事实表加载
案例介绍
开始之前,我们先来了解一下什么是事实表。事实表是用于分析的详细的业务数据的集合,它数据量大,会消耗大量的存储。在一个典型的数据仓库环境中,事实表会占用大部分存储空间,事实表的大小可以到几个G、几个T,甚至几个P的数据。为了把数据从源系统中加载到数据仓库里,需要一个快速加载机制,为了快速加载,大多数数据库系统都提供了批量加载方式,批量加载方式通常规避了数据库的事务引擎,直接把数据写入到目标表。本案例将介绍Uniplore几个快速实现加载事实表的组件。
说明:尽管本部分的主题是加载事实表,Uniplore批量加载的功能也可以用于其他批量加载工作,例如把文本文件加载到数据缓冲区。
在把数据加载到最终的目的表之前,还要做一些其他操作,例如:查询正确的维度代理键。记住加载事实表是ETL过程的最后一步。首先,数据从业务系统中抽取出来,并写入到一个缓冲区文件或数据库表。然后,要更新所有的维度表,最后使用更新后的维度去加载事实表。尽管这个处理数据的过程看上去简单,但实际中并不容易做好。维度数据或者事实数据都可能会晚到,此时就需要处理迟到数据这种情况,本案例也会介绍怎么去处理迟到数据。
数据说明
本案例说用到数据源来至Sakila数据库,Sakila 是 MySQL 中的一个示例数据库(sample database),提供了一个标准的方案,可用于自学,写书,教程,文章以及示例等。详细介绍请参考 Sakila数据集介绍 。关于Sakila数据库读者亦可参考相关的官方文档。为了方便起见,读者可直接使用下方提供的 sakila 数据库 SQL 脚本。
