模糊匹配
组件介绍
模糊匹配组件使用重复检测算法来查找可能匹配的字符串,该算法计算两个数据流的相似性。 此步骤将匹配值作为由用户定义的最小值或最大值指定的单独列表返回。
- 输入:数据信息(表,数据库,文件等)输入内容
- 输出:匹配查询成绩输出数据信息
页面介绍
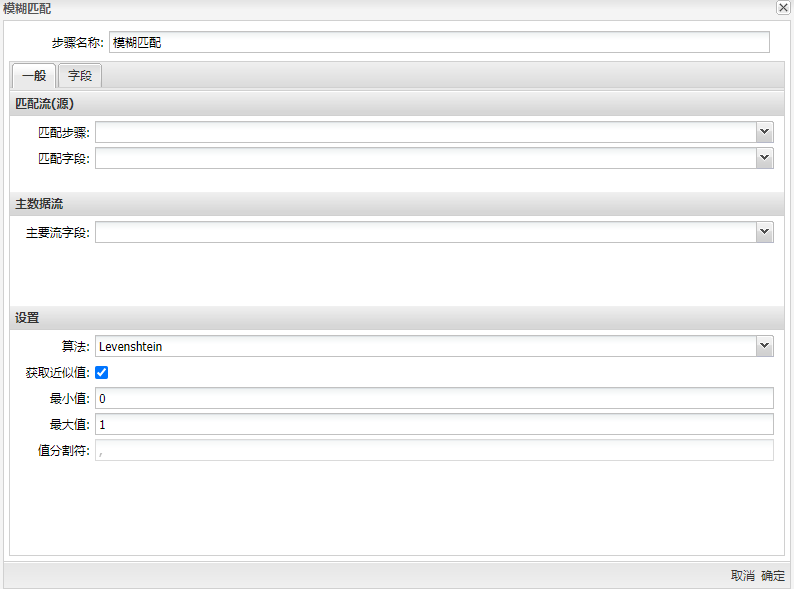
双击模糊匹配组件得到下图所示的界面:
参数选项
模糊匹配组件页面包含如下选项:
| 选项 | 说明 | 样例值 |
|---|---|---|
| 步骤名称 | 步骤的唯一名称,可以自定义名称或保留默认名称 | 模糊匹配 |
| 匹配步骤 | 进行匹配的上一步组件信息 | |
| 匹配字段 | 上一步组件匹配的字段信息 | |
| 主数据流(设置) | 算法:标识要使用的字符串匹配算法-选项包括Levenshtein,Damerau-Levenshtein,Needleman Wunsch,Jaro,Jaro Winkler,成对字母相似度,Metaphone,Double Metaphone,SoundEx或Refined SoundEx; | |
| 大小写敏感:根据使用大写和小写字母来确定流是否可以不同-仅适用于Levenshtein算法; | ||
| 获取近似值:选中后,将返回具有最高相似度得分的单个结果,未选中时,将满足最小和最大值设置的所有匹配项作为单独的列表返回,并用值分隔符分隔; | ||
