警告扩展名> | |
| 错误文件目录 | 发生错误时,它们将放置在此目录中。文件的名称为<错误文件目录> /文件名。<日期时间>。<错误文件扩展名> | |
| 失败行数文件目录 | 当某行发生解析错误时,该行号将放置在此目录中。该文件的名称为<错误线目录> /文件名。<日期时间>。<错误线扩展名> | |
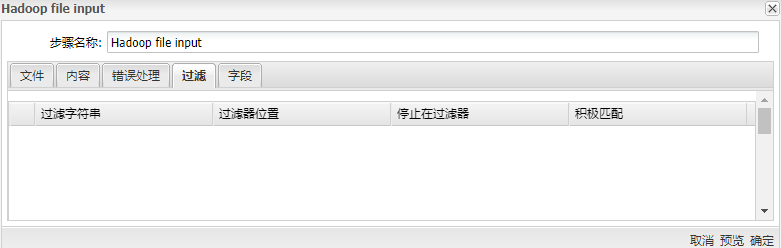
| 筛选字符串 | 要搜索的字符串 | |
| 过滤器位置 | 过滤器字符串必须在行中放置的位置。零('0')是该行中的第一个位置�。如果指定的值小于零('0'),则会在整个字符串中搜索过滤器字符串 | |
| 停止在过滤器 | 如果要在遇到过滤器字符串时停止处理当前文本文件,请在此处输入 “ Y” | |
| 积极匹配 | 启用后将滤波器变为正模式。仅匹配此过滤器的行将通过。负过滤器优先,并立即被丢弃 |
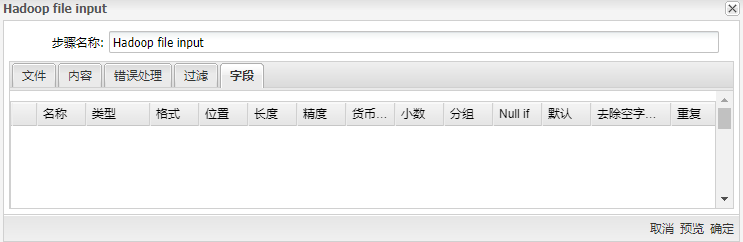
字段表
组件底部表格为字段表,右击选择“获取字段”,组件可根据当前指定设置从源文件获取相应内容填充字段表。该表包含以下列:
| 列名 | 说明 | 样例值 |
|---|---|---|
| 名称 | 字段名称 | |
| 类型 | 字段类型,可以是String、Date或Number等类型。 | |
| 格式 | 用于转换原始字段格式的可选掩码。 | |
| 位置 | 处理“固定”文件类型时需要该位置。它是从零开始的,因此第一个字符从位置“ 0”开始。 | |
| 长度 | 字段的长度取决于以下字段类型:Number:数字中有效数字的总数。String:字符串的总长度。Date:字符串的打印输出长度。 | |
| 精度 | 数字类型字段的浮点位数。 | |
| 货币类型 | 用于表示货币的符号(例如¥或$)。 | |
| 小数 | 小数点可以是“.”或“,”(例如5,000.0或5.000,0)。 | |
| 分组 | 分组可以使“.”或“,”(例如5,000.0或5.000,0)。 | |
| Null if | 将此值�视为空 | |
| 默认 | 如果未指定文本文件中的字段(空),则为默认值 | |
| 去除空字符串 | 在处理之前修剪类型。您可以指定以下选项之一:不去掉空格 去掉左空格 去掉右空格 去掉左右空格 | |
| 重复 | 如果该行中的对应值为空,则从上次不为空(Y / N)开始重复该值 |