其中,sakila-schema.sql 与 sakila-data.sql 用于创建sakila据库,sakila_dwh_schema.sql和sakila_dwh_data.sql 用于创建演示中所用的雪花模型。在本示例中,系统从源数据库 sakila 抽取增量数据。然后添加到雪花维度表中。
事实表
在往数据仓库加载事实表之前,需要把数据准备好。加载事实表过程并不是重点,之所以把加载事实表单独分出来, 主要是为了强调如下三种不同类型的事实表。 事务粒度事实表:以每一个事务或事件为单位,例如一个销售记录、一个电话呼叫记录,作为事实表里的一行数据。 周期快照事实表:事实表里并不保存全部数据,只保存固定时间间隔的数据,例如每天或每月的库存水平,或每月的账户余额。 累积快照事实表:当有新的数据时,更新事实表里的记录。 数据仓库里总是保存最新的数据。例如订单过程,订单过程里有很多独立的日期,如订单日期、期望发货日期、实际发货日期、期望收货日期、实际收货日期和付款日期。当这个过程进行时,随着上面各种时间的出现,事实表里的记录也在不断更新。
维度查询
加载事实表时,要完成的一个重要操作就是要查询到维度表里正确的代理键(你可以在处理维度表中知道什么是代理键)。对于一个多维数据仓库来说,事实表里的每个外键都对应维度表里的一个主键。找�到正确的维度代理键的方法非常简单,这种方法形象地被称为代理键管道。Uniplore介绍了一个更详细的例子,根据sakila数据库里的租赁日期抽取维度主键。
使用内存查询