| 最小值:确定最低的相似度得分; | ||
| 最大值:确定最大的相似度得分; | ||
| 值分隔符:标识分隔匹配项的字符串。 仅适用于特定算法,并且未选中“获取更接近的值”选项 | ||
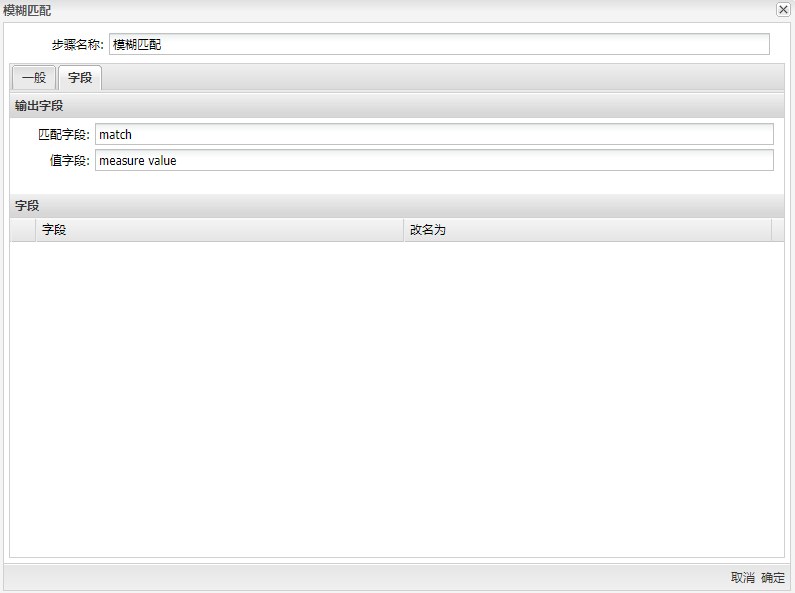
| 输出字段 | 匹配字段:定义包含比较值的列的名称; | |
| 值字段:定义要为其返回值的相似性分数; | ||
| 字段 | 输出的字段信息 |
使用案例
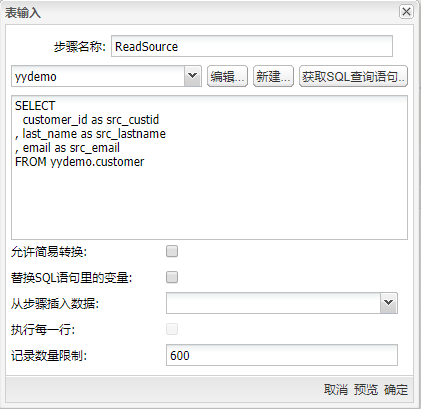
将表输入组件拖至画布,双击组件,步骤名称填入“ReadSource”,并在弹出的对话框中选择在 Uniplore 中保存好的数据库连接,单击获取SQL查询语句,在对应的文本框中即可获得对应表的查询。当然,也可以在文本框中编写自定义SQL查询语句。获取需要的客户号、客户姓氏和邮件并将字段名更改以便后期区分,将使用【last_name】字段作为模糊匹配字段,使用【e-mail】字段作为参照字段,配置如下图所示:
再将表输入组件拖至画布,双击组件,步骤名称填入“Lkp_LastName”,在弹出的对话框中选择在 Uniplore 中保存好的数据库连接,单击获取QL查询语句,在对应的文本框中即可获得对应表的查询。当然,也可以在文本框中编写自定义SQL查询语句。获取需要的客户号和客户姓氏并将字段名更改以便后期区分,配置如下图所��示:
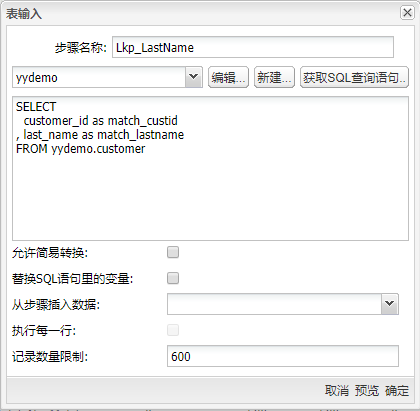
将模糊匹配组件拖至画布,两个表输入组件与其连接,双击组件,步骤名称填入“MatchLastName”,填入之前准备好的匹配字段和主要流字段,并使用“Jaro Winkler”算法,设置的最小相似度为 0.8。“设置”栏里的选项,主要取决于选择的算法。如果你选择的是“Soundex”或“Metaphone”算法等,是没有设置项,“区分大小写”选项也只适用于“Levenshtein”算法。 具体配置如下图:
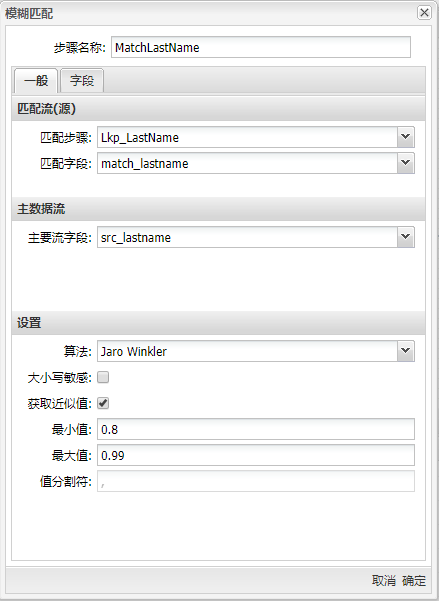
设置中其他的一些选项都是用来控制匹配结果的。这里的“获取近似值”选项很重要,这个选项可以只返回一个最相似的数值。如果不选中这个选项,就会返回相似度在最小值和最大值之间的多个数值,多个值使用指定的分隔符分开。 选择“字段”标签,设置查询流里需要的其他字段,填入匹配字段与值字段,如下图所示:
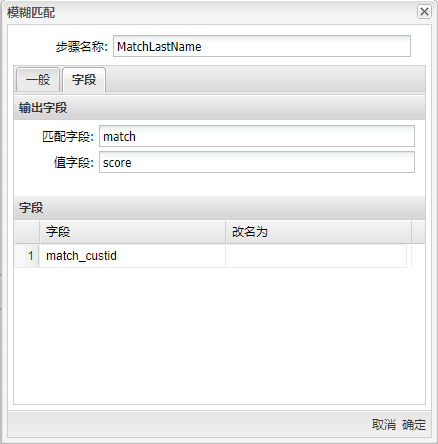
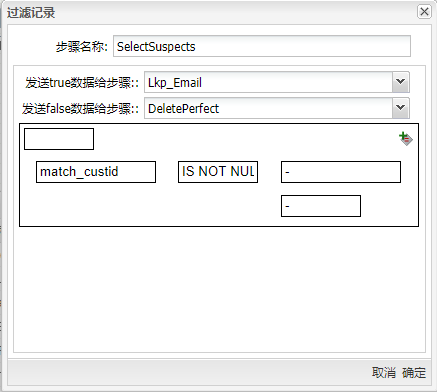
在“字段”标签下可以设置匹配列的列名。但因为有多个匹配的数值,以及这些数值也没有可以参照的主键或引用,所以这个结果对后续处理没有太大作用。对于排重工作来说,不但要找到相似的数值,还要知道这些数值属于哪条记录。所以最好选中“获取近似值”选项。