Data Vault 管理数据集成案例
实验目录
-
熟悉 Sakila
-
了解 Data Vault(DV)模型
-
熟悉数据集市
实验原理
Sakila
Sakila 是 MySQL 中的一个示例数据库(Sample Database),提供了一个标准的方案,可用于自学,写书,教程,文章以及示例等。关于 Sakila ,请参考 Sakila数据集介绍 。
数据仓库
数据仓库即 Data Warehouse ,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。它是单个数据存储,出于分析性报告和决策支持目的而创建。 为需要业务智能的企业,提供指导业务流程改进、监视时间、成本、质量以及控制。
简单来说,DW 的本质也是一个数据库,但是,他是针对数据分析的业务场景而设定的。传统的数据库,是为了支撑实际业务如商城而建立的,针对查询量小(单条数据如查询用户信息)的业务场景。数据仓库是为了做数据分析的,针对的是查询量大(每次查询几万甚至几百万条数据)的业务场景。
Data Vault
Data Vault (DV )是一种建模方法。DV 是面向细节,可追踪历史的,它是一组有连接关系的规范化的表的集合。这些表可以支持一个或多个业务功能,它是一种综合了第三范式(3NF)和星型模型优点的建模方法。其设计理念是要满足企业对灵活性、可扩展性、一致性和对需求的适应性要求,它是一种专为企业级数据仓库量身定制的建模方式该模型保留所有历史数据。
简单来说,DV 可以理解成一个临时存储空间。该空间存储来自源数据库,经过处理的数据。DV 是源数据库的数据到数据仓库的一个中介。
Data Vault 的组成部分
下面的部分描述了 Data Vault 模型的主要组成部分:中心表、链接表和附属表,以及它们之间的交互。还说明了Data Vault模型的一般特点和处理过程。
中心表
中心表是包含业务主键的表,每个业务主键代表一个唯一实体。常见的中心表的例子有客户、雇员、产品、建筑物、资源和假期。
中心表(每一类实体都有自己的中心表)用来保存一个组织内的每个实体的业务主键。除一些元数据外,业务主键是中心表包含的所有内容。Data Vault另一个吸引人的特点就是中心表和源是互相独立的。当一个业务主键被用在多个系统时,业务主键也只保留一份,其他的Data Vault的组件都是连接到这一个业务主键。这也就意味着企业数据都集成到了一起。
下表列出了中心表中应该包含的列(所有字段都需要,不需要其他字段)。
| 属性 | 描述 |
|---|---|
| 主键 | 系统生成的代理键,供内部使用 |
| 业务主键 | 唯一标识的业务单元,用于已知业务的源系统 |
| Load DTS | 数据第一次加载到EDW时系统生成的时间戳 |
| Record source | 定义了数据来源(例如源系统或表) |
下表显示一个中心表 hub_customer 的例子
| id | BusinessKey | Load_DTS | Record_Source |
|---|---|---|---|
| 1 | cst_24125670 | 12/17/2009-03:05:04 | sales.cust |
| 2 | cst_24125894 | 12/17/2009-03:05:04 | sales.cust |
| 3 | cst_67904567 | 12/17/2009-03:00:00 | mkt.customer |
| 4 | cst_67904568 | 12/17/2009-03:00:00 | mkt.customer |
注意表里的数据来源于两个系统,sales 和 mkt。从Record_Source字段可以看出,客户cst_24125670和cst_24125894 最初存在于 sales 系统,客户 cst_67904567 和 cst_67904568 最初存在于mkt系统。这些客户 可能也在其他系统里,因为中心表的业务键是唯一的,所以从这里不能看出这些客户还在哪个系统里。
链接表
Data Vault模型的第二个构成部分就是链接表。链接表是中心表之间的链接。一个链接表就意味着两个(或多个)中心表之间有关联。一个链接通常是一个外键,它代表着一种业务关联,如业务活动、业务主键之间的事务等。
下表列出了链接表中的所有字段(所有字段都需要,不需要其他��字段)。下表是一个链接表的例子。
| 属性 | 描述 |
|---|---|
| 主键 | 系统生成的代理键,供内部使用 |
| 外键 | 中心表的代理键(外键),关系在链接表中定义 |
| Load DTS | 数据第一次加载到EDW时系统生成的时间戳 |
| Record source | 定义了数据来源(例如源系统或表) |
下表是一个链接表的例子

和第三范式的数据模型不同的是,Data Vault 模型完全忽略了关系的关联类型(1:N;N:M;…)。在 Data Vault 里,每个关系都是 N:M 方式关联(多对多)。这给模型带来了更大的灵活性;无论数据在不同的源系统中是什么关系,都可以保存在 Data Vault 模型中。
在链接表中,所有中心表外键的组合也可以形成一个唯一的键,这个唯一键我们通常称为链接表的业务主键,尽管在技术上看不一定百分之百准确。
附属表
Data Vault 模型使用附属表来保存中心表和链接表的属性,包括所有历史变化数据。一个附属表总有一个(且唯一一个)外键引用到中心表或链接表。
下表列出了附属表要包含的所有字段(所有字段都需要,不需要其他字段)。下表是一个附属表的例子。
| 属性 | 描述 |
|---|---|
| 主键 | 系统生成的代理键,供内部使用 |
| 外键 | 中心表或链接表的外键,由附属表中的行定�义 |
| Load DTS | 数据第一次加载到EDW时系统生成的时间戳 |
| Load End DTS | 数据失效时的时间戳,时间戳已被改变 |
| Record source | 定义了数据来源(例如源系统或表) |
| 属性{1…N} | 属性自身 |
在 Data Vault 模型的标准定义里,附属表的主键应该是附属表里参照到中心表或链接表的外键字段和 Load DTS 字段的组合。尽管这个定义是正确的,从技术角度考虑,我们最好还是增加一个只有一列的代理主键。使用只有一个列的代理主键执行 UPDATE 等 SQL 语句比多列的主键要容易(可能也会更快)。另外,把外键列和 Load_DTS 列联合建立唯一索引,也是一个好的习惯。
下表是一个附属表的例子。
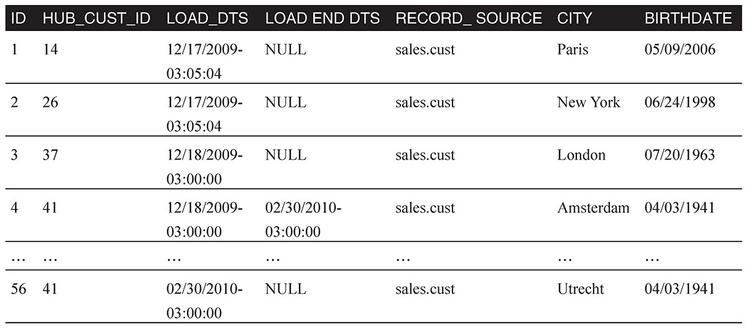
表中的数据包含客户的两个属性:City 和 Birthdate 。如果源系统(sales.cust)中客户的一个属性发生了变化,附属表中就会增加一行,原来的一行的截止日期字段也会被更新。ID为4和56的数据行描述了 cust_id 是 41 的同一个客户在不同时间的属性。
中心表和链接表都可以有多个附属表,事实上,我们也推荐多个附属表。考虑一下两个源系统 sales 和 marketing 中都包括了客户数据的情况。在两个源系统中同一个客户都有同一个主键(你比较幸运)。在这种情况下,最好为每个源系统都创建一个附属表。除了源系统之外还有其他一些原因需要拆分附属表,如属性的变化频率(变化快的属性和变化慢的属性)和数据类型。
构建 DV 模型的步骤
构建 Data Vault 模型的几个基本步骤包括:
(1)中心表建模,关注业务主键。
(2)链接表建模,寻找链接表和中心表之间的事务关系(使用外键)。在给中心表和链接表建模过程中,更便于你了解公司的组织和业务模式。
(3)附属表建模,提供上下文类的信息,以完成 Data Vault 建模。
将 Sakila 的例子转换成 Data Vault 模型
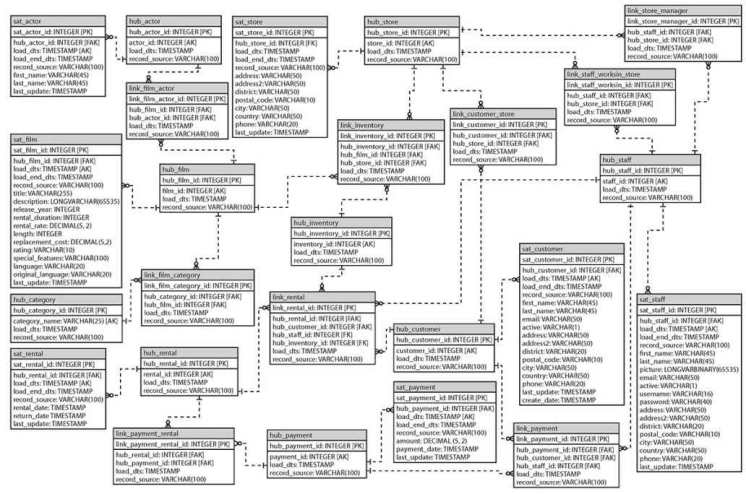
本章将 sakila 数据库转换为 Data Vault 模型,最终转换为的 Data Vault 模型如下图。从图中可看出,链接表连接实体与实体,而属性表与相应的实体表链接,就构成了 Sakila 的 DV 模型。
中心表
本例中,下面的几个实体:actor、category、customer、film、staf f和 store 要转换成中心表是比较明显的。也有几个不太明显的实体,如 inventory、payment 和 rental,它们可以作为链接表(因为它们的事务特性)。但如果把这些表转换为链接表,就会在链接表之间生成新的链接表,就是所谓的链接表的链接表。我们不推荐使用这种结构,所以上面这些实体将作为中心表。最后要考虑一些地理信息表,如 address、city、country 和 language 表是否要作为中心表。sakila 的开发人员把这些表都作为独立的实体。但对你��来说,这些表都是参考数据。对你的业务来说(DVD租赁),这些表不能算是中心表实体(在后面会看到,这些表实际是附属表)。
下表列出了所有的中心表。
| 实体 | 业务主键 |
|---|---|
| hub_actor | actor_id |
| hub_category | category_name |
| hub_customer | customer_id |
| hub_film | film_id |
| hub_inventory | inventory_id |
| hub_payment | payment_id |
| hub_rental | rental_id |
| hub_staff | staff_id |
| hub_store | store_id |
中心表、链接表、附属表的选择不是绝对的。如果想把 address、city 和 country 作为实体表,你就可以把它们转换为实体表。你将发现 Data Vault 模型很灵活。
链接表
选完了中心表,就要选择链接表。这意味着你要分析中心表的事务和它们之间的关系。在源系统里的外键非常有助于这一步。事务类型的表比较容易找到:payment 和 rental。事务类型的表是 Sakila 的业务核心。所以,即使payment 和 rental 已经在前一个步骤中被选为中心表,考虑到它们的事务特性,我们也要在这一步中把它们选 为链接表。其他的链接表就是关系类型的表,一个顾客通常只访问一个商店(离他最近的商店),在 sakila 源系统中,customer 表有一个外键 store_id 来表示这种关系。就是一个典型的链接的例子,来说明 Data Vault 模型和普通的数据模型的区别。源数据模型(sakila)定义了一种一对多的关系(一个客户有且仅一个商店)。Data Valut 模型定义了每个关系都是多��对多的关系(一个顾客可以有一个或多个商店)。所以需要一个表示关系的表 link_customer_store。
下表为全部链接表见表
| 链接表 | 被链接的中心表 |
|---|---|
| link_film_actor | hub_film, hub_actor |
| link_film_category | hub_film, hub_category |
| link_customer_store | hub_customer, hub_store |
| link_inventory | hub_inventory, hub_film, hub_store |
| link_payment | hub_payment, hub_customer, hub_staff |
| link_payment_rental | hub_payment, hub_rental |
| link_rental | hub_customer, hub_inventory, hub_staff |
| link_staff_worksin_store | hub_staff, hub_store |
| link_store_manager | hub_staff, hub_store |
在 sakila 数据库里,store 表里包含一个外键参照到staff表(manager_staff_id),说明了商店的经理。在 staff 表里也有一个外键参照到store表(store_id),说明这个员工属于哪个商店。这两个外键每个都转换成一个链接hub_staff 和 hub_store 表的链接表;这两个链接表都是多对多关系的表,所以看上去它们是一样的。
附属表
中心表和链接表构成数据的框架,如下图所示。
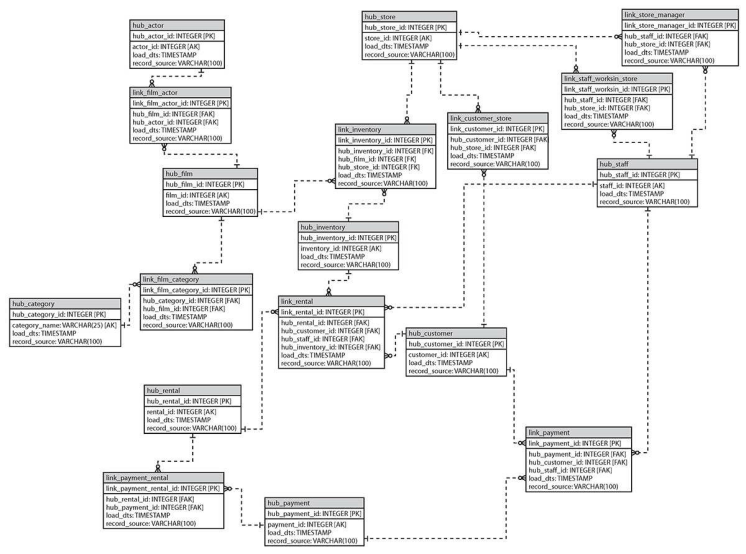
附属表将Data Vault数据模型补充完整,并为中心表和链接表补充属性。用在 Data Vault 模型里的所有源系统中的表的属性,最终都要放到 Data Vault 模型中。
附属表的定义相当简单,所以我们直接来看下表列出的所有附属表��。
| 附属表 | 描述 |
|---|---|
| sat_actor | hub_actor |
| sat_film | hub_film |
| sat_customer | hub_customer |
| sat_payment | hub_payment |
| sat_rental | hub_rental |
| sat_staff | hub_staff |
| sat_store | hub_store |
实验步骤
加载 Data Vault 模型
本节介绍将 Sakila 数据加载到 Data Vault 模型中
导入 Sakila 数据
在加载 DV 模型之前,需要先准备数据。首先将 SQL 文件 sakila-schema.sql 通过 source 命令导入数据库,目的是创建 Sakila 所需要的表;接着将 SQL 文件 sakila-data.sql 通过 source 命令导入数据库,目的是加载数据。
安装 Sakila Data Vault
将 SQL 文件 sakila_data_vault_schema_edit.sql 通过 source 命令导入数据库,目的是创建 DV 所需要的表。
加载中心表
本节介绍将 sakila 中的表 actor 加载到 DV 模型的中心表中,以加载 actor 表为例,其他转换与此类似。转换总览如下
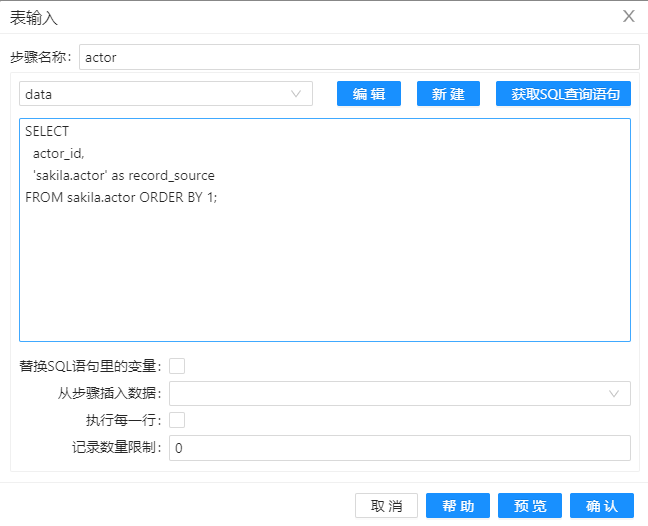
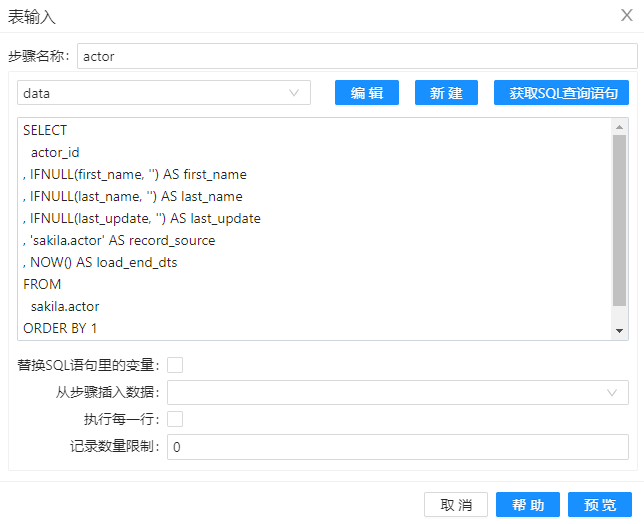
1、创建转换 hub_actor,并拖动两个 “表输入”组件到工作区。第一个组件“表输入”按下图配置。在下图的 SQL 语句中,要用 ORDER BY 1 将查询的到的结果排序,利于后面的组件“记录集连接”处理。
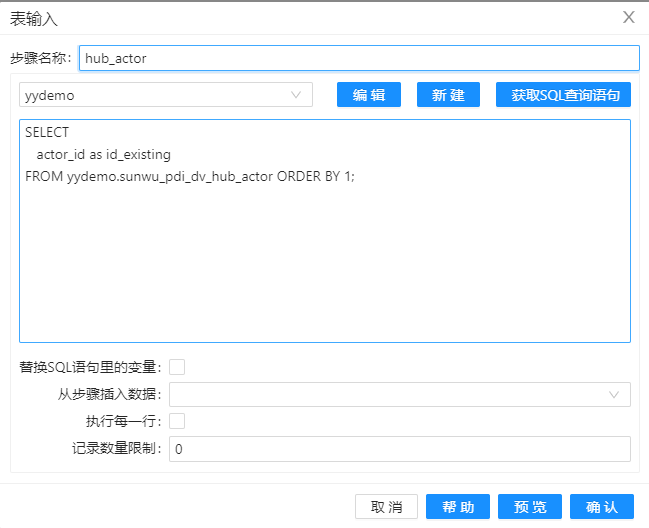
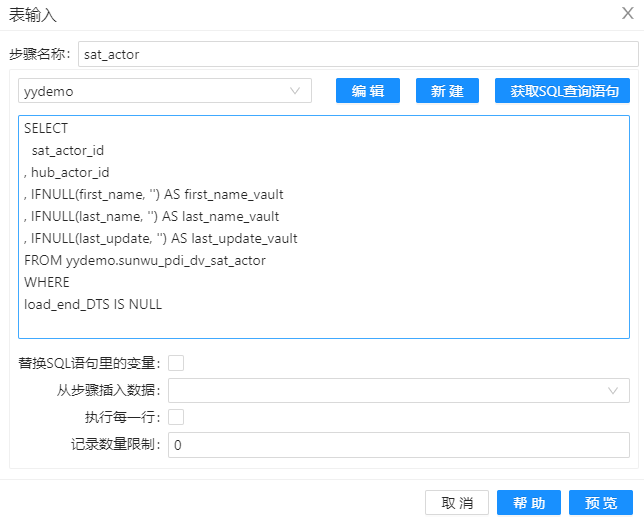
第二个组件“表输入”做下图的配置。与第一个组件“表输入”一样,也需要在 SQL 查询的时候使用 ORDER BY 排序。 在 SQL 语句中,要用 OR
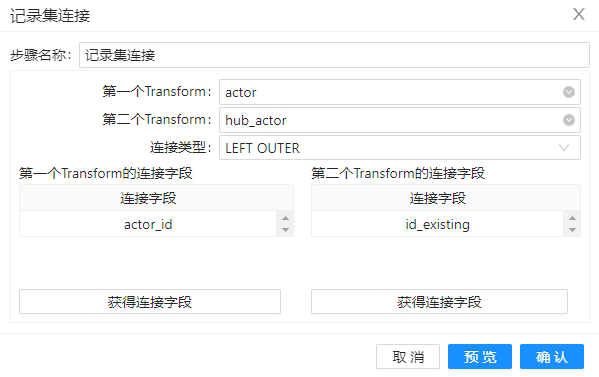
2、拖动组件“记录集连接”到工作区,将从 Sakila 查询到的数据、DV 模型中查询到的数据合并(左连接),为下一步的筛选数据做准备。组件的配置如下图
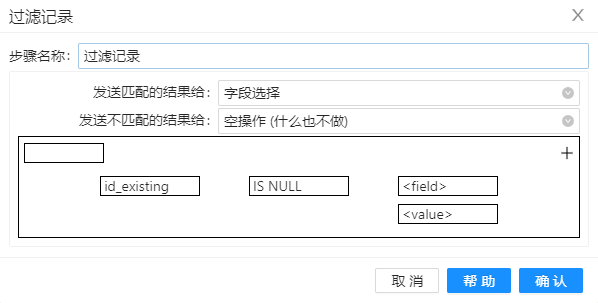
3、拖过组件“过滤记录”到工作区,过滤掉 DV 模型中已存在的数据,即增量添加。组件的配置如下图。
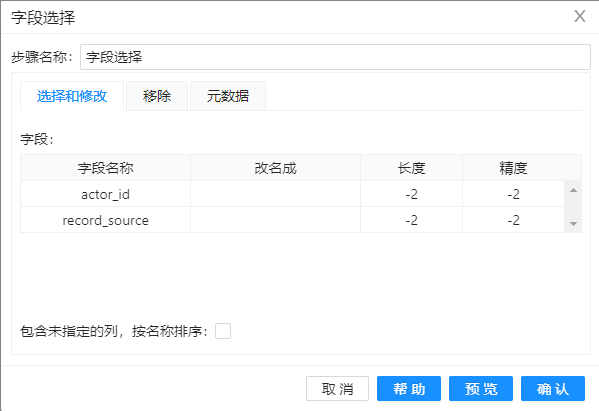
4、拖动组件”字段选择“到工作区,并按下图配置,去掉不需要的字段。
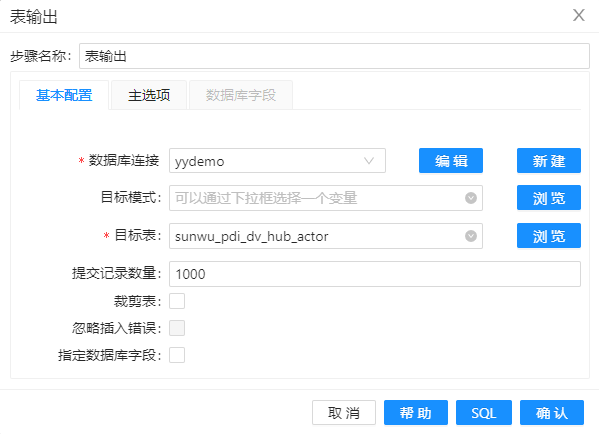
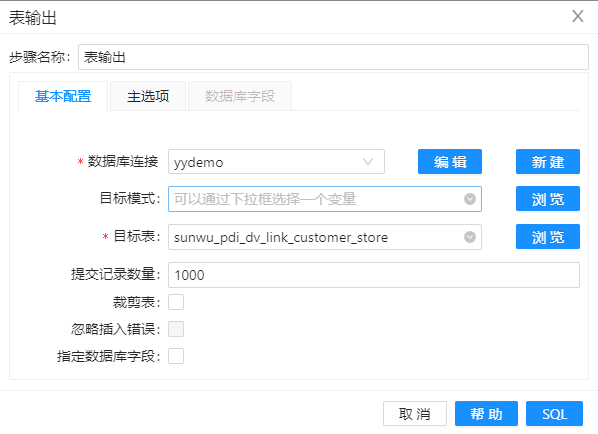
5、最后,拖动组件“表输出”组件到工作区,将处理后的数据插入 DV 模型的表 hub_actor 中,组件配置如下图。
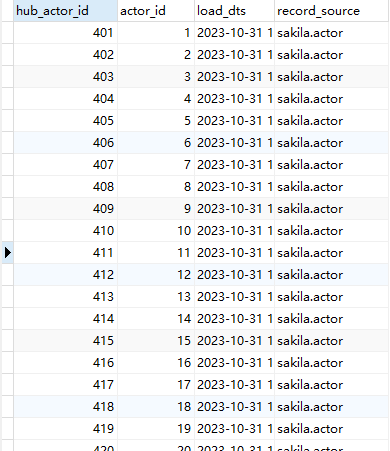
6、运行转换,即可将数据加载到 DV 模型的 hub_actor 表中。通过 navicat 工具,可查看数据库中部分数据如下。
加载链接表
本节介绍加载链接表,以加载表 link_customer_store 为例,其他转换与此类似。转换总览如下图。
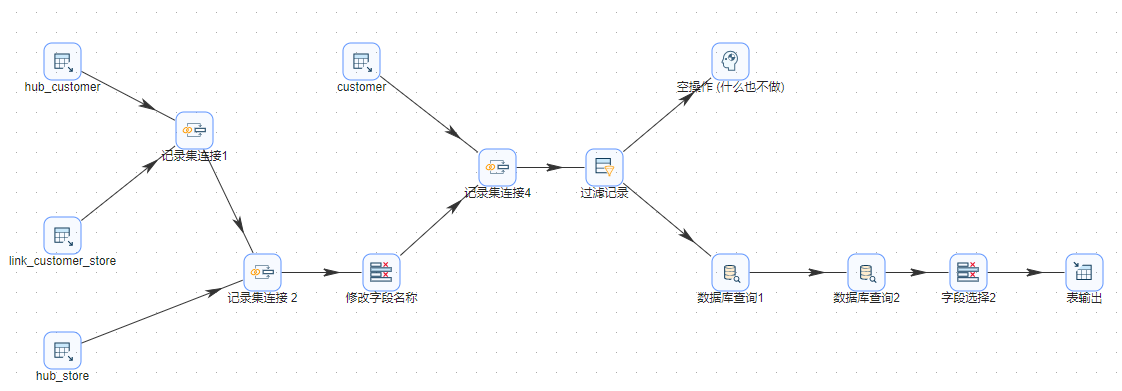
1、拖动四个组件“表输入"组件到工作区,分屏命名为“hub_customer”、“link_customer_store”、“hub_store”和“customer”,其配置分屏如下图。通过这些组件,我们将加载数据库中的数据到组件中。
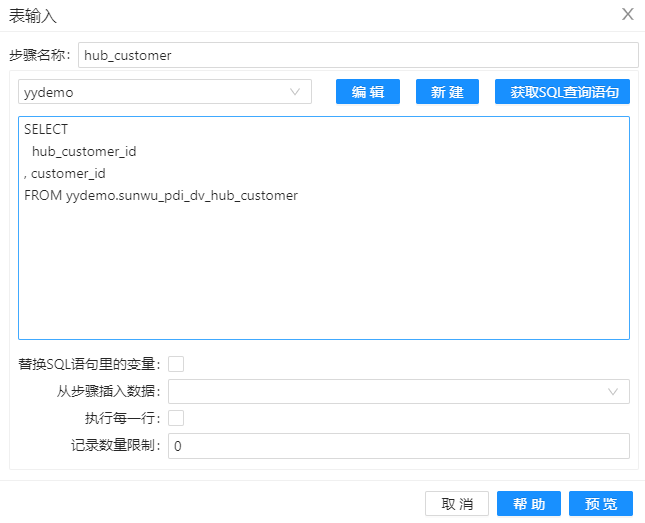
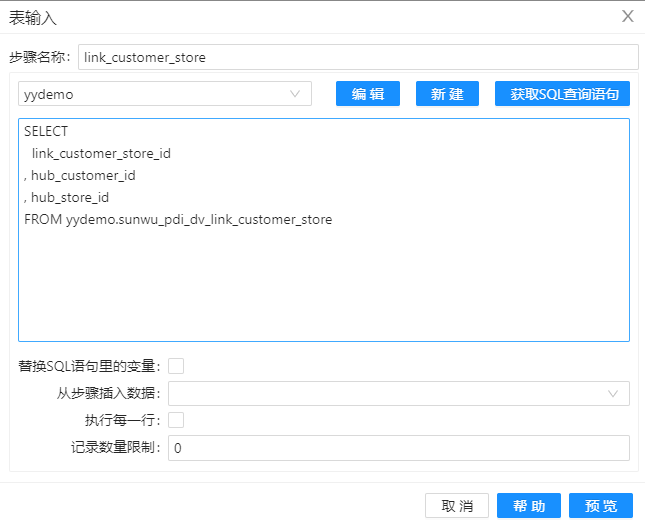
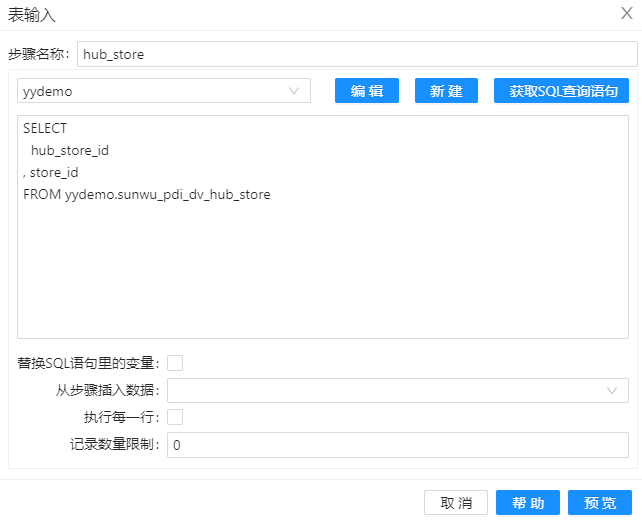
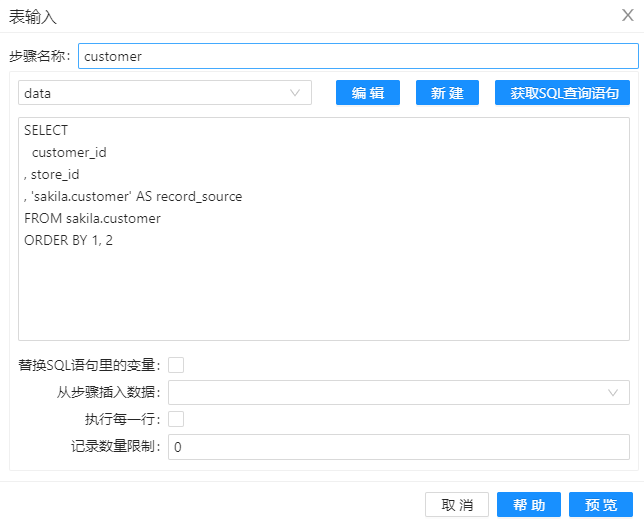
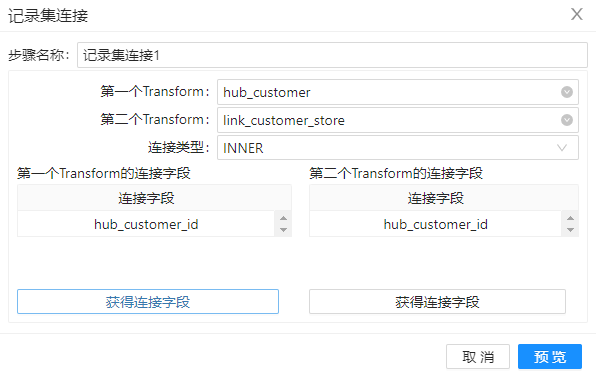
2、拖动组件“记录集连接”到工作区,并命名为”记录集连接1“,通过该组件,将表”hub_customer“和”link_customer_store“的数据通过关键字“hub_customer_id”连接起来,其配置如下图。
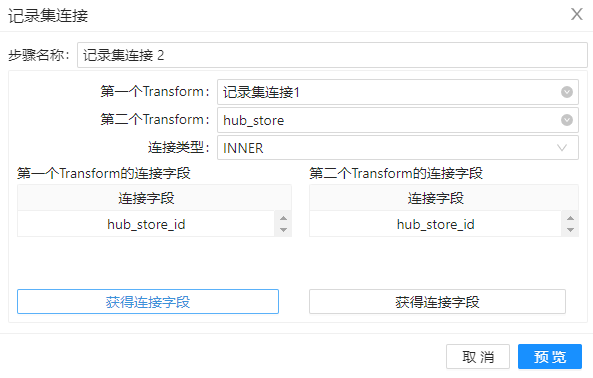
3、拖动组件“记录集连接”到工作区,并命名为”记录集连接2“,通过该组件,将步骤 2 所得到的的数据和”hub_store“的数据通过关键字“hub_store_id”连接起来,其配置如下图。
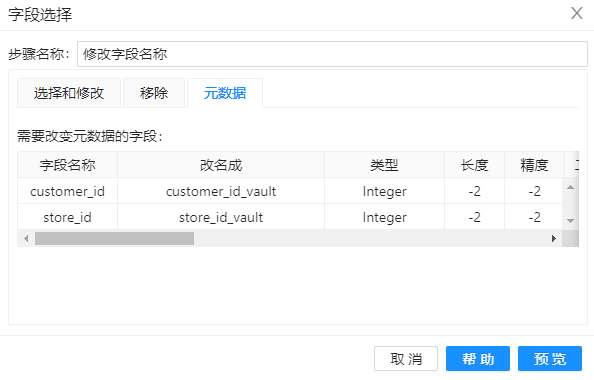
4、拖动组件“字段选择”到工作区,并重命名为“修改字段名称”,将步骤 3 得到的数据字段重命名,其配置如下图。如果所示,将字段“customer_id”重命名为“customer_id_vault”,字段“store_id”重命名为“store_id_vault”。
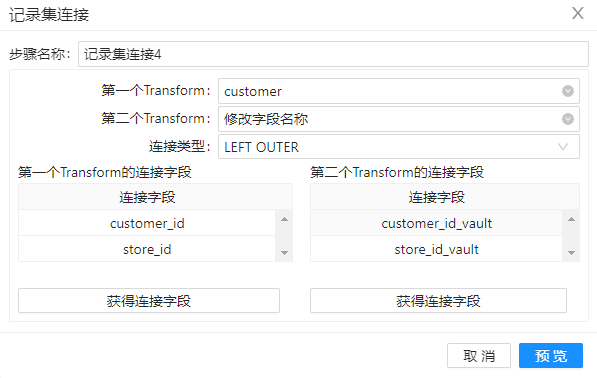
5、拖动组件“记录集连接”到工作区,并重命名为“记录集连接4”,将步骤 4 得到的数据与组件”customer“的到的数据进行左连接,配置如下图所示。
6、拖动组件“过滤记录”到工作区,配置如下图。通过该步骤,可以将存在于 DV 模型中的数据过滤掉,只添加数据库“customer”中参数的新数据。
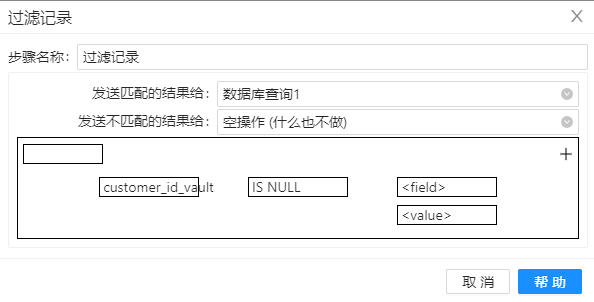
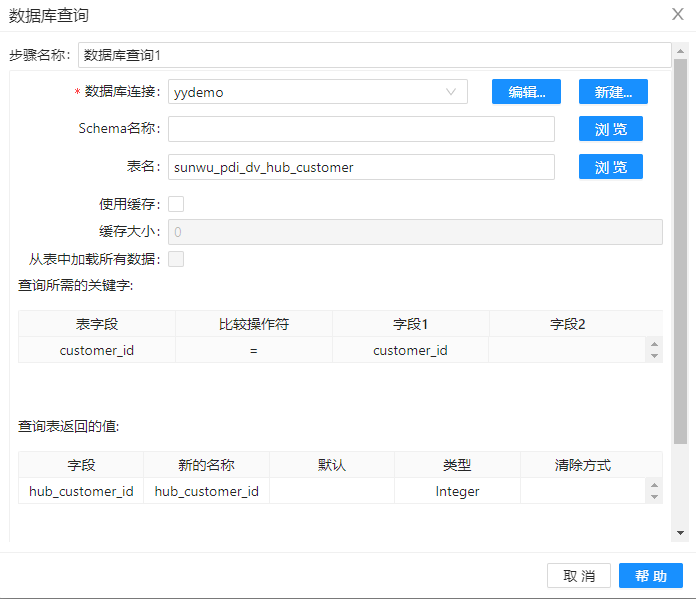
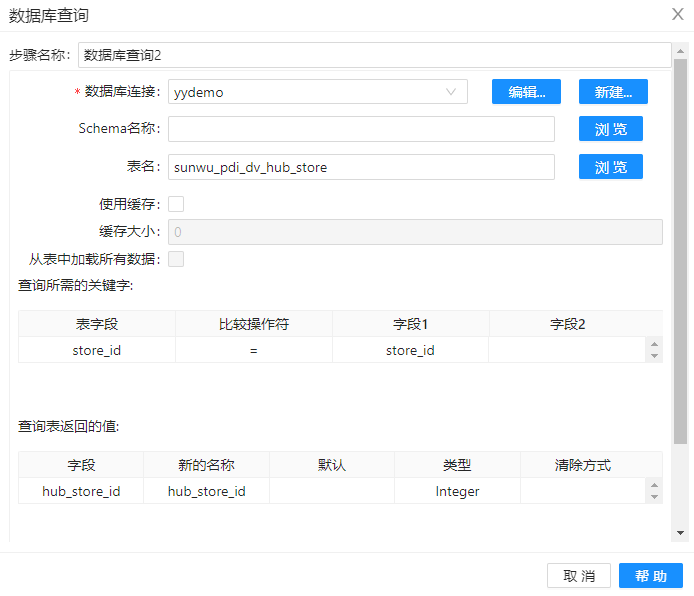
7、拖动两个组件“数据库查询“到工作区,并分别命名为“数据库查询1”和“数据库查询2”,并做下图配置。其目的是将字段“hub_customer_id“和字段”hub_store_id“添加到流中。
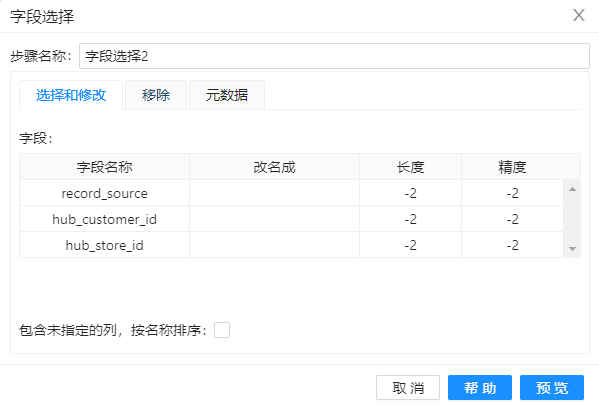
8、拖动组件”字段选择“到工作区,并重命名为”字段选择2“,做如下配置。其目的是只保存列表中的字段,移除不在列表中的字段。
9、拖动组件“表数据”到工作区,将数据导入 DV 模型中,配置如下图。
加载附属表
本节介绍将 sakila 中的表 actor 载到 DV 模型的附属表中,以加载 actor 表为例,其他转换与此类似。转换总览如下
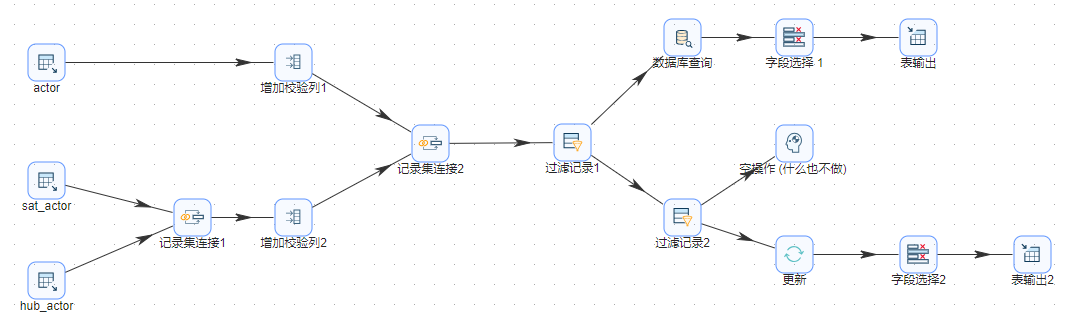
1、拖动三个组件“表输入”到工作区,分别命名“actor”、“sat_actor”和”hub_actor“,其目的是分别将表中的数据读取到组件中,配置分别如下图。
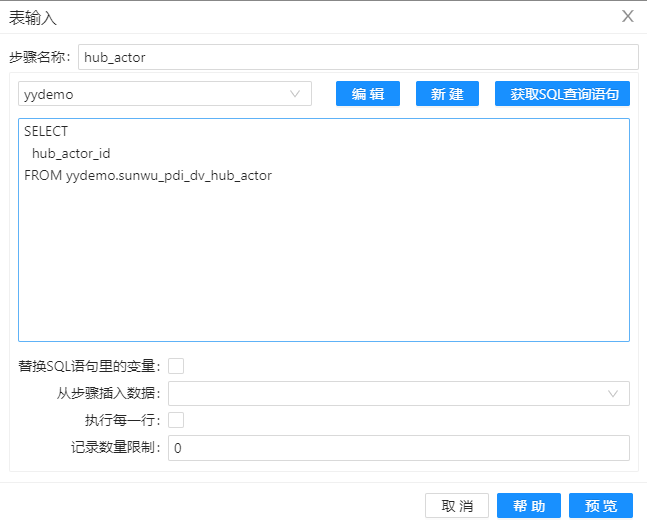
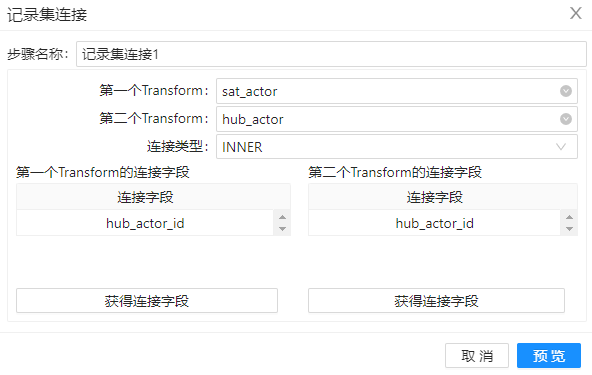
2、拖动组件”记录集连接“到工作区,并重命名为”记录集连接1“,将表”sat_actor”和“hub_actor“表的数据进行左连接,配置如下图。
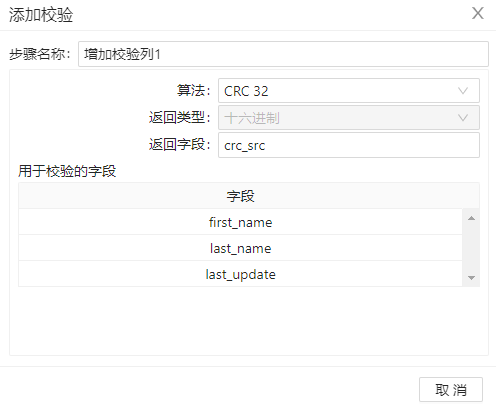
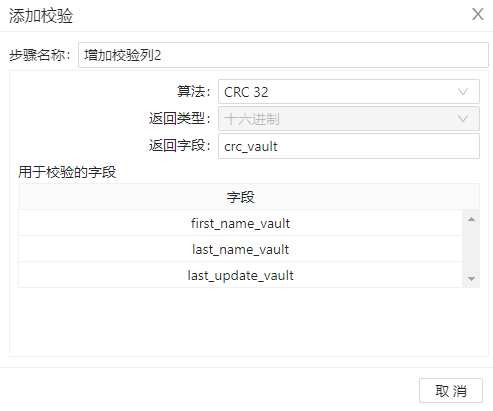
3、拖动两个组件“增加校检序列”到工作区,分别命名为“增加校验列1”和“增加校验列2”,为两组数据增加 crc 校检码,检查数据是否发生改变,配置分别如下图。
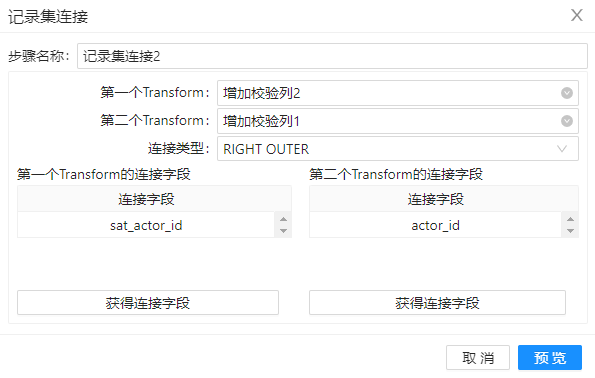
4、拖动组件“记录集连接”到工作区,并重命名为“记录集连接2”,将来自源表“actor”和 DV 模型中的数据连接起来,配置如下图。
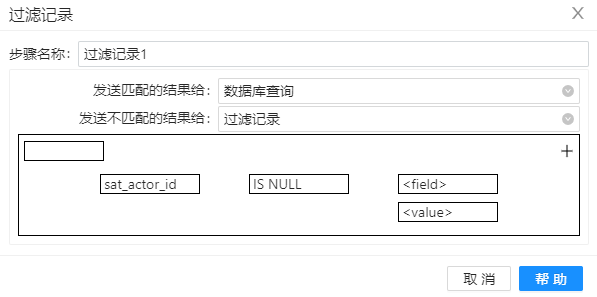
5、拖动组件“过滤记录”到工作区,并重命名为“过滤记录1”,将 DV 模型中没有的数据发送到“数据库查询”组件,将 DV 中已有的数据发送到组件“过滤记录2”,配置如下图。
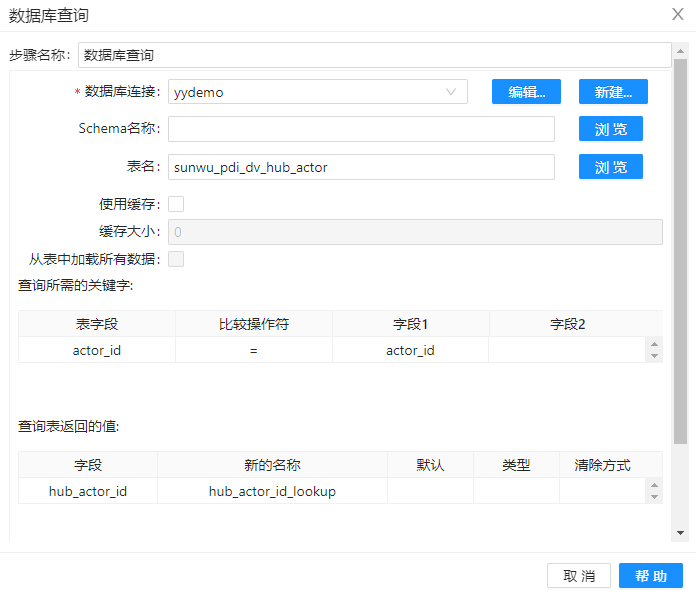
6、拖动组件”数据库查询“到工作区,并重命名组件名称为“数据库查询”,在数据库中查找字段“hub_actor_id”的值,配置如下图。
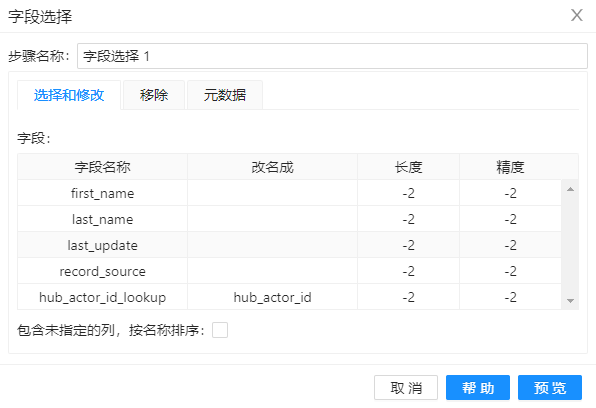
7、通过组件“字段选择1”去除不需要的字段,配置如下图。
8、将步骤 7 的数据入库,配置如下图。
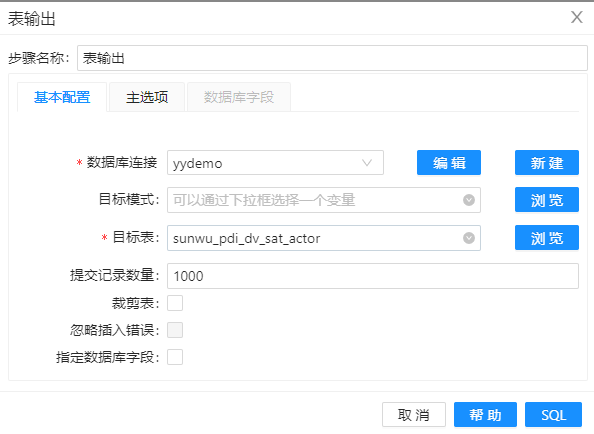
9、通过两组数据的 crc 值对比,将 crc 值相同的数据过滤掉(什么也不做),将发生变化的数据送到组件”更新“,配置如下图。
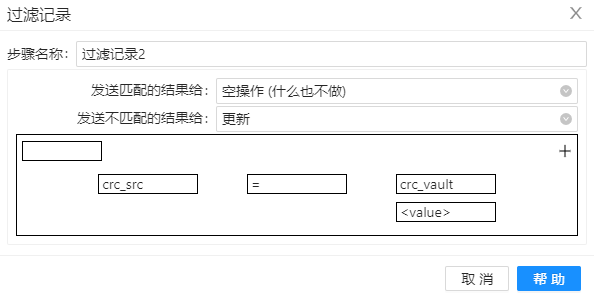
10、将字段“load_end_dts”更新到数据库,配置如下图。
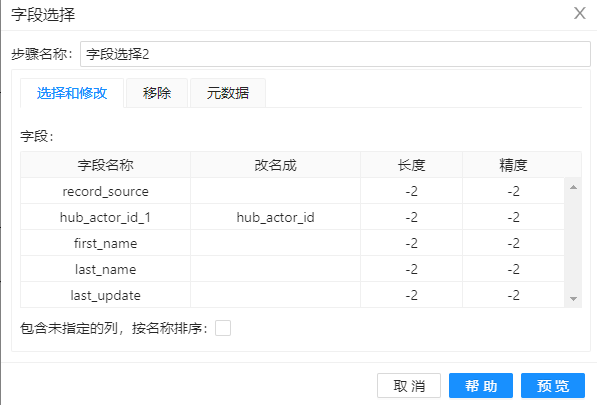
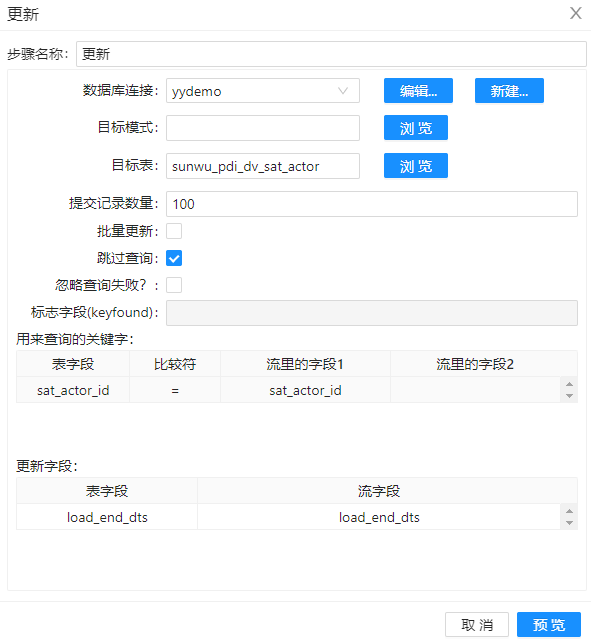 11、去除步骤 10 中多余的字段,配置如下图。同时入库,入库配置与步骤8相同。
11、去除步骤 10 中多余的字段,配置如下图。同时入库,入库配置与步骤8相同。
实例:从 Data Vault 模型加载到数据仓库
安装数据仓库
下载 SQL 文件 sakila_snowflake_schema.sql,使用 Mysql 的 source 命令导入数据库即可。
加载数据仓库
本章介绍使用 UDI 将 DV 中的数据加载到 DM 中,以加载 actor 表为例,其他转换与此类似 。
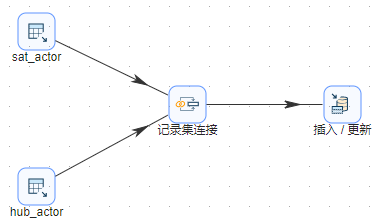
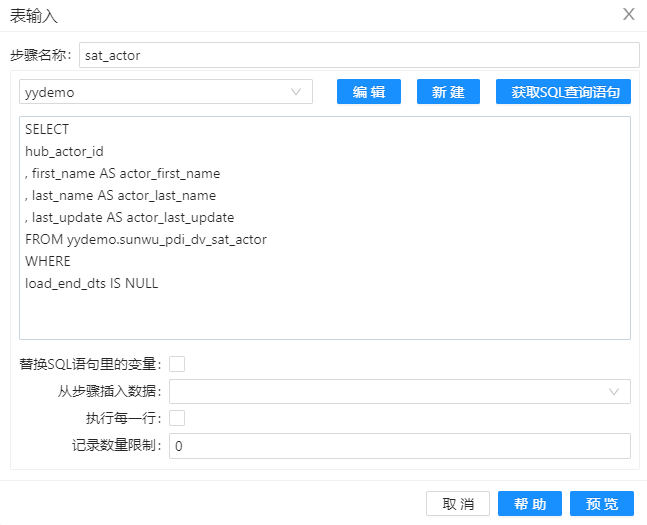
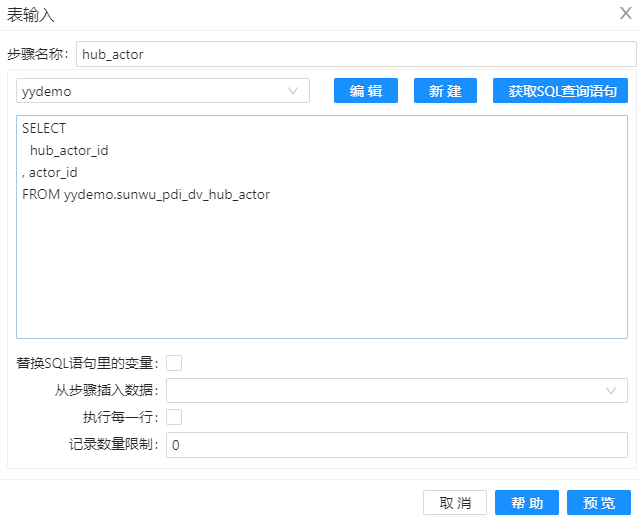
1、拖动两个组件“表输入”到工作区,并分别重命名为“sat_actor”和“hub_actor”,将两张表中的数据导入组件。其配置分别如下。
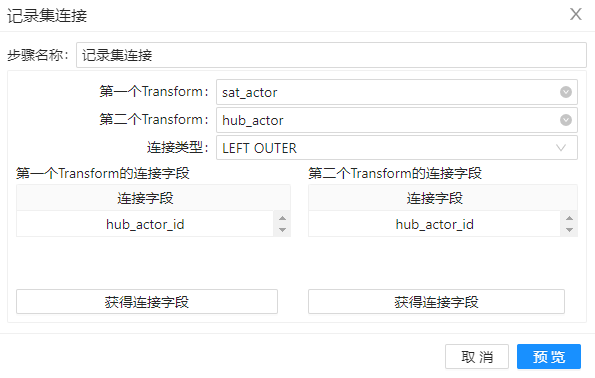
2、拖动组件“记录集连接”到工作区,将步骤 1 产生的两表数据连接起来。其配置如下。
3、将新的数据插入维度表。
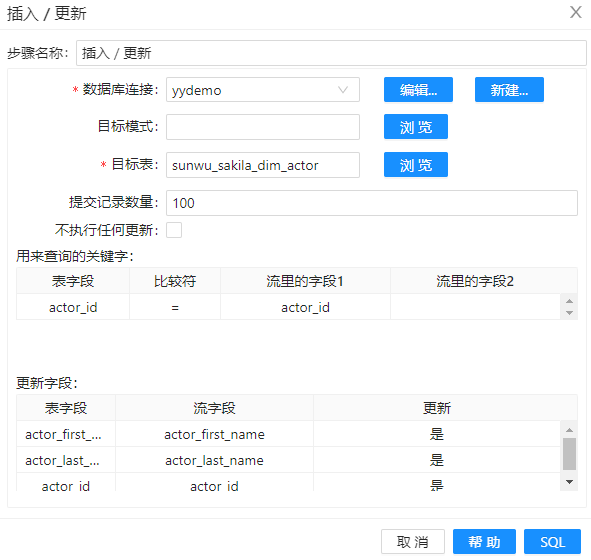
小结
在本章,我们介绍了 Data Vault 模型的概念,以及如何使用这个模型构建数据仓库。Data Vault 相对其他模型有很多优点,最主要的优点如下。
1、可审计性/可追踪性:每一次对源系统的变更都可以被捕获到,DV 更适合于对数据的审计性和可追踪性有需求的场景。
2、可重复性/易用性:DV 模型里只有几类实体类型(中心表、链接表、附属表),DV 模型有着简单的、可重复性的结构,非常适合于自动生成模型和 ETL 代码。
3、适应性:源系统结构的变化可以方便地反映到 DV 模型中,DV 模型不用修改现有的表结构。
本例子构造了一个 Data Vault 模型,作为演示用例。我们详细讲述了从 sakila 库到 Data Vault 模型的主要转换步骤,也讲述了从 Data Vault 模型到数据集市的主要转换步骤。通过本节,我们也了解到 Uniplore 是一个通用的ETL工具,可以使用在任何数据仓库的场合。