最快的查询方式就是从计算机的RAM中查找。所以最快的找到某个代理键的方法就是把所有维度保存在内存中,然后在内存中查找。“数据库查询”步骤中的“使用缓存”和“从表中加载所有的数据”选项可以实现在内存中查找。但要小心这种方法容易造成内存溢出,尤其是一个转换里有多个数据库查询步骤。另外要限制列数,只使用真正需要的列来做查询。如果你需要的只是业务键和代理键,以及可选的开始/结束日期列,那么就没有必要把维度表全部都加载到内存里。
流查询
在大多数情况下,“数据库查询”步骤可以很好地工作。但它不能解决所有问题。如果要查询的数据来源于一个外部数据源,或者不在数据库里,该怎么办?这时需要使用“流查询”步骤。这个步骤没有“数据库查询”步骤那么多的选项,它只允许做等值查询。但这个步骤支持从各种数据源和其他步骤查询数据。在一些场景下,如维度数据和事实数据能同时准备好,先使用“表输入”步骤获取每个业务键最后一个版本的维度记录,然后再使用“流查询”步骤把“表输入”步骤的结果作为输入,是查询大型维度表的最快查询方��式。
处理迟到数据
在正常情况下,是有规律地从源系统中抽取和处理数据。在介绍部分曾经说过,标准的顺序应该是先处理维度表再处理事实表。这个顺序很重要,因为我们需要事实表里的指向维度表的代理键,而代理键需要通过维度加载过程生成。但如果数据没有顺序到来,例如,事实数据或维度数据晚了几天甚至几个星期才到来怎么办?这样加载的顺序就会被打乱;这样可能是有的客户没有订单,或有些订单指向了一个不存在的客户。如何处理这类问题呢。这类问题分两种情况。
迟到事实数据
当交易发生很久以后,交易数据才被送到ETL处理过程,就是迟到的事实数据。在迟到期间,相关的维度数据可能有了新的版本,所以如果还是简单查询当前的记录,就会得到错误的维度代理键。此时要使用valid_from和valid_to时间戳就可以得到正确的维度版本以及相应的维度代理键。
迟到维度数据
迟到维度数据是相反的一种情况,事实数据已经处理完了,而维度数据还没有到。迟到维度数据比迟到事实数据更难处理。因为如果维度表不是最新的,那么加载事实表时就会发现有的维度,如客户,在客户维度表里并不存在,结果维度查询就会失败。
加载事实表案例
在这个例子里有一个客户维度表和一个事实表,客户维度表里有几个字段,事实表里有customer_id、sale_date和sale_amount几个字段。
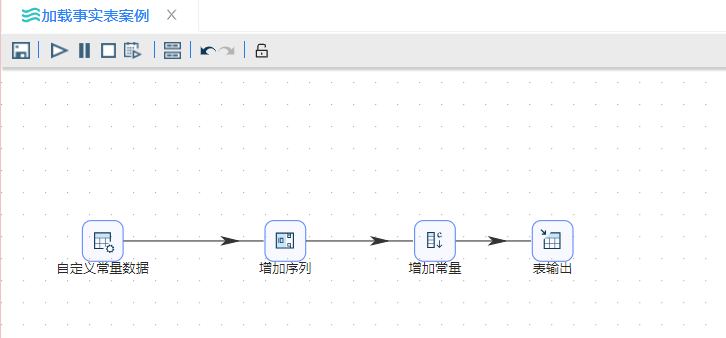
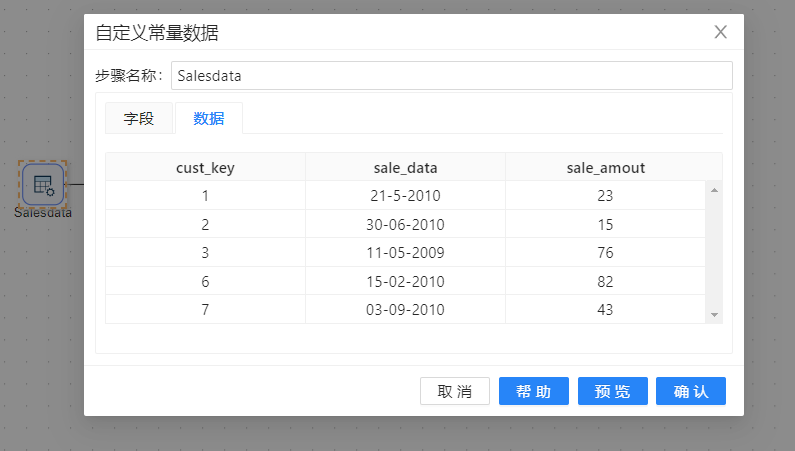
- 转换开始使用“自定义常量数据”步骤生成六条客户数据,这些数据最终也就维度表dim_customer中数据。
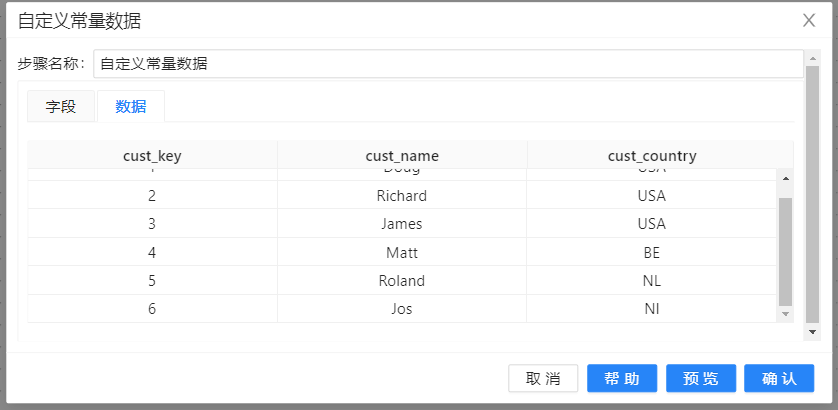
- 利用“增加序列”来生成代理键,采用默认配置。
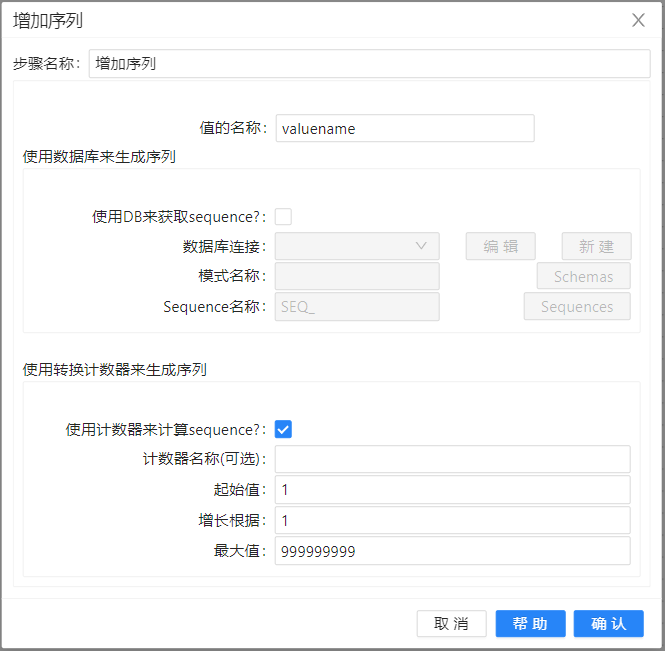
- 接下来我们采用“增加常量”增加三个字段valid_from、valid_to、current_flag。
- “表输出”到数据库的维度表中。
注意表里有六条客户记录,都加载到了dim_customer维度表里。
下面我们要创建一些销售数据在自定义常量数据Salesdate中,这里销售数据就代表我们的事实表要加载的数据。通过数据库查询查询代理键,然后用表输出
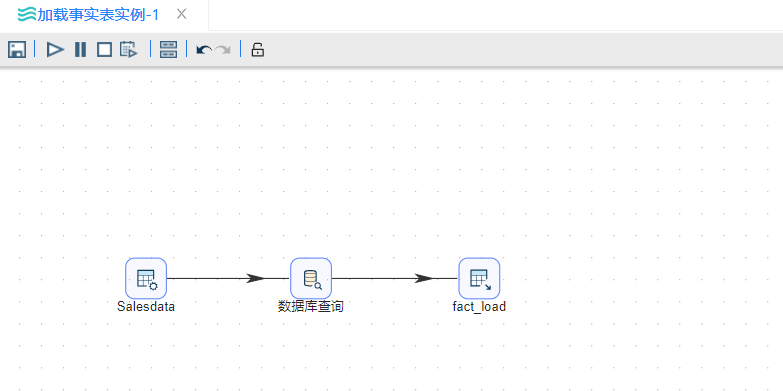
这里只有5条销售通过自定义常量生成。在实际情况中,数据量远远非常大。
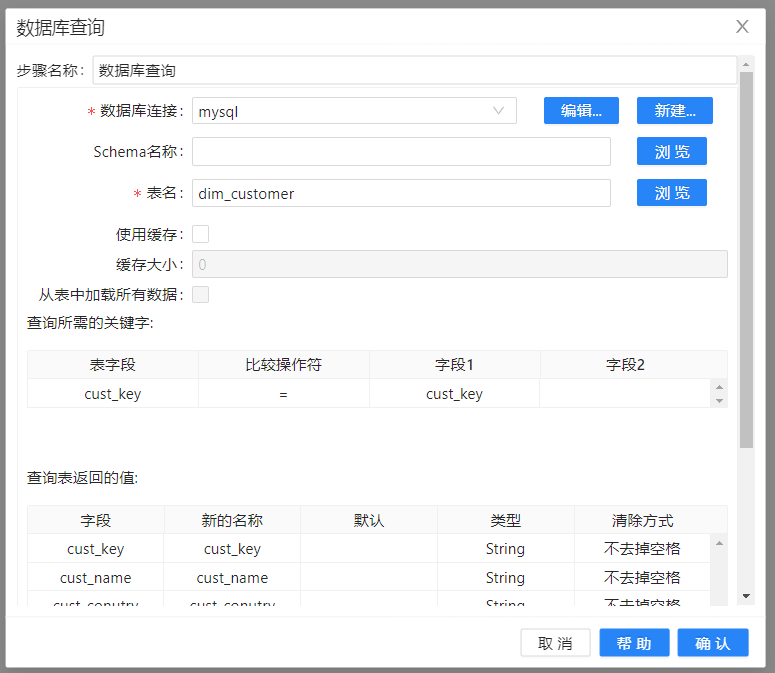
这些数据将被发送到“数据库查询”步骤,来查找客户维度表的 customer_id代理键。就像前面说的维度查询我们采用的是数据库查询,这里因为数据比较少没有采用缓存,你也可以尝试,记住要注意内存溢出。还有这里的查询失败选择忽略,后面我们会提到。
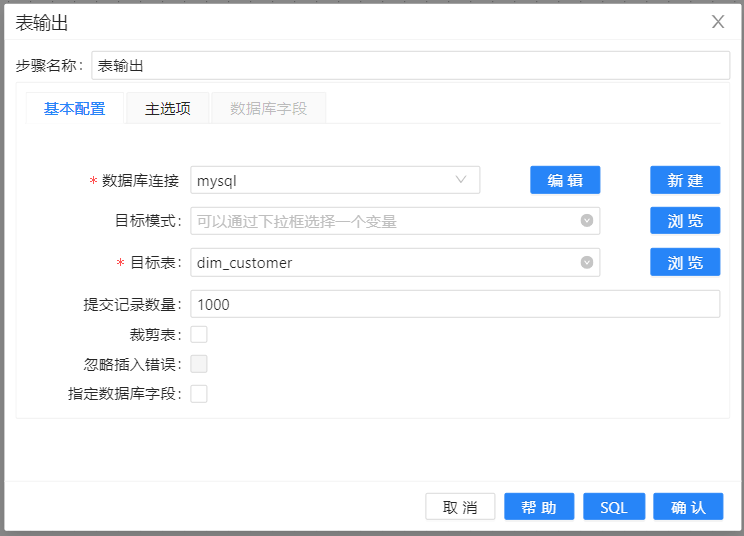
维度查询之后,就是最后一步加载事实表,这里采用的是表输出组件。注意提交的记录数,表输出默认也是批量加载,一次提交的数量为1000。
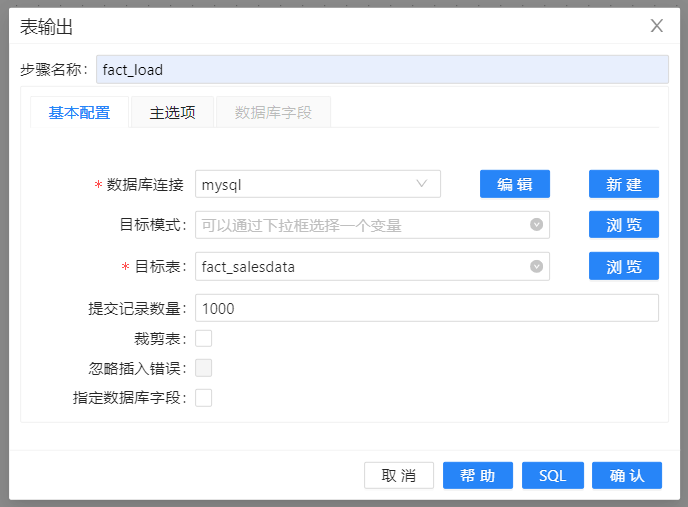
至此,加载事实表的过程就完成了。但是就像前面说的,现实中并没有那么容易。你可能注意到在这些销售数据里有一条销售数据的客户不在dim_customer维度表里。前四条记录都可以找到对应的客户维度,但是cust_key =7的记录找不到对应的客户维度记录。这也就是前面数据库查询为什么要选择查询失败忽略。
为了处理查询失败的数据,我们给“数据库查询”步骤增加一个错误处理步骤。这些数据都可以存到一个文件里、一个数据库里,甚至使用“复制记录到结果”步骤保存到临时的内存空间里。在这个例子里,我们把��这些数据保存到一个文件里。整体转换过程如下:
文件我们存储到当前文件夹,命名unkowns custs。
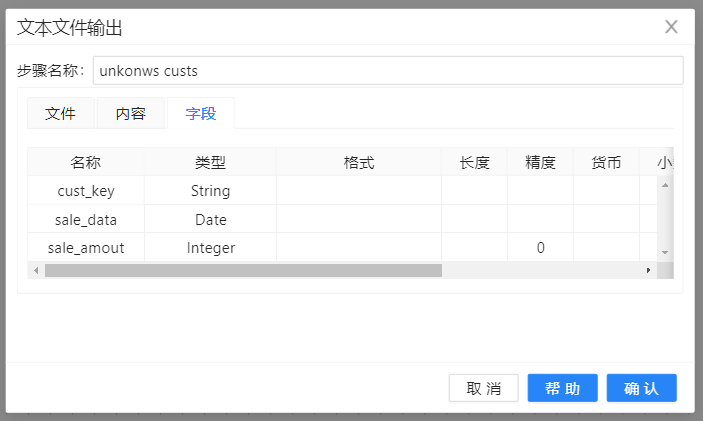
完成前面操作后,现在我们就可以把这些分离出来的客户维度加载到维度表中, 在维度表中创建新的维度记录。
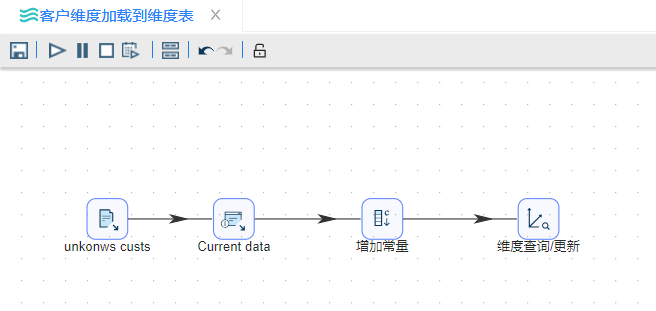
首先从上步骤中存储的文本文件中读取这些维度,然后使用一个“获取系统信息”步骤加入今天的日期。
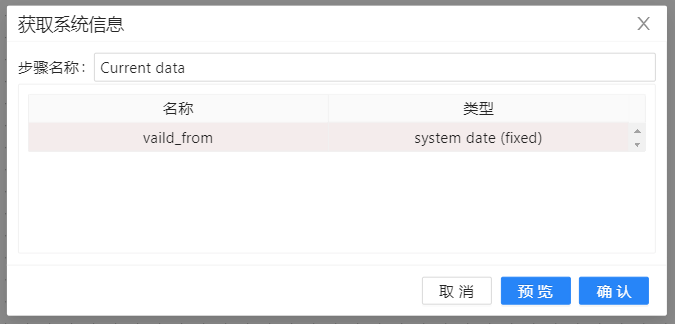
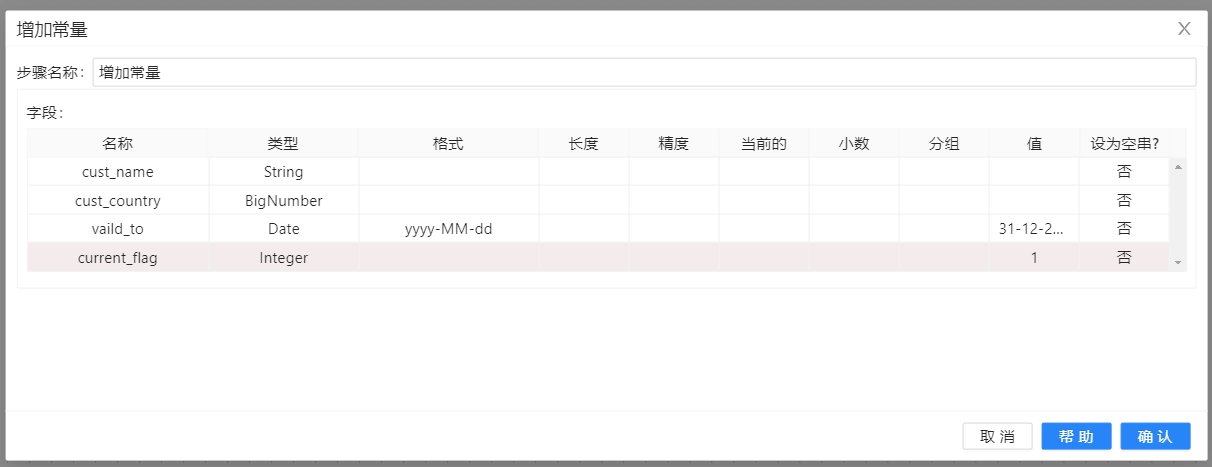
接着使用一个“增加常量”步骤,将维度中没有的字段设置成“N/A”
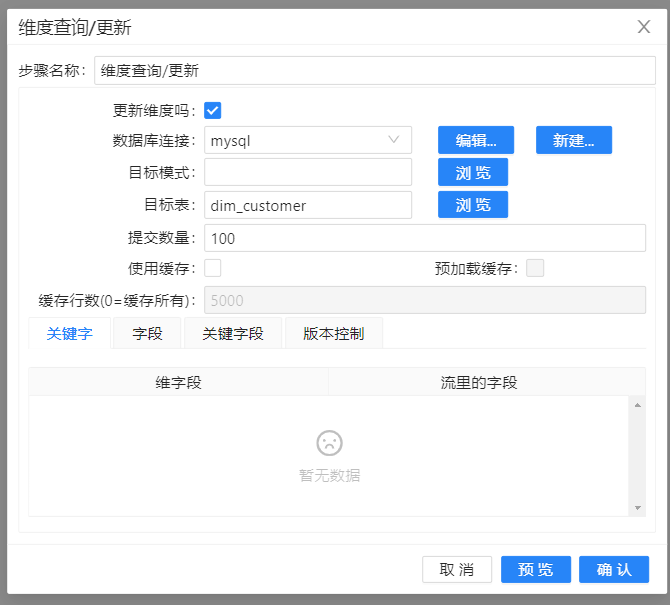
转换的最后使用“维度查询更新”步骤生成新的customer_id,并增加到客户维度表中。
最后再把被拒绝的事实数据重新查询一遍维度表,此时就可以查到新插入的维度记录,以及返回相应的customer_id键。
批量加载
完成查询正确的维度代理键后,我们可以进行最后一步的加载事实表了。
如果数据量不大,几千行甚至几十万行,使用标准的DML(Data Manipulation Language)语句就可以很好地把数据加载到数据库表中。但如果要加载几百万行甚至几十亿行数据,就不能再使用Insert这样的语句了。为什么?很简单:因为所有的DML语句,如insert,update和delete操作,都被数据系统日志记录下来。也就是说除了要往表里插入数据,这些数据还被写入到数据库的事务日志中。另外,所有数据库列的约束还要检查数据。日志和约束检查会严重影响性能, 所以从性能优化的角度,就要使用“批量加载”的处理方式。
每一种数据库都有自己批量加载的方法,各自的前提和方法非常不同,有最简单的MySQL里使用的LOAD DATA INFILE文件,也有复杂的Oracle里使用的SQL*Loader命令。但不是所有的数据库都可以把其他外部程序的输出直接作为批量加载的输入。
前面讲过,每种数据库都有自己批量加载的方法。就是说,对每种数据库都要有一个批量加载的步骤。Uniplore对大部分数据库都提供了批量加载的步骤,例如Oracle、SQL Server、MySQL和PostgreSQL等,也包括一些不常见的数据库,如Greenplum、MonetDB和LucidDB等。
在案例前面的维度数据迟到数据中我们已经进行过加载事实表的操作,尽管表输出不属于批量加载步骤,但当加载几千行或更多行数据时,使用表输出也是一个很好的选择。
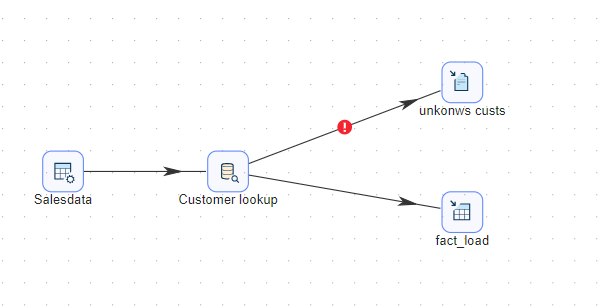
我们可以将表输出fact_load换成批量加载的方式,对于不同数据库,采用不同的数据库批量加载方式即可。
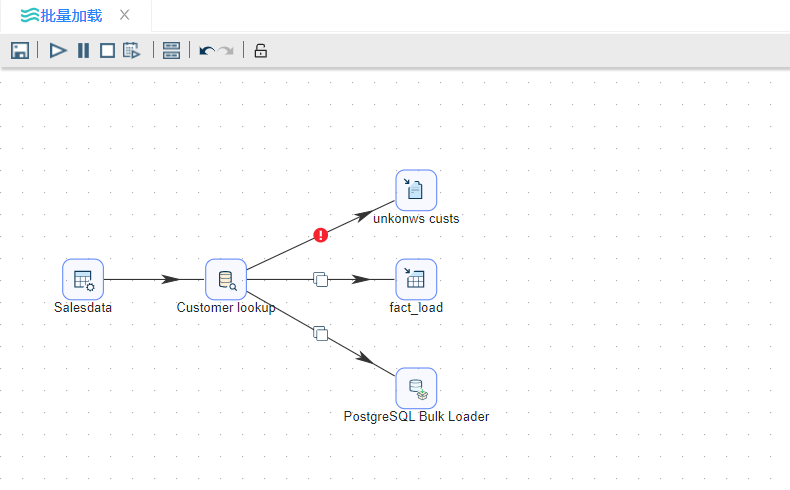
这里采用PostgreSQL批量加载。连接数据库,fifo文件为PostgreSQL批量加载的文件。
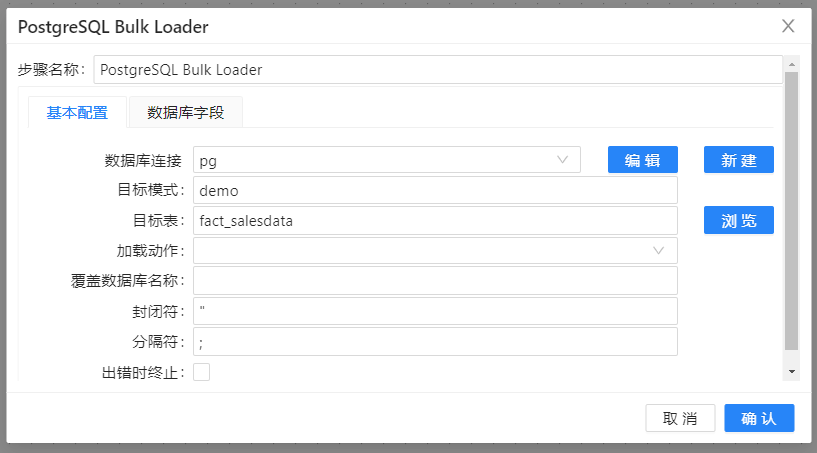
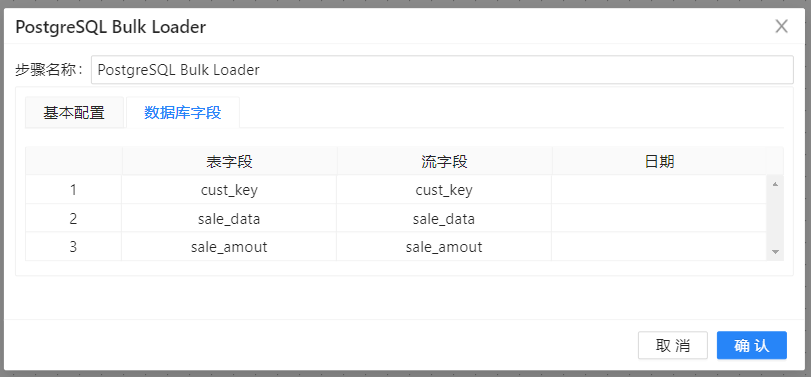
这里,我们整个加载事实表才算是真正完成。
小结
本案例介绍了不同类型的事实表和使用uniplore的加载事实表的方法。 加载事实表要做的准备工作之一就是查找正确的维度代理键,我们也称之为“代理键管道”。我们介绍了维度查询的两种方法——数据库查询和流查询,另外深入介绍了如何处理迟到的维度数据和事实数据。