这个选项只返回相似度最高的数值,另外还返回这个数值所在记录的其他字段。 在这个例子里,模糊��匹配是第一个步骤。在现实情况中,这个步骤的前面可能还有一些使用正则表达式匹配等技术做数据清洗的步骤。例如,一个数据源文件只包含了一个单一的name字段,这是人的全名。如果是美国人名,这时就需要使用正则表达式步骤把这个字段拆分成“first name”、“middle initial”和“last name”字段,如果是其他国家的人名,可能有其他的拆分方法。 将过滤记录组件拖至画布,让模糊匹配步骤与其连接,再将空操作(什么也不做)组件拖至画布,并将步骤名改为“DeletePerfect”,将数据库查询组件拖至画布,步骤名改为“Lkp_Email”;然后将**“过滤记录”**连接这两个步骤以便接下来的配置,双击组件,步骤名称改为“SelectSuspecs”,选择数据发送的步骤和条件,具体如下图所示:
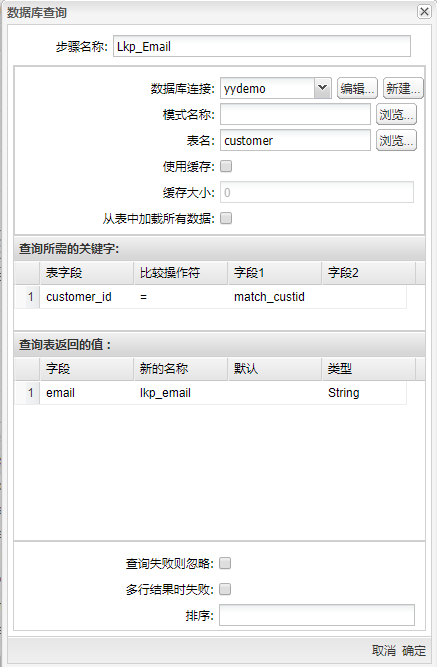
双击Lkp_Email步骤,在弹出的对话框中选择在 Uniplore 中保存好的数据库连接,选择好要查询的表名、所需的关键字条件和要返回的值,具体如下图所示:
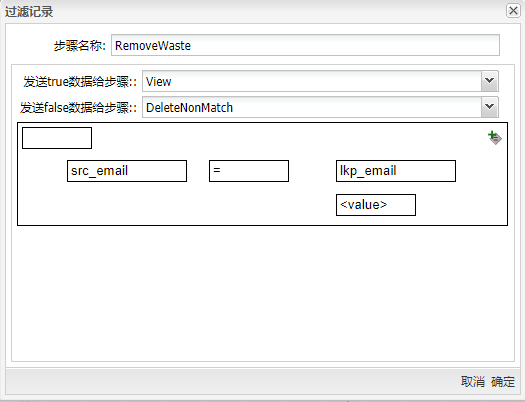
再进行一次过滤,将过滤记录组件拖至画布,让数据库查询步骤与其连接,再将空操作(什么也不做)组件两次拖至画布,并分布将步骤名改为“View”和“DeleteNonMatch”;然后将过滤记录连接这两个步骤以便接下来的配置,双击组件,步骤名称改为“RemoveWaste”,选择数据发送的步骤和条件,具体如��下图所示:
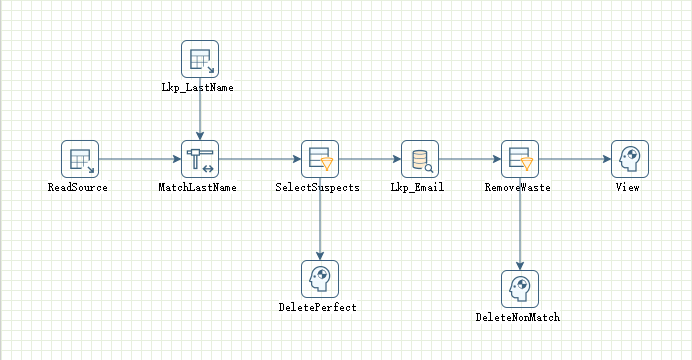
记录是“可能的”重复记录,尽管在这个例子里,可以很肯定说这两个记录是一个人。但实际情况中也有可能是一对夫妻共享了同一个电子邮箱地址。还有更糟的情况,例如,两个记录指向同一个人,但两个地址都是有效的,一个是街道地址,一个是邮局邮箱地址,或者一个人有两个电子邮箱地址等等情况。 按顺序连接,若提示选择步骤,依然选择主输出步骤。完整转换如下图所示:
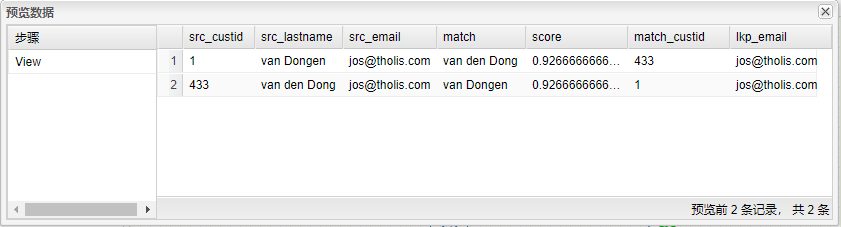
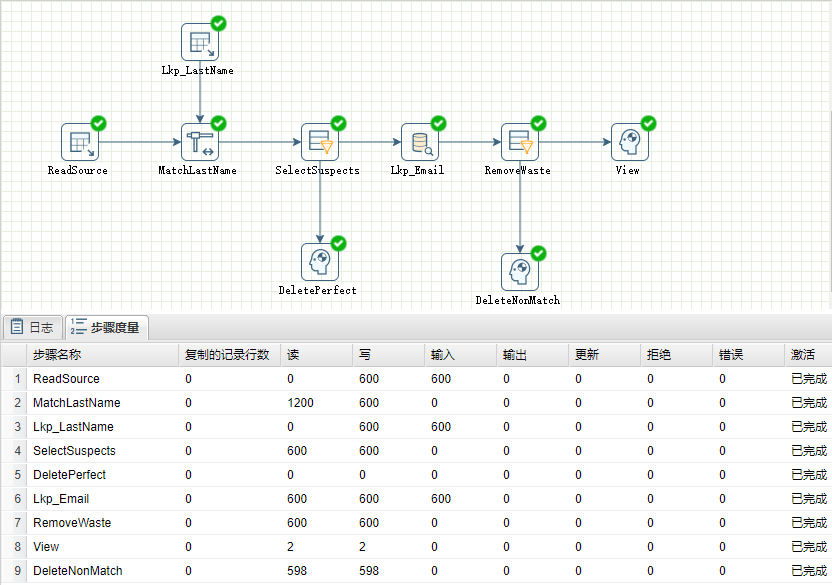
运行转换,结果如下图所示:
选中DeletePerfect步骤,右击并选中预览查看没有匹配到姓氏相近的数据信息。结果如下图所示:
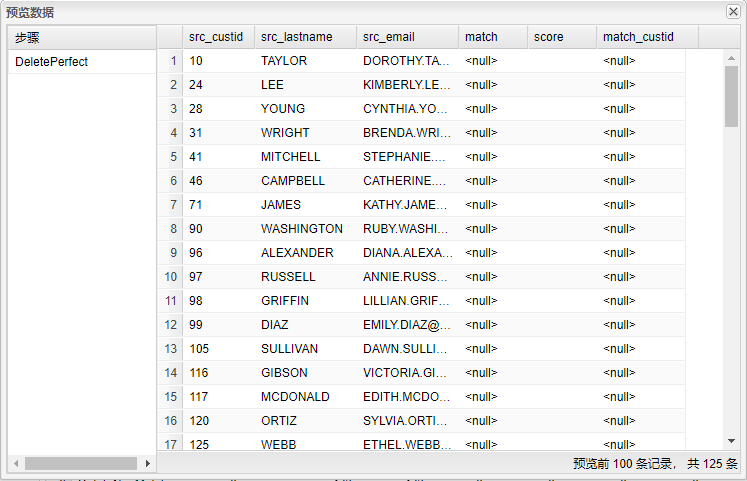
选中DeleteNonMatch步骤,右击并选中预览查看通过匹配后姓氏相近,但邮件不相等的数据信息。结果如下图所示:
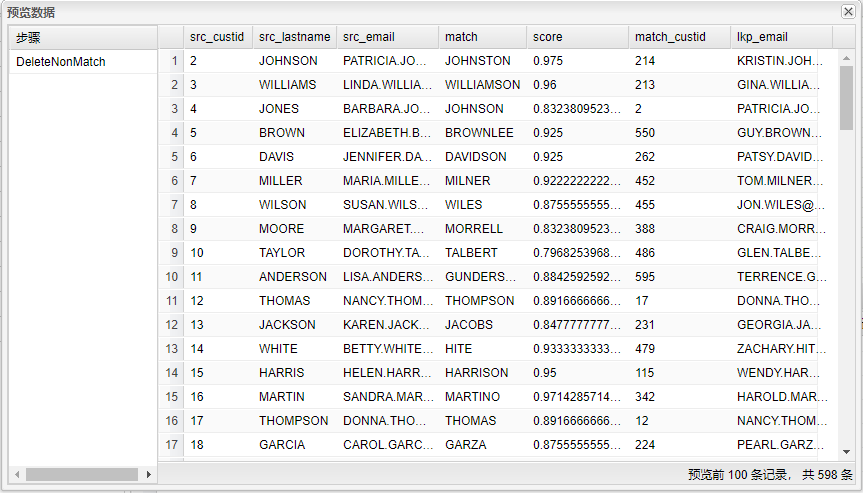
选中View步骤,右击并选中预览查看通过匹配后姓氏相近、邮件相等的数据信息。结�果如下图所示: