数据提取和加载
案例说明
ETL 过程的第一步就是从一个或多个数据源获取数据,数据抽取是一个艰难的工作,因为数据源是多样和复杂的。在传统的数据仓库环境下,数据通常来源于企业的事务类应用系统,如财务系统或 ERP 系统。大部分这类系统都是把数据存储在关系数据库中,如 MySQL 、Oracle 或 SQL Server。抽取一般要从业务的角度来抽取,这也是一个挑战,从技术上来看,最好能使用 JDBC 直接连接数据库。但如果数据库不是关系型的或者没有可用的驱动,数据抽取就会更有挑战性。在这种情况下,一般就需要使用逗号分隔的文本文件来获取数据。还有一种情况就是数据属于其他人,可能是某个供应商或客户的数据,数据位于公司防火墙之外。在这种情况下,不可能直连,使用文本文件交换数据是唯一选择。如果数据位于互联网上,文本文件也不能使用。在ETL项目里还应重视数据特征,它描述了数据的基本结构,它是数据的一组统计信息,能从总体上了解数据内容和数据质量。本案例将讲述 Uniplore 中几种抽取数据的组件以及 Uniplore 如何支持不同的CDC(Change Data Capture)技术。
数据准备
建表脚本: etl_test_input.sql etl_test_output.sql
数据:etl_test_input.txt 本案例中“从数据库中读取数据”小节将使用此数据;
足球比赛数据:usa_201209.txt 本案例中“从文本文件中读取数据”小节将使用此数据;
购房者信息数据:custinfo.xlsx 本案例中“从Excel中读取数据”小节将使用此数据;
建表脚本:create_products.sql
数据:productlist_LUX_200908.txt 本案例中“向数据库中插入数据”小节将使用此数据;
本案例中“创建参数查询”、“基于时间戳的CDC”和“基于快照的CDC”三个小节将利用 Sakila 数据库中的 custmor 表和 cdc_time 表,Sakila 是 MySQL 中的一个示例数据库(sample database),提供了一个标准的方案,可用于自学,写书,教程,文章以及示例等。详细介绍请参考 Sakila数据集介绍 。关于Sakila数据库,读者亦可参考相关的官方文档。 sakila-db.zip
从数据库中读取数据
在进行本小节前,需要提前在数据库建好对应的表。将计算【start_date】与【end_date】字段之间所间隔的天数,并根据所隔天数来设定字段【performance】的值。通过“表输入”组件从数据库中读取数据后,使用“字段选择”组件可以保留所需字段。然后在“计算器”组件中新建【diff_date】字段用于计算日期间隔。计算好间隔天数,在通过“数值范围”组件设置【performance】字段的值,其中【performance】字段为“数值范围”组件产生的新的输出字段。具体操作如下: 1、新建转换,拖拽表输入组件至画布,双击组件,在弹出的对话框中选择在Uniplore中保存好的数据库连接,单击获取SQL查询语句,在对应的文本框中即可获得对应表的查询。当然,也可以在文本框中编写自定义SQL查询语句。配置如下图所示:
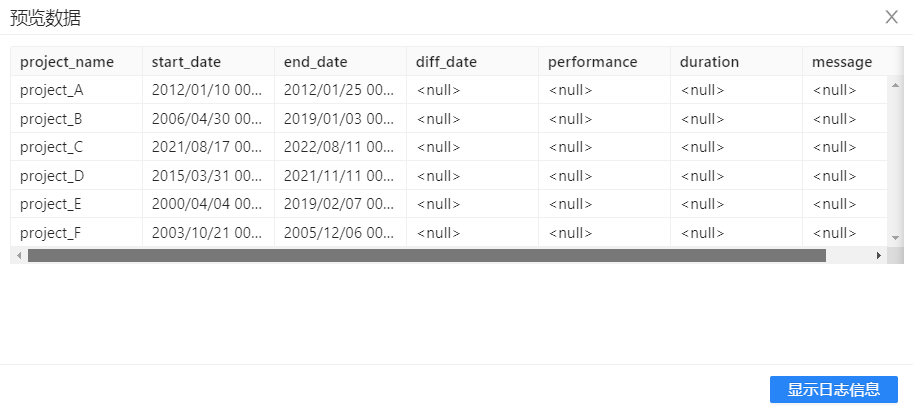
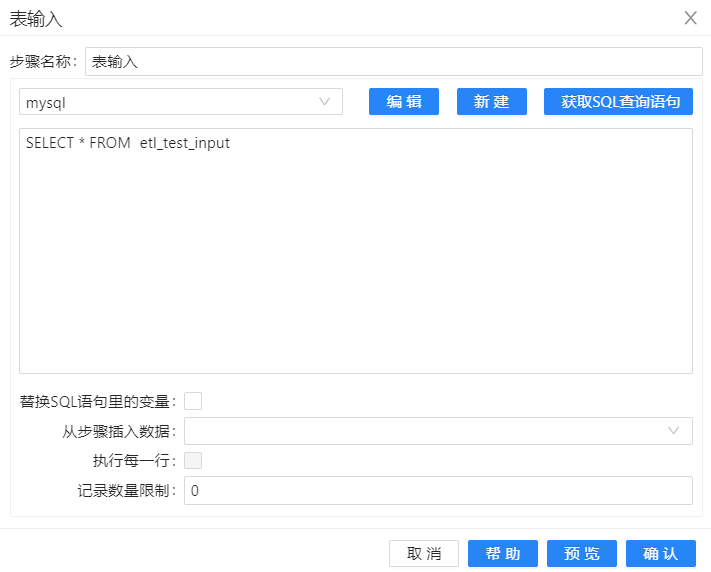 2、配置好表输入组件后,选中该组件,右击并选中**“预览”**查看数据。结果如下图所示:
2、配置好表输入组件后,选中该组件,右击并选中**“预览”**查看数据。结果如下图所示:
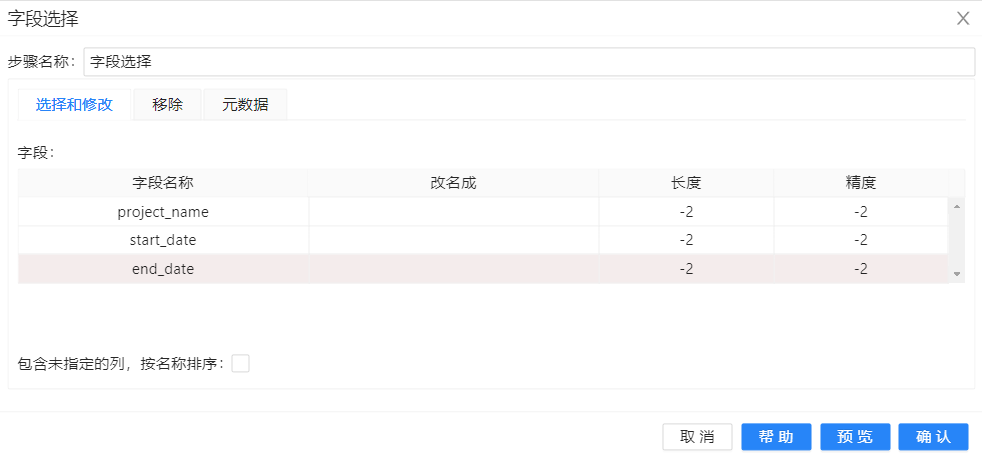
 3、将“**字段选择”**组件拖至画布,并建立从“**表输入”**到“**字段选择”**的连接。双击“字段选择”,点击右键“获取选着字段”,配置如下图所示:
3、将“**字段选择”**组件拖至画布,并建立从“**表输入”**到“**字段选择”**的连接。双击“字段选择”,点击右键“获取选着字段”,配置如下图所示:
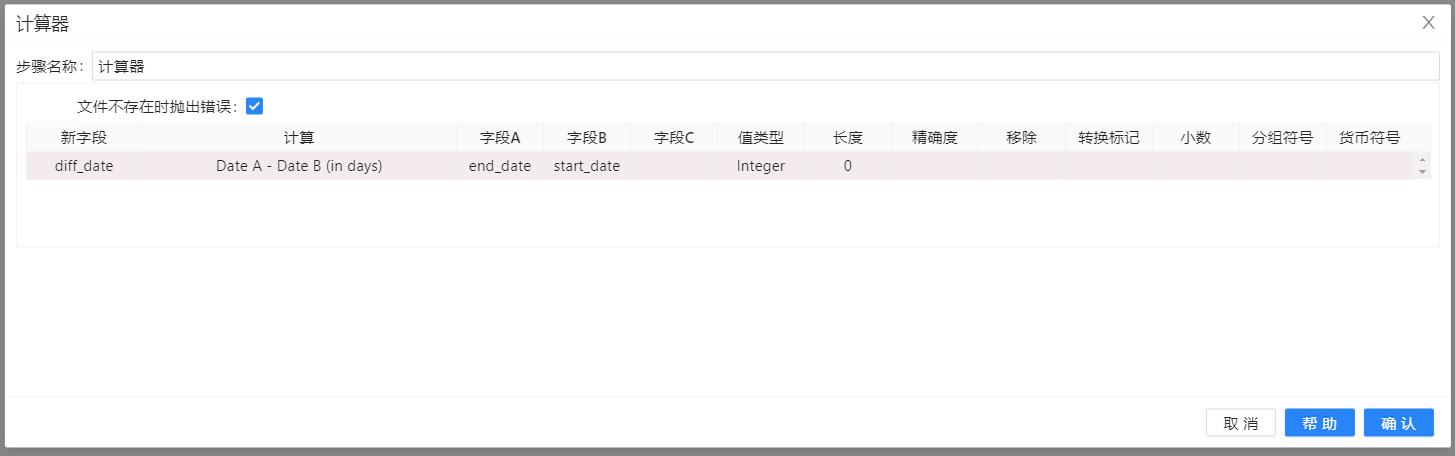
 4、拖拽**“计算器”组件至画布,并建立从“字段选择”到“计算器”之间的连接(在弹出的提示框中选择“主输出步骤”),右键“插入”,双击填写新字段信息,“计算器”**组件配置如下图所示:
4、拖拽**“计算器”组件至画布,并建立从“字段选择”到“计算器”之间的连接(在弹出的提示框中选择“主输出步骤”),右键“插入”,双击填写新字段信息,“计算器”**组件配置如下图所示:
 5、拖拽**“数值范围”组件至画布,建立从“计算器”到“数值范围”之间的连接,“数值范围”**配置如下图所示:
5、拖拽**“数值范围”组件至画布,建立从“计算器”到“数值范围”之间的连接,“数值范围”**配置如下图所示:
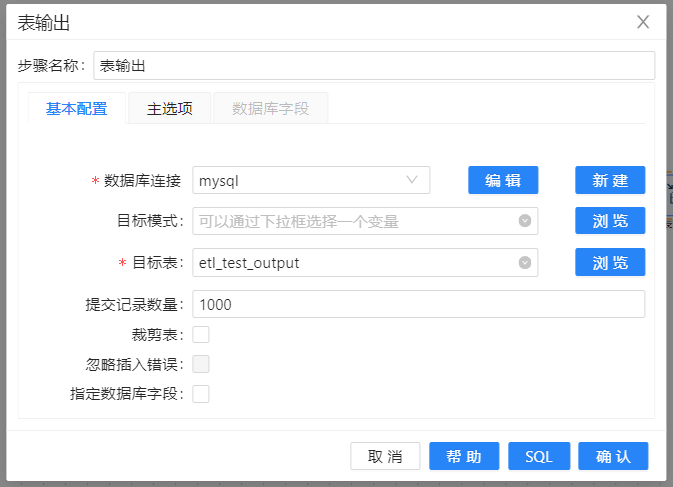
 6、拖拽**“表输出”组件至画布,建立从“数值范围”到“表输出”之间的连接,“表输出”**配置如下图所示:
6、拖拽**“表输出”组件至画布,建立从“数值范围”到“表输出”之间的连接,“表输出”**配置如下图所示:
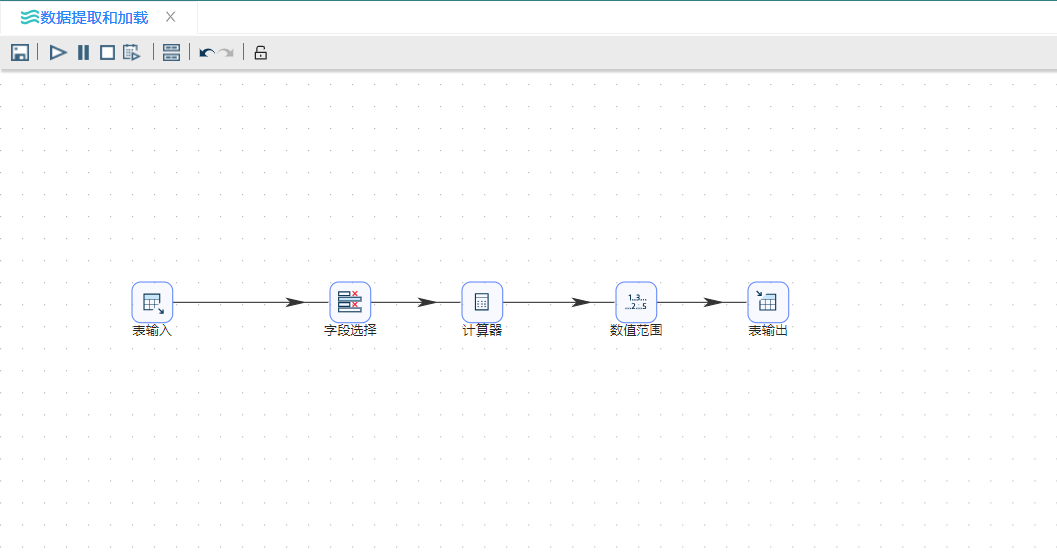
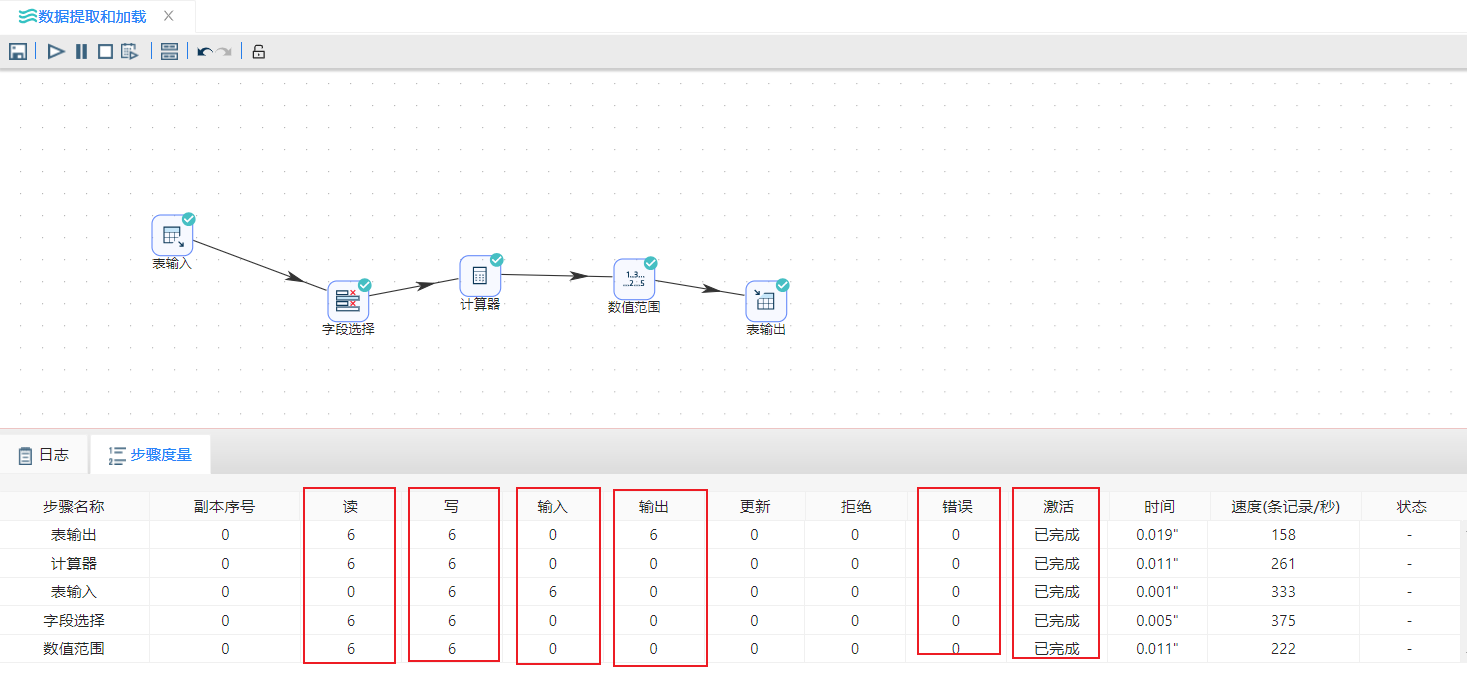
 7、完成所有步骤后,整个转换视图如下图所示:
7、完成所有步骤后,整个转换视图如下图所示:
 8、点击画布左上角**“
8、点击画布左上角**“ ****”按钮运行转换,并在弹出的提示框中点击“启动”**按钮,即可运行整个转换。结果如下图所示:
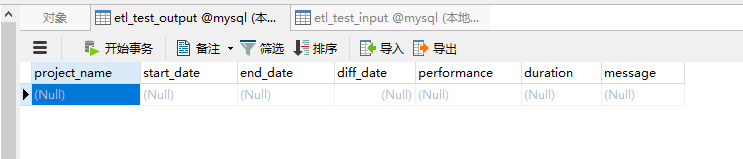
运行转换前etl_test_output表:
****”按钮运行转换,并在弹出的提示框中点击“启动”**按钮,即可运行整个转换。结果如下图所示:
运行转换前etl_test_output表:
 运行转换后etl_test_output表:
运行转换后etl_test_output表:
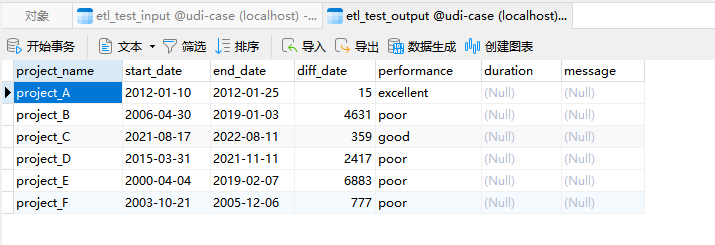 运行结果:
运行结果:
从文本文件中读取数据
本小节利用足球比赛数据演示一个 ETL 的简单应用,其中足球比赛数据包括比赛日期,比赛地点,主客队以及比分。通过 “CSV文件输入” 组件可以读取文本文件的数据,**“字段选择”组件则可以选择或修改源数据。“空操作(什么也不做)”**组件只接受数据,但是不做任何处理,一般只是测试数据的输出结果。具体操作如下:
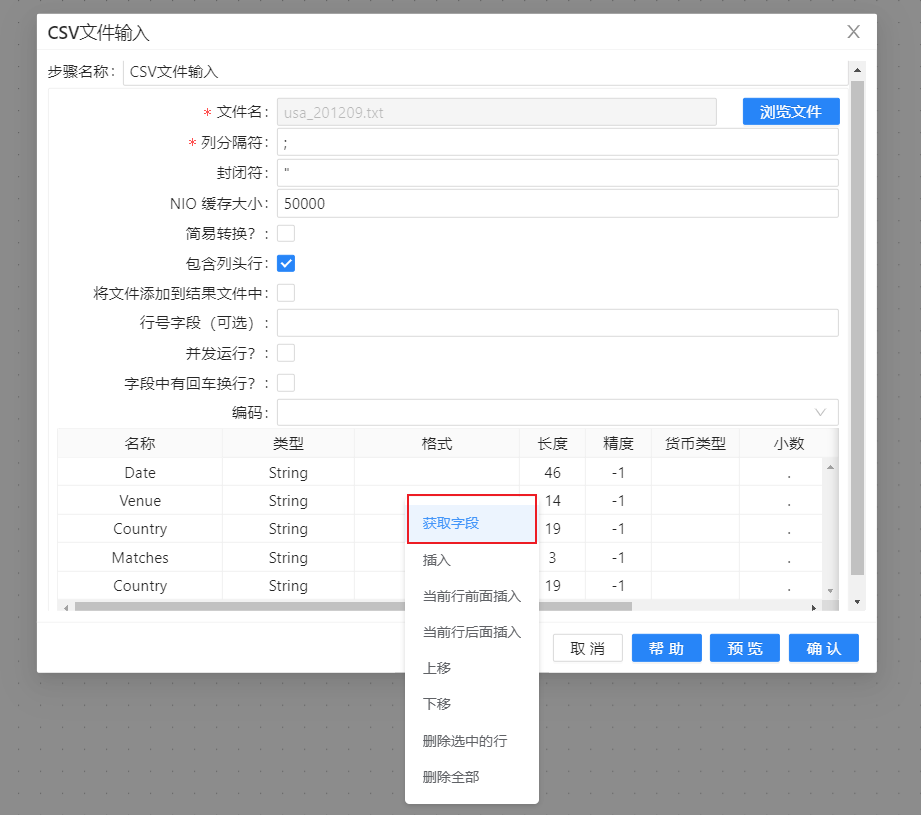
1、新建转换,拖�拽“CSV文件输入”组件至画布。双击组件,在文件名框中选择要上传的文件,列分隔符用“;”(注意,这里的分隔符要对应文件中分隔符的格式。例如,文件中为英文“;”则对应英文,若为中文“;”,则对应中文),勾选“包含列头行”。配置完成完成后,在最下面的文本框中右击空白部分会弹出一个提示框,选择“获取字段”按钮可以获取文本文件中的字段。配置如下图所示:
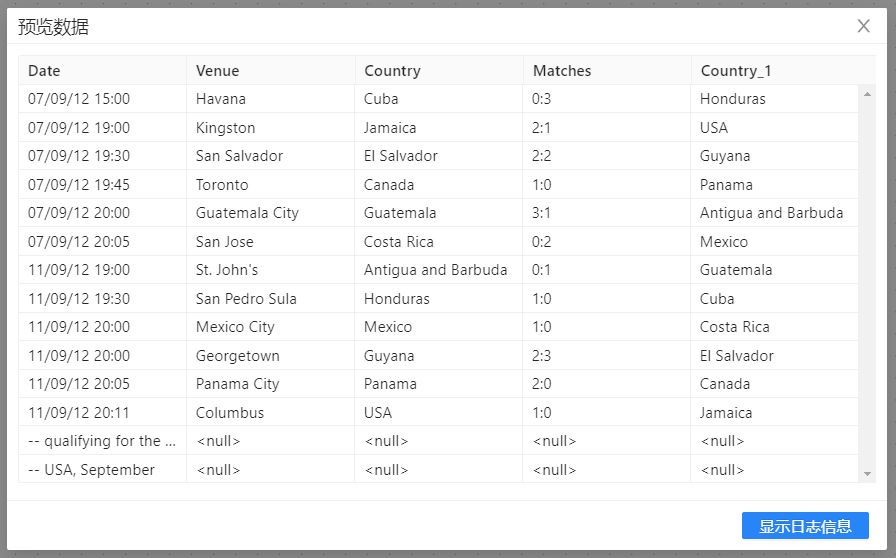
2、选择“CSV文件输入”,右击并选择预览,预览数据,如下图所示:
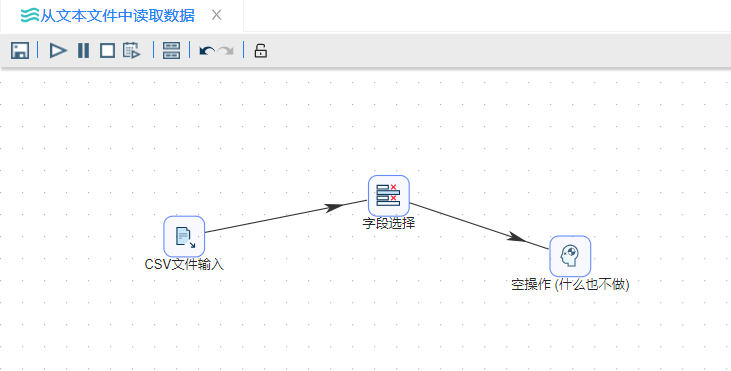
 3、拖拽**“字段选择”和“空操作(什么也不做)”组件至画布,并按顺序连接。若提示选择步骤,依然选择“主输出步骤”**。完整转换如下图所示:
3、拖拽**“字段选择”和“空操作(什么也不做)”组件至画布,并按顺序连接。若提示选择步骤,依然选择“主输出步骤”**。完整转换如下图所示:
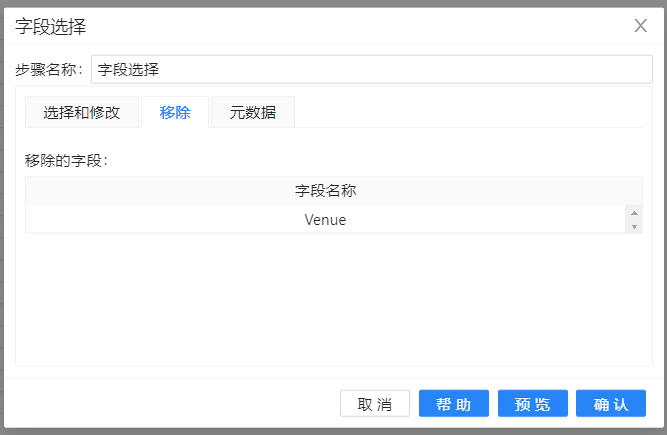
 4、双击**“字段选择”组件,右键获取字段信息,选中“移除”**标签,在空白文本框中选择要移除的字段 “Venue”。配置如下图所示:
4、双击**“字段选择”组件,右键获取字段信息,选中“移除”**标签,在空白文本框中选择要移除的字段 “Venue”。配置如下图所示:
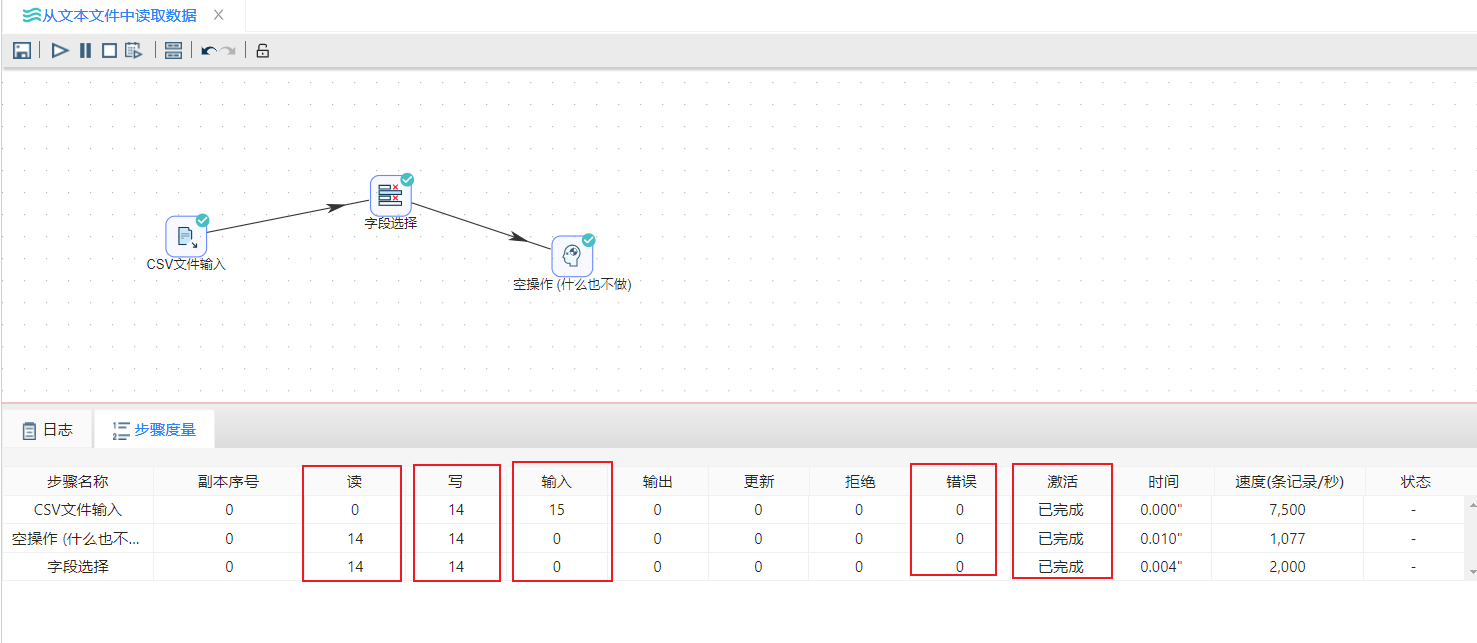
5、运行转换,结果如下图所示:
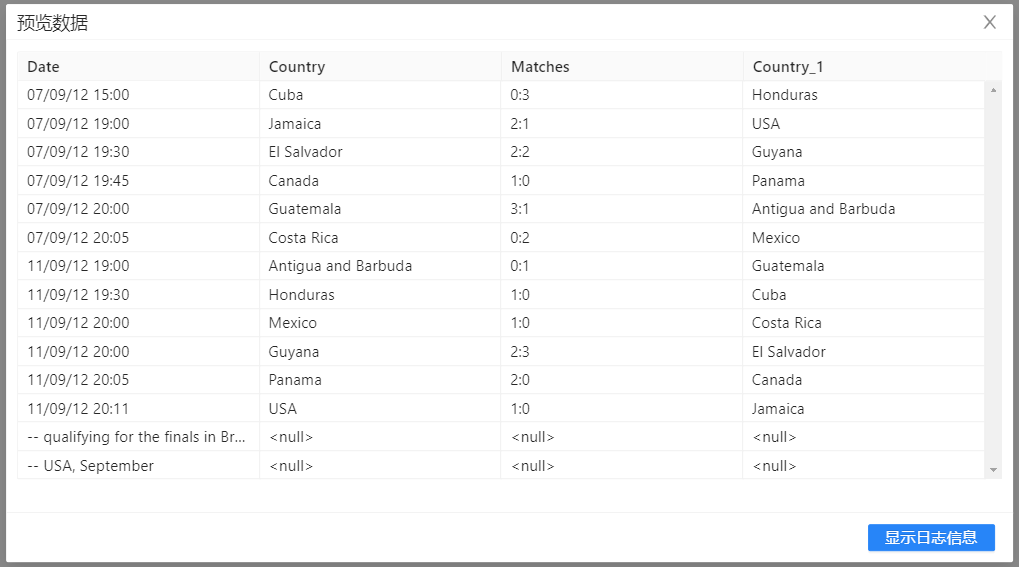
6、选中**“空操作(什么也不做)”组件,右击并选中“预览”**查看数据。结果如下图所示:
从Excel文件中读取数据
本小节主要是展现**“Excel”**类型的文件的输入。数据背景源于近年来房地产市场的火爆,房价在节节攀升,对于普通人来说,购买一套合适的住房可能是一生中最大的投资,仓促地做出购房决策可能会影响到人们将来的生活质量与幸福。因此,很多人不得不慎重考虑购房问题。房地产市场也在不断地推出新的楼盘,房屋价格、环境、面积、户型等各有不同.
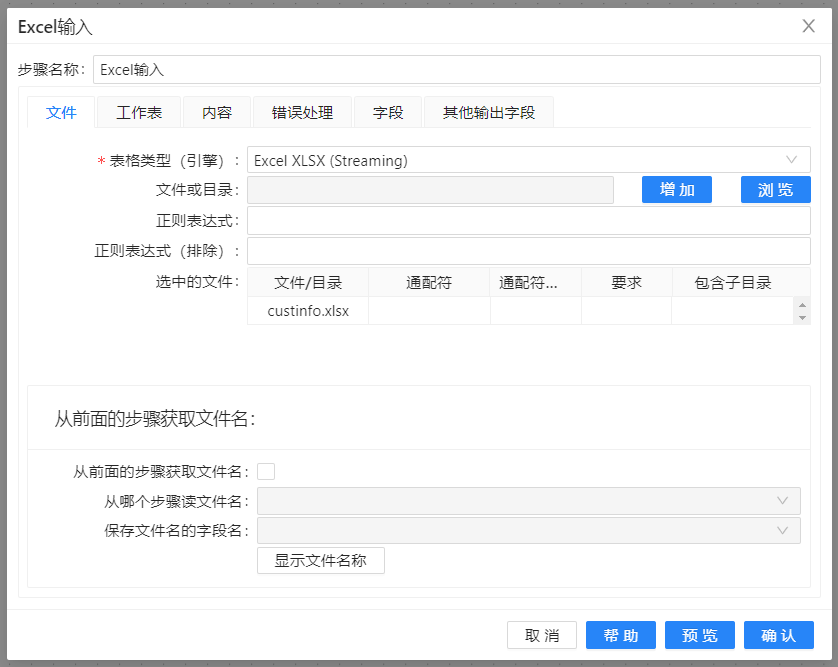
购房者对住房的价格、环境的优劣、小区物业的服务质量和户型上的合理性等诸如此类的问题会有选择上的困惑,使得做出购房决策难上加难。根据影响购房决策的因素,如年龄、性别、学历、月薪和家庭人数等数据,应用数据进行建模,这时可能需要对获取的数据进行过滤筛选。本案例中将获取到的购房者信息数据进行字段选择,得到想要关心的字段数据信息,具体操作如下: 1、新建转换,在“输入”中拖拽“Excel输入”组件至画布。双击组件,点上传文本数据选择上传的Excel文件,配置完成完成后, 配置如下图:
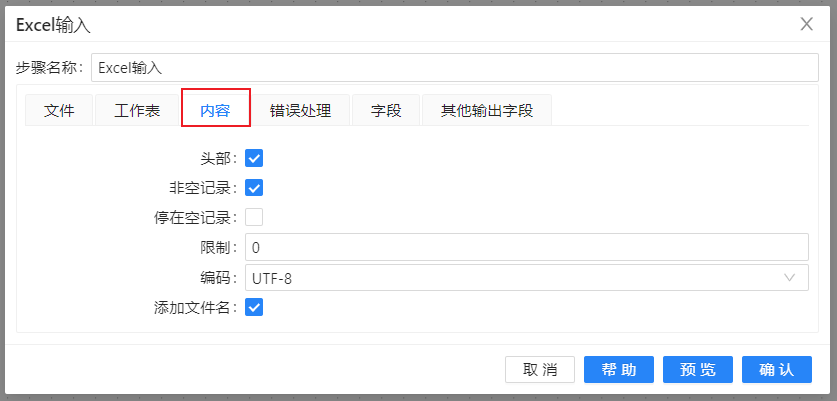
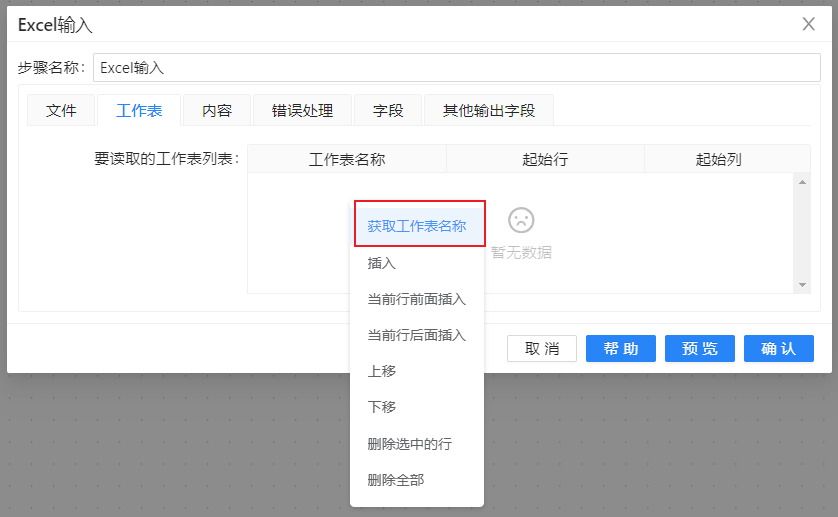
2、在最工作表栏目的下方点击“获取工作表名称”,如图:
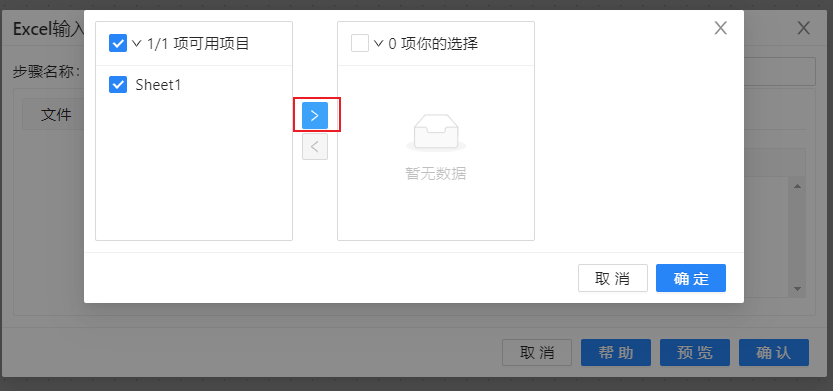
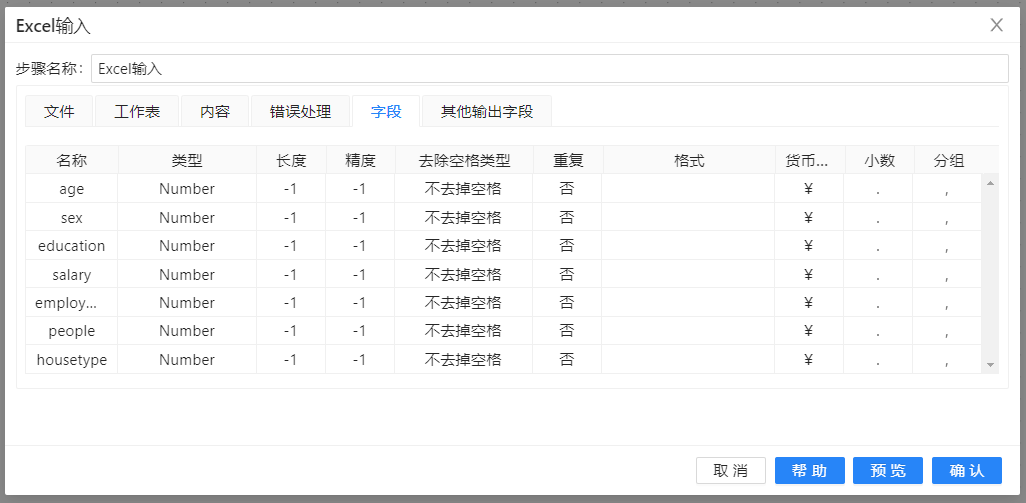
3、在字段栏目下方空白处,右键选择“获取来自头部的字段”,完成如图:
4、将“转换”中的“字段选择”组件和“流程”中的“空操作”组件拖拽至画布,并按顺序连接,选着连接线类型为主输出,如图:
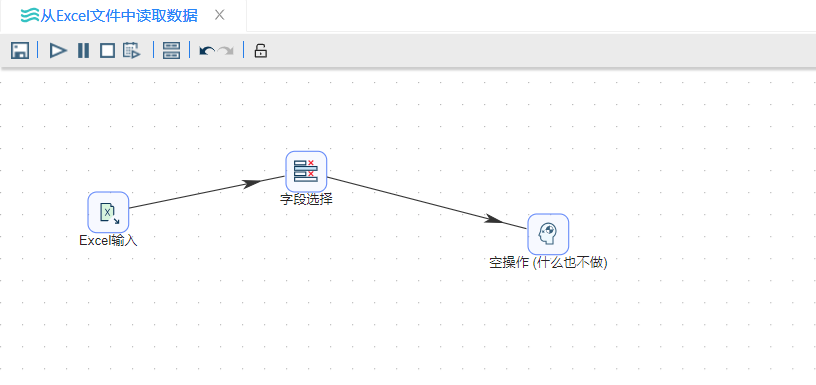
5、双击“字段选择”字段,在“选择和修改”栏目下的空白面版右键“获取字段”,并选择需要的字段,如下图所示:
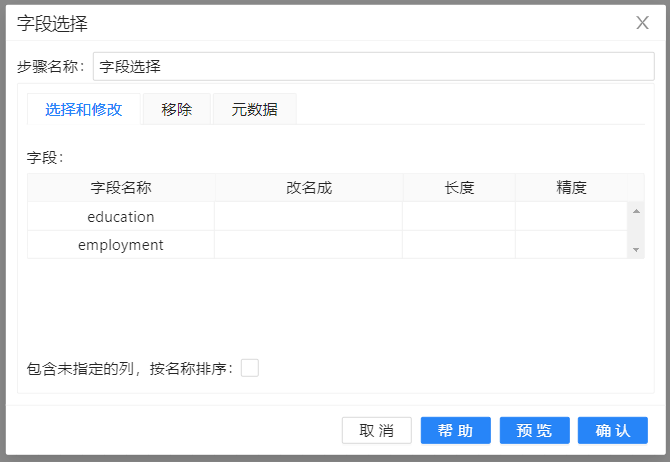
6、运行转换流,结果如下图所示:
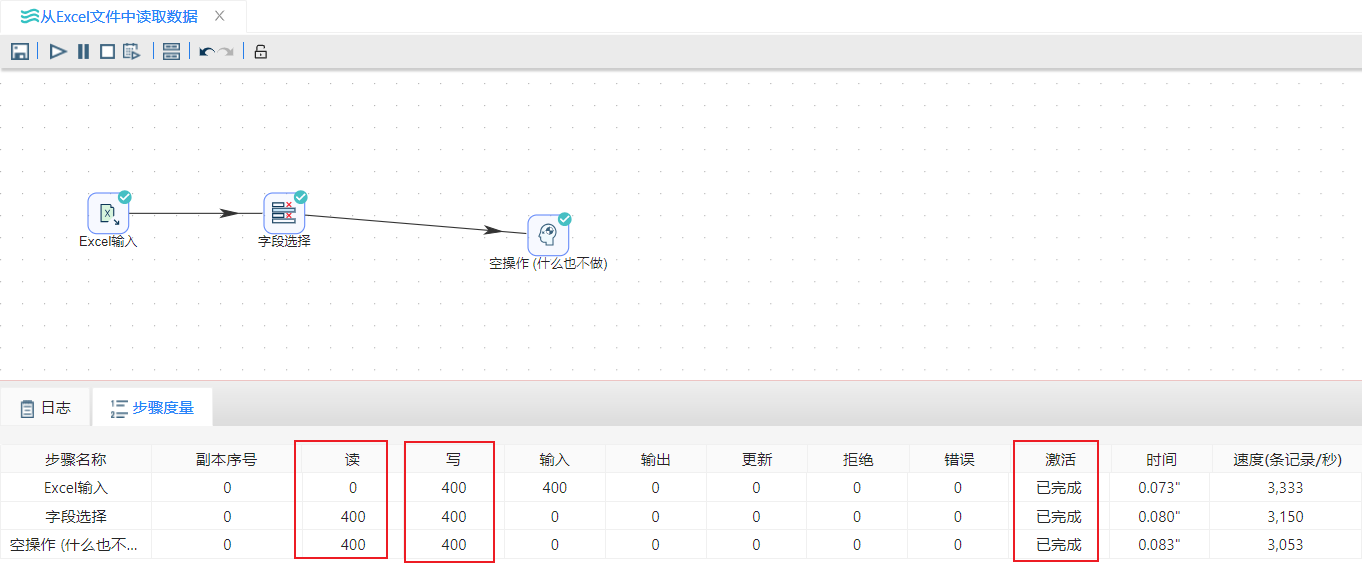
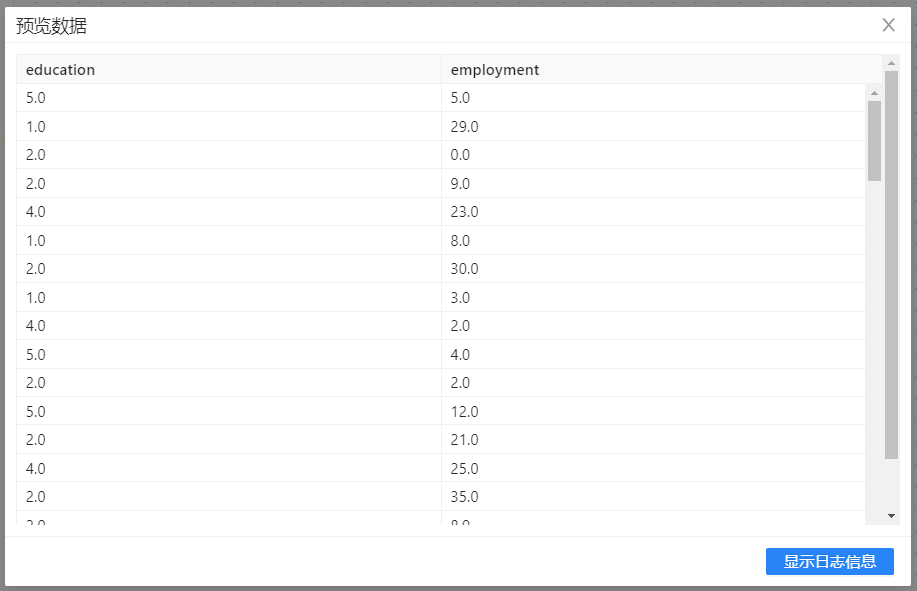
7、右键“空操作”组件,点击预览数据,结果如下图所示:
向数据库中插入数据
本小节主要展现了数据库方面的操作,使用 “插入/更新” 组件将文本文件“productist_LUX_200908.txt”中的内容更新到数据库中。在更新数据之前,要确保数据库中的表存在,具体操作如下: 1、在“输入”中拖入 “CSV文件输入” 组件,配置并预览数据,结果如下图所示:
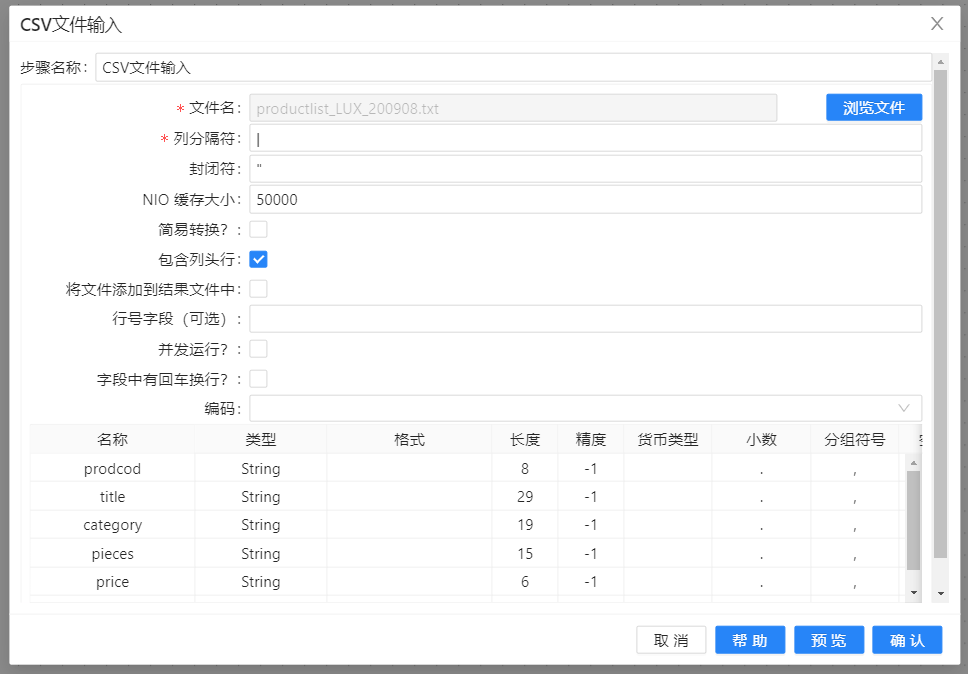
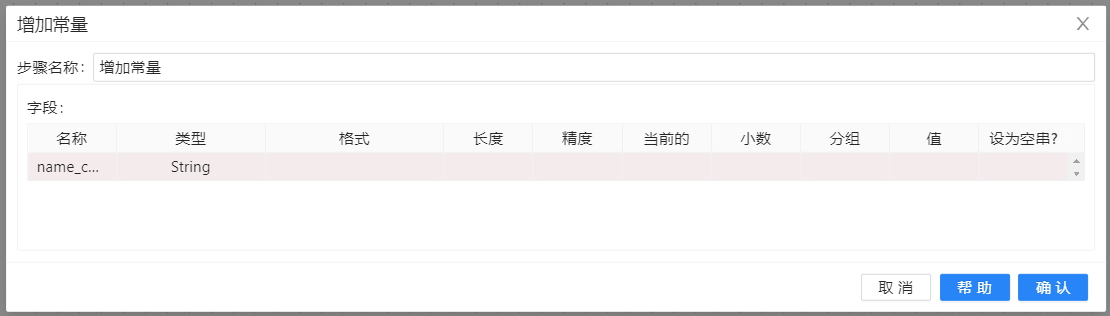
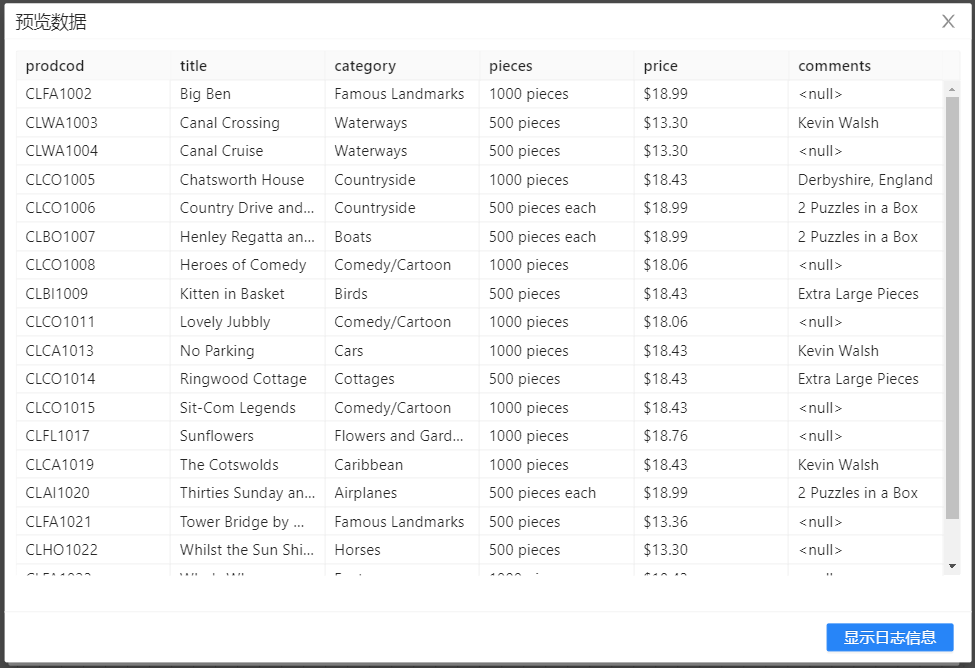 2、在“转换”中拖入**“增加常量”**组件并连接上一步骤,连接时若出现提示框,选择“主输出步骤”,双击该组件,点击“新增字段”,配置如下图所示:
2、在“转换”中拖入**“增加常量”**组件并连接上一步骤,连接时若出现提示框,选择“主输出步骤”,双击该组件,点击“新增字段”,配置如下图所示:
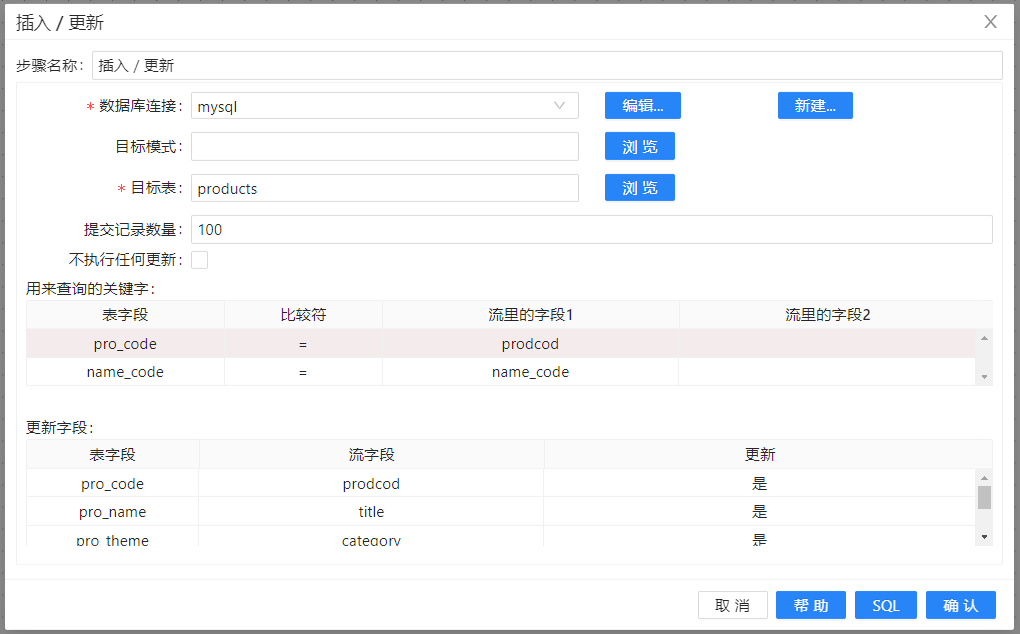
3、在“输出”中拖入 **“插入/更新”**组件并连接至上一步骤,双击 “插入/更新”,配置如下图所示:
4、选择**“查询字段”**标签,右键获取字段,配置如下图所示:
5、选择**“更新字段”**标签,右键获取字段,从下拉列表中修改字段名,配置如下图所示:
 6、在“应用”中拖入**“写日志”**组件并连接上一步骤,连接时若出现提示框,选择“错误输出步骤”,完整的转换视图如下图所示:
6、在“应用”中拖入**“写日志”**组件并连接上一步骤,连接时若出现提示框,选择“错误输出步骤”,完整的转换视图如下图所示:
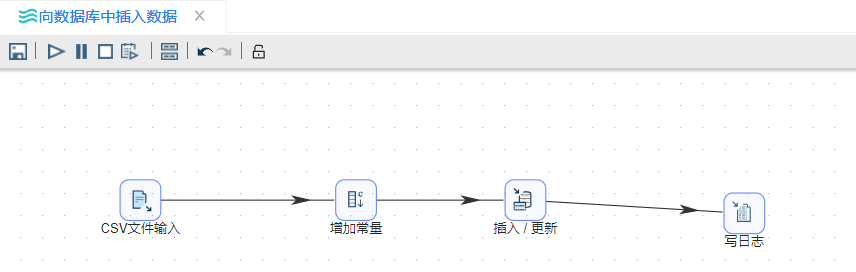 7、右击该组件并选择**“定义错误处理”**,在弹出的提示框中添入如下图所示内容:
7、右击该组件并选择**“定义错误处理”**,在弹出的提示框中添入如下图所示内容:
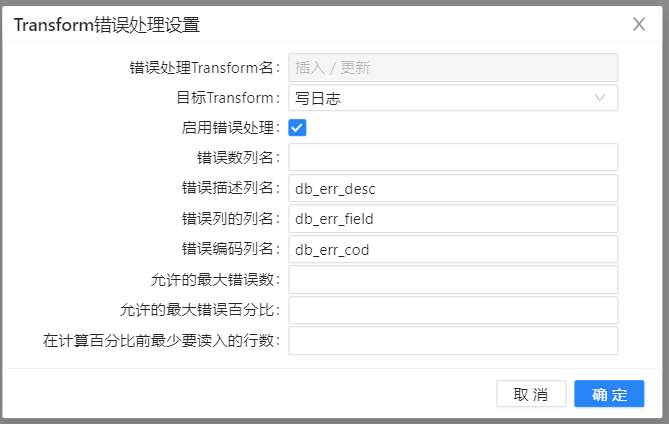
8、运行转换之前,可以先检查要更新表的数据,在运行转换之后再比较表的变化。运行转换结果如下图所示:


创建参数查询
本小节讨论集中在传统的关系型数据库, 从**“表输入”**步骤开始,接下来将解释在 Uniplore 中,这步骤里的参数和变量替换如何工作。目前,有两种参数化的查询方法:使用变量替换和使用参数,具体操作如下:
使用参数步骤
1、新建转换,将**“自定义常量数据”**组件�拖至画布,以此来添加一些数据。双击组件,在元数据中先定义is_active,created两列并选择好数据类型,并在数据中插入一条数据,如下图所示:
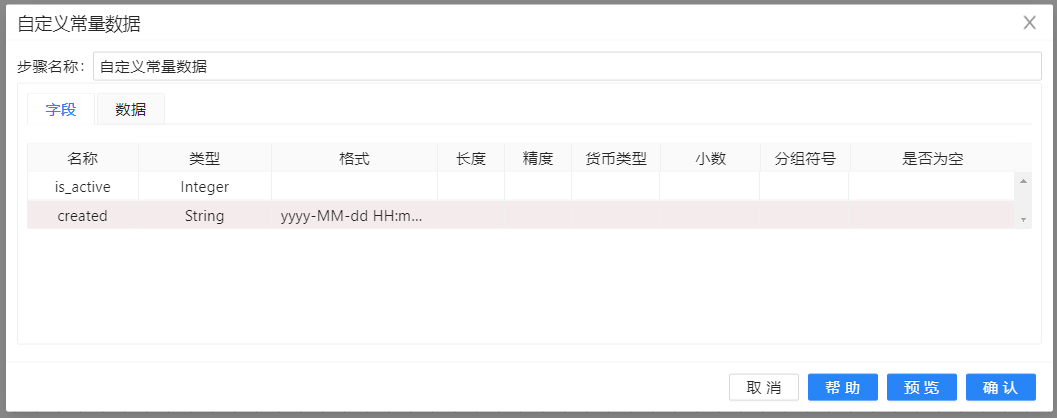
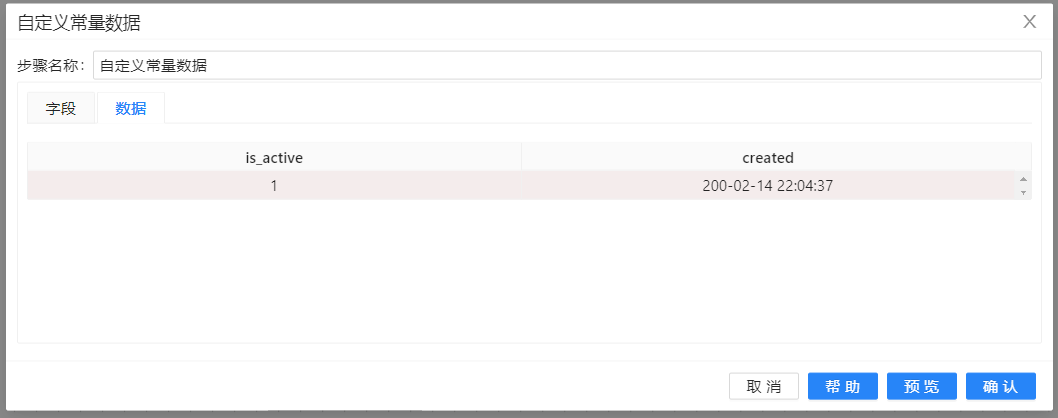
**“自定义常量数据”用来给“表输入”步骤提供一个或多个参数,这些参数是来替换“表输入”**步骤的SQL语句里的问号。
2、将**“表输入”组件拖至画布,双击组件,在弹出的对话框中选择在Uniplore中保存好的数据库连接,单击 ** “获取SQL查询语句”,在对应的文本框中即可获得对应表的查询。当然,也可以在文本框中编写自定义SQL查询语句。配置如下图所示:
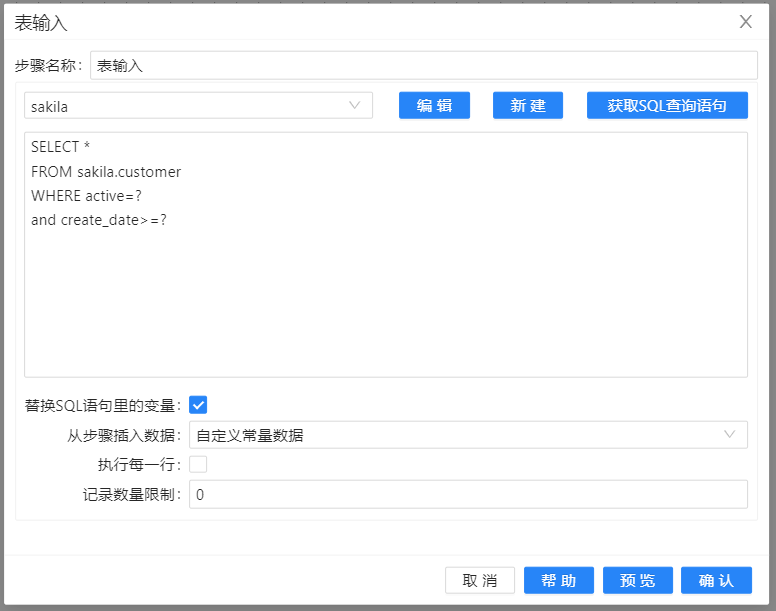
3、将**“空操作(什么也不做)”组件拖至画布,并按顺序连接。若提示选择步骤,依然选择“主输出步骤”**。完整转换如下图所示:
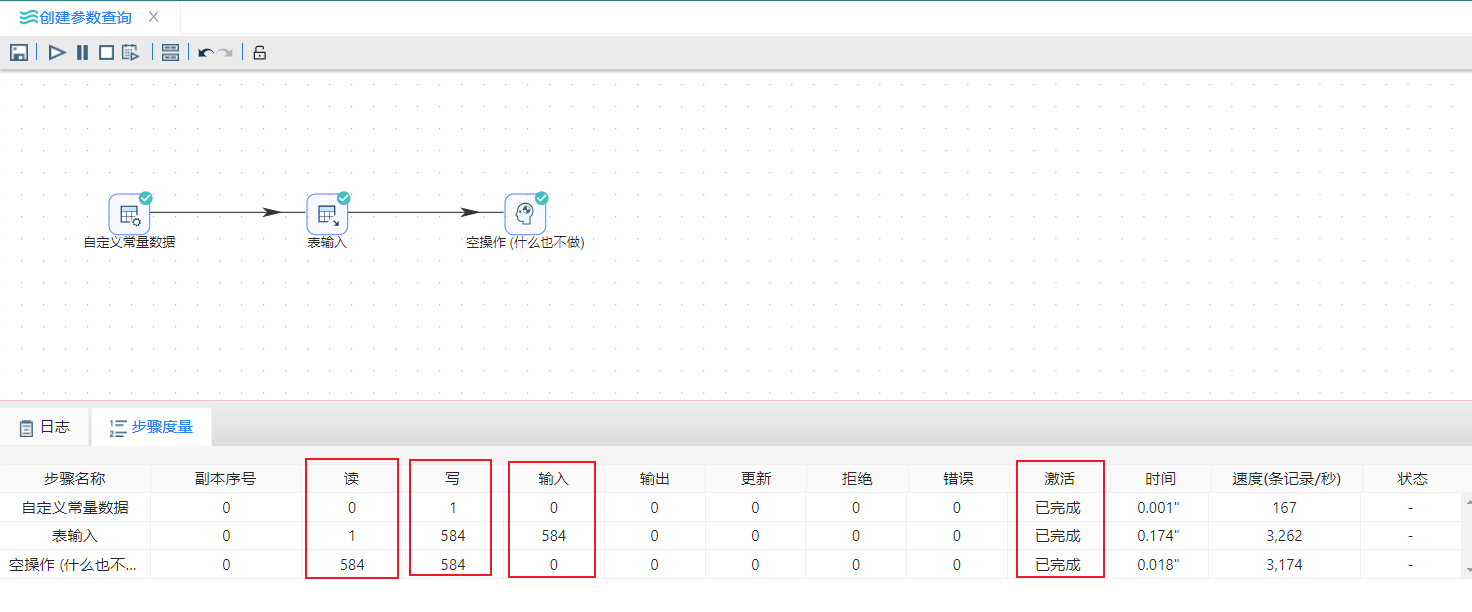
4、运行转换,结果如下图所示:
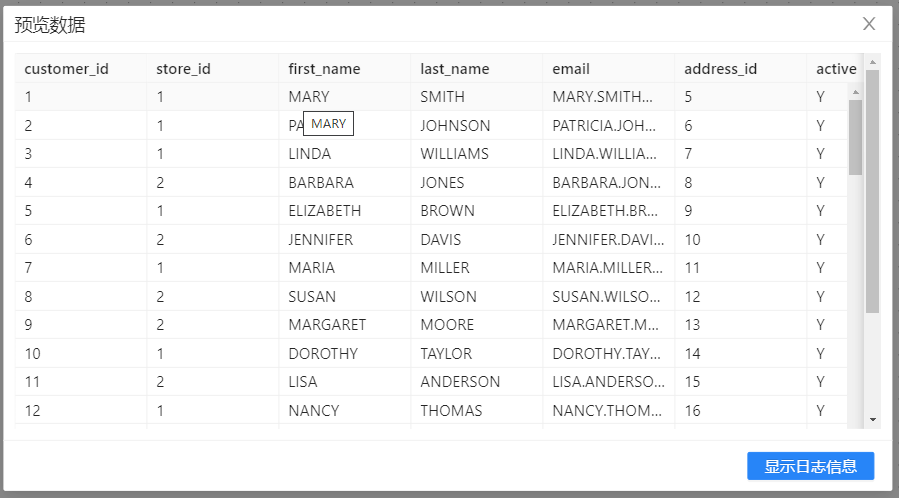
5、选中**“空操作(什么也不做)”组件,右击并选中“预览”**查看数据。结果如下图所示:
注:例子中的**“自定义常量数据”**步骤只用来演示,在实际使用中,要有其他步骤替换这个步骤。在CDC部分,能看到一个类似的例子。
使用变量步骤
变量要在使用变量的转换的前面进行某个转换设置,设置变量的转换往往是作业里的第一个转换。
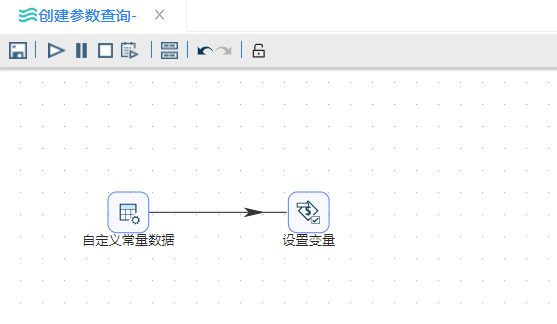
1、新建转换,名称为“设置变量”,并将**“自定义常量数据”**组件拖至画布,以此来添加一些数据。双击组件,在元数据中先定义is_active,created两列并选择好数据类型,并在数据中插入一条数据,如下图所示:
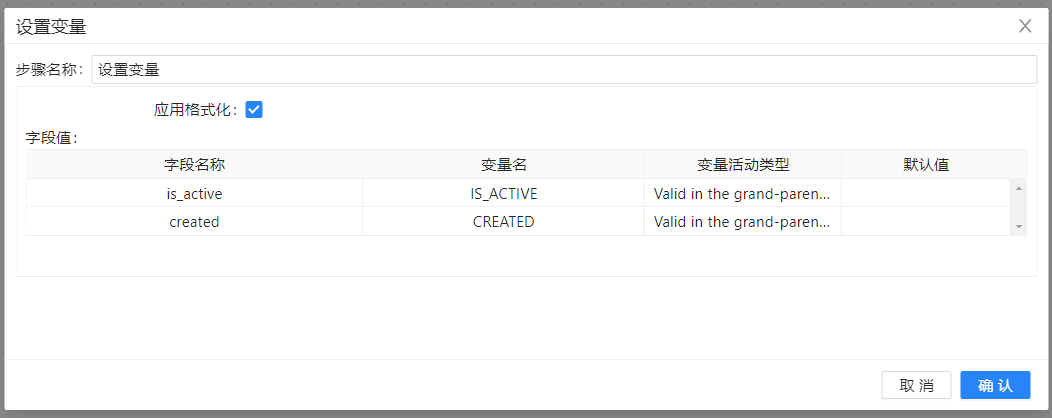
2、将**“设置变量”**组件拖至画布,双击组件,选择字段名称并填入相应变量名,设置变量活动类型,具体如下图所示:
在后面的**“表输入”**步骤里可以使用这些变量,查询里的变量名会被变量的值替换,使用变量的表输入步骤。
3、将两个组件按顺序连接,如下图所示:
4、保存转换后,再新建转换,命名为“使用变量的表输入”,并将“表输入”组件拖至画布,双击组件,在弹出的对话框中选择在Uniplore中保存好的数据库连接,单击 “获取SQL查询语句”,在对应的文本框中即可获得对应表的查询。当然,也可以在文本框中编写自定义SQL查询语句。配置如下图所示:
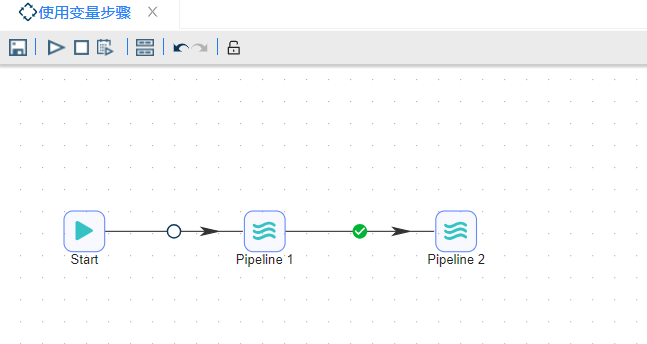
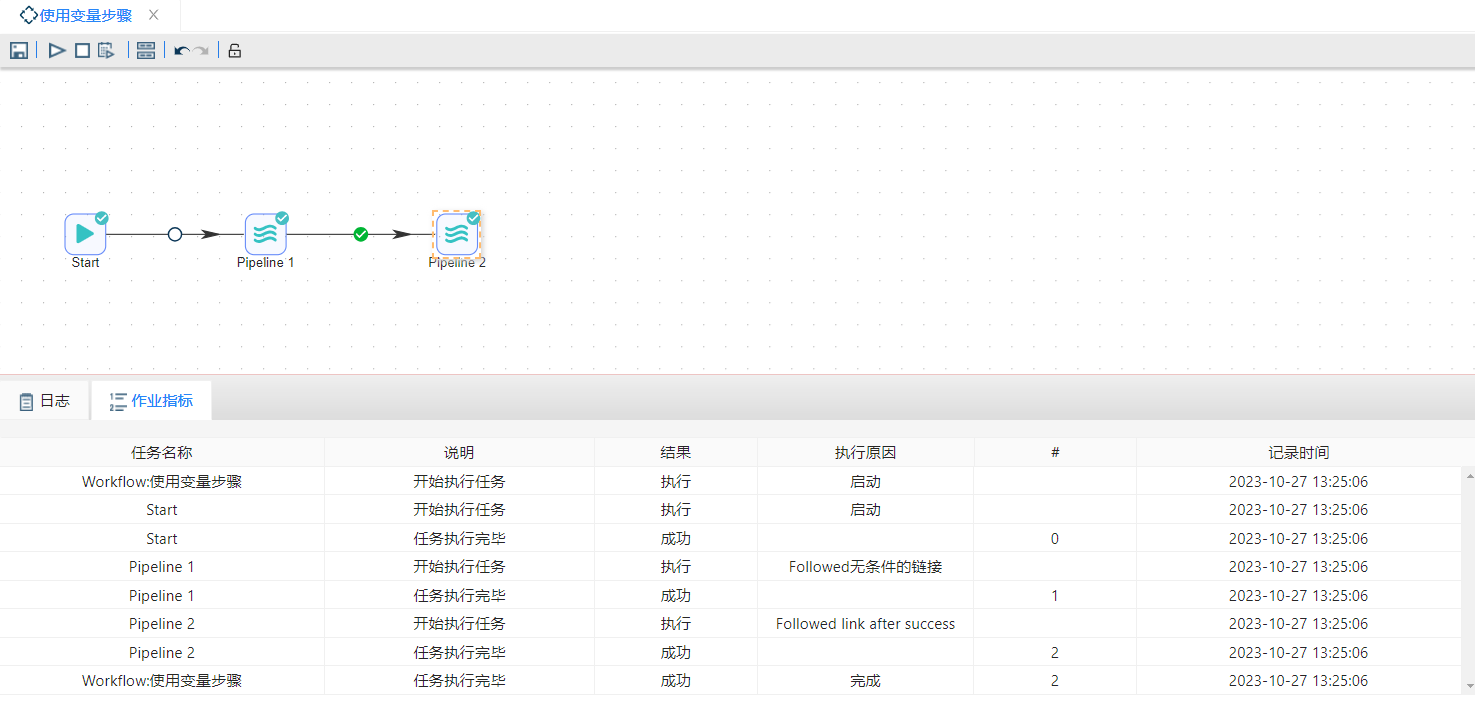
5、保存转换后,再新建作业,将**“START”**拖至画布,并将“Pipeline”两次拖至画布中,并按顺序连接,如下图所示:
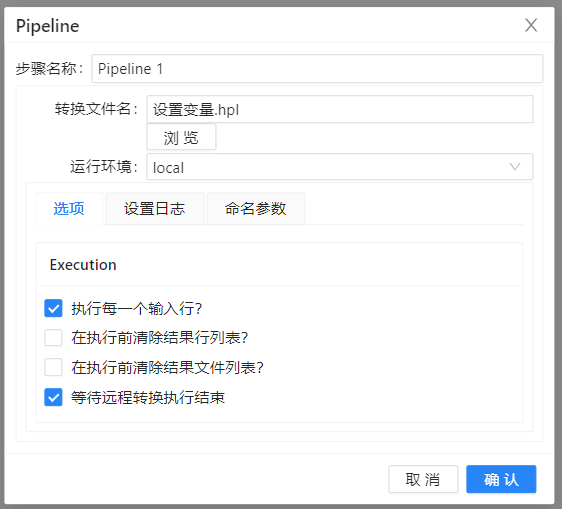
6、分别双击设置两个**“Pipeline”**,第一个转换是“设置变量”,第二个转换是“使用变量作为表输入步骤的参数”,具体设置如下图所示:
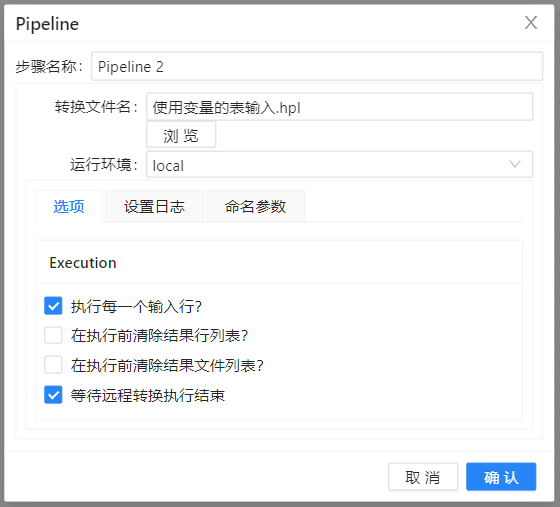
7、运行转换,结果如下图所示:
基于时间戳的CDC
- 什么是CDC?它的作用是什么?
ETL过程的第一步就是从不同的数据源抽取数据并把数据存储在数据缓存区。这个过程的主要挑战就是初始加载的数据量大和比较慢的网络延迟。在初始加载完成后,不能再把所有数据重新加载一遍。我们只需要抽取变化的数据。识别出变化的数据并只抽取这些变化的数据称为变化数据捕获(Change Data Capture)或CDC。
- CDC种类的划分
1、侵入性的(指CDC操作可能会给源系统带来性能的影响)
- 基于时间戳的CDC:这种方法至少需要一个更新时间戳,但最好有两个时间戳:一个插入时间戳(记录什么时候创建)和一个更新时间戳(记录什么时间最后一次更新)。
- 基于触发器的CDC
- 基于快照的CDC
2、非侵入性的
- 基于日志的CDC
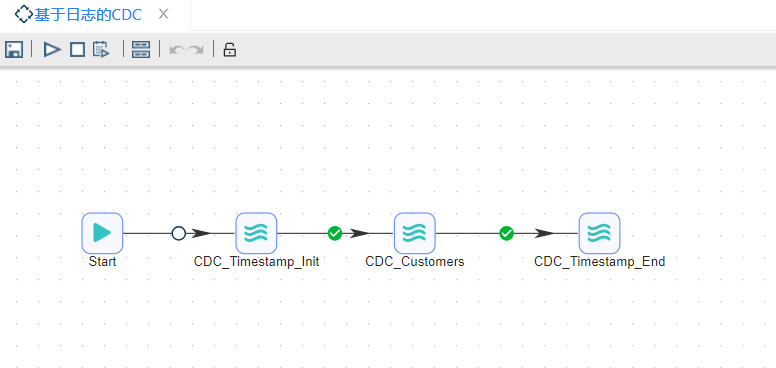
本小节将介绍的是一个包含了三个转换的作业,第一个转换获得当前时间并更新current_load时间戳,第二个转换从customer表中获得位于last_load时间戳和current_load时间戳之间的增量数据,第三个转换将current_load时间戳赋值给last_load时间戳,更新数据的最后一次更新时间,连接如下图所示:
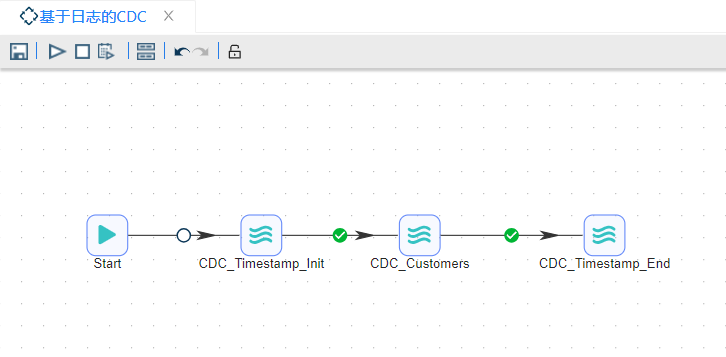
具体操作如下:
CDC_Timestamp_Init.hpl
转换的总览如下图所示:
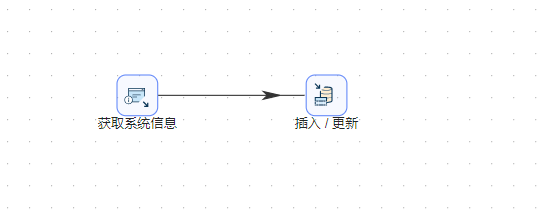
1��、新建转换,首先我们需要获取当前执行数据更新任务的时间:从输入栏中拖动“获取系统信息”步骤,如下图所示:
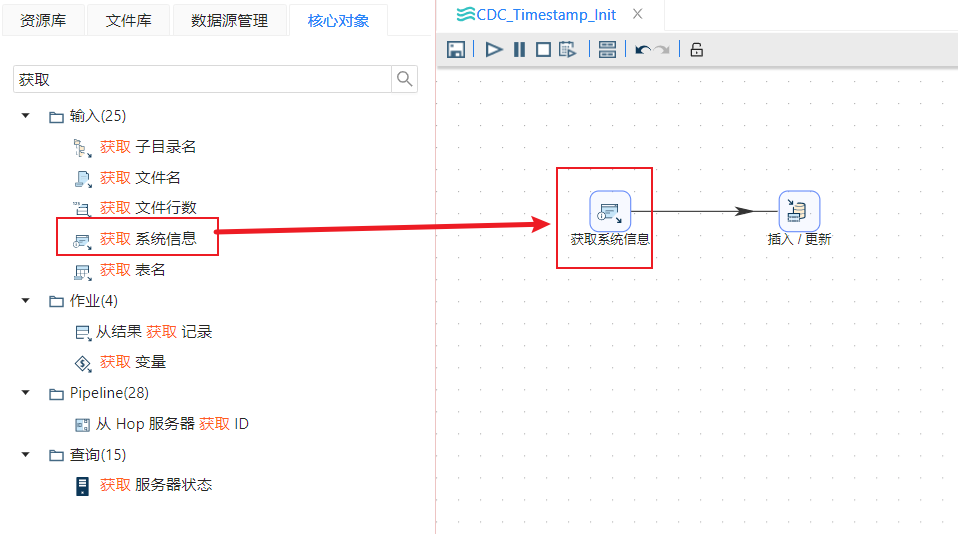
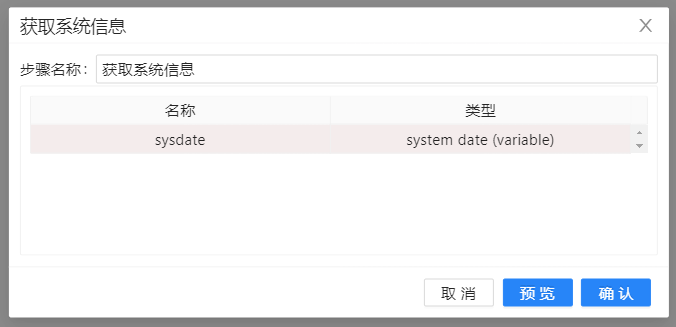
2、双击组件进行编辑,创建一个 “系统日期(可变)”类型的字段,字段名是sysdate。点击确定保存。如下图所示:
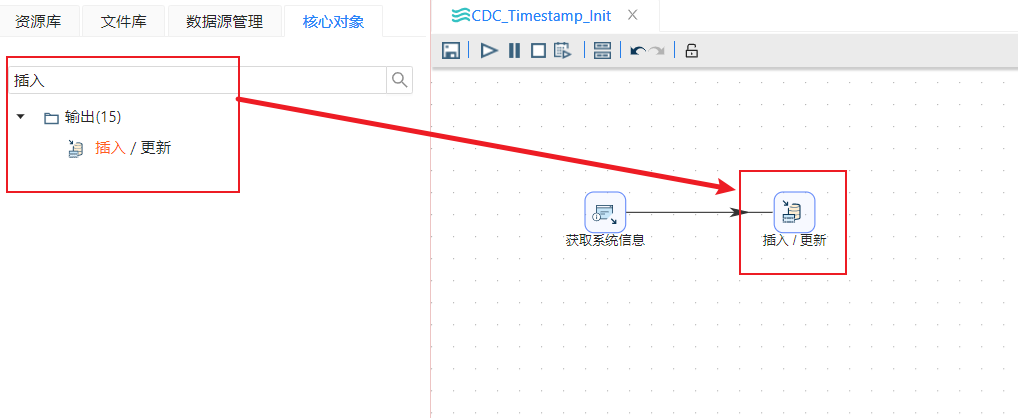
3、这个组件可以获取转换执行时的系统时间并记录在sysdate字段中,然后再创建一个“插入/更新 ”步骤,把“获取系统信息”步骤和“插入/更新”连接起来。如下图所示:
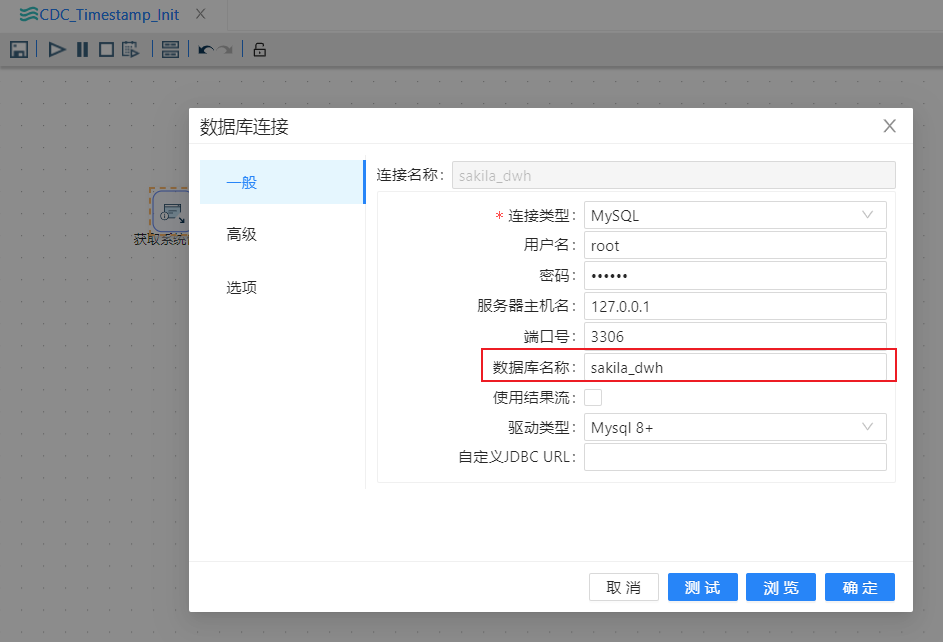
4、在“插入/更新”步骤的“基本配置”部分里,点击新建创建一个到sakila_dwh库的连接,点击确定保存,然后点击浏览选中数据库中的cdc_time表,如下图所示:
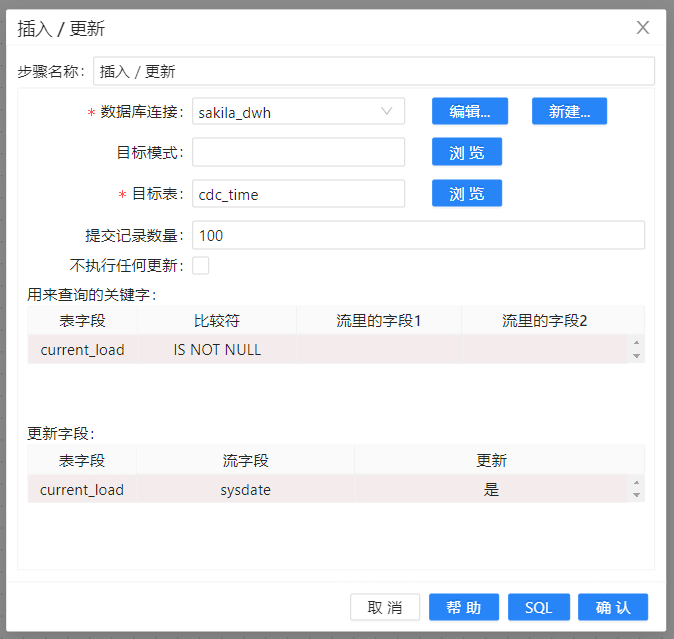
5、在“插入/更新”步骤的“更新字段”部分里,用数据流里的字段“sysdate”去更新表里的字段“current_load”。另外还要设置查询字段部分,把表的“current_load”的条件设置为“IS NOT NULL”即可(不设置查询条件的话,步骤会报错)。如下图所示:
6、转换执行成功后,刷新sakila_dwh库中的”cdc_time表“会发现”current_load“字段已经更新为转换执行时的时间,如下图所示:

CDC_Customers.hpl
转换的总览如下图所示:
1、新建转换,这里需要两个表输入步骤,一个用来从cdc_time表中抽取时间,另一个从Customer表中抽取需要的数据。customer表中同样有插入时间和更新时间字段,要想从customer表中抽取出最新的数据,查询条件就应该这样写:
SELECT *
FROM customer
WHERE
(create_date >= ? AND create_date < ?)
OR
(last_update >= ? AND last_update < ?)
这里的四个参数需要通过上一个表输入步骤传递过来,另外再看查询条件,可以发现last_load和current_load分别出现两次。就是�说在第一个表输入步骤中,这些时间值需要被抽取出来两次。sql如下:
SELECT
last_load last1
, current_load cur1
, last_load last2
, current_load cur2
FROM cdc_time
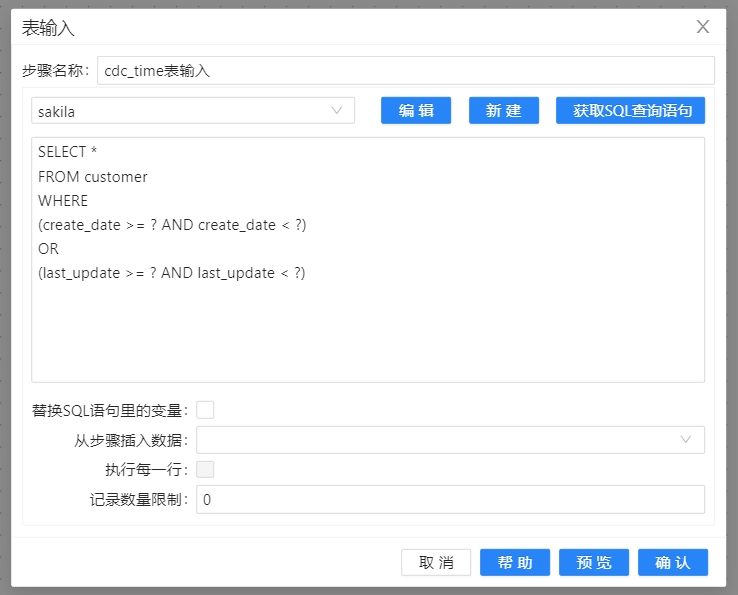
cdc_time表输入配置如下图所示:
2、再次拖动一个表输入步骤,和第一个表输入步骤连接起来,选中从cdc_time表输入步骤中插入数据,这样获取的就是位于两个时间戳之间的增量数据,如下图所示:
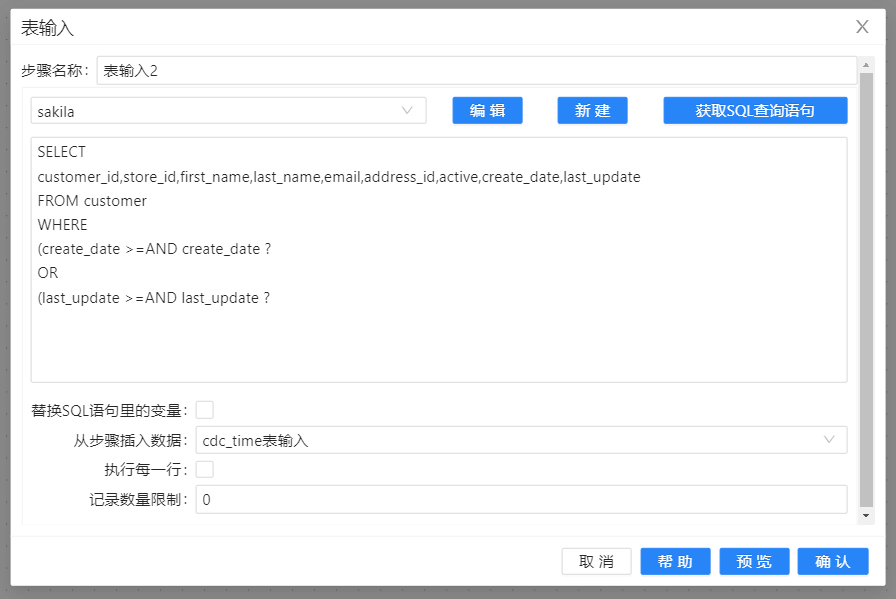
SELECT
customer_id,store_id,first_name,last_name,email,address_id,active,create_date,last_update
FROM customer
WHERE
(create_date >=AND create_date ?
OR
(last_update >=AND last_update ?
3、可以在表输入2步骤上右键预览CDC的结果,如下图所示:
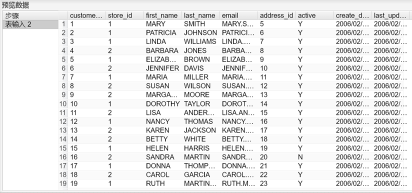
CDC_Timestamp_End.hpl
转换的总览如下图所示:
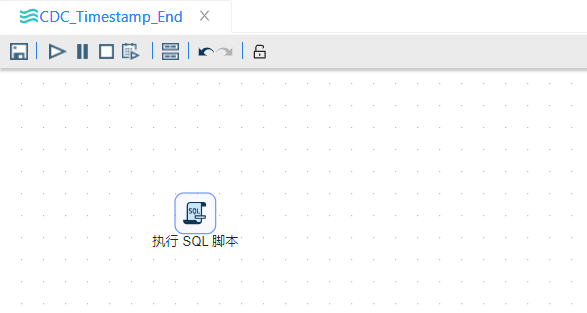
1、新建转换,如果转换中没有发生任何错误,要把current_load字段里的值复制到last_load字段里。如果转换中发生了错误,时间戳需要保持不变。把current_load字段里的值复制到last_load字段里需要“执行SQL脚本”步骤,脚本如下:
update cdc_time set last_load = current_load;
2、更新sakila_dwh库中的cdc_time表的last_load字段,配置数据库连接,写入要执行的sql语句(如果是多个语句要用分号分隔开)即可,如下图所示:
基于时间戳的CDC.hwf
1、在完成了前面的三个转换后,可以用一个作业将这三个转换连接起来。新建作业,START步骤是每一个作业的起点,一个作业必须要有一个START步骤,从START步骤到下一个步骤的跳上会有一个锁的标记,意思是不管怎样,这个步骤都将执行,后面的跳上会有一个绿色的√,意思是上一个步骤执行无误的话就会执行下一个步骤,如下图所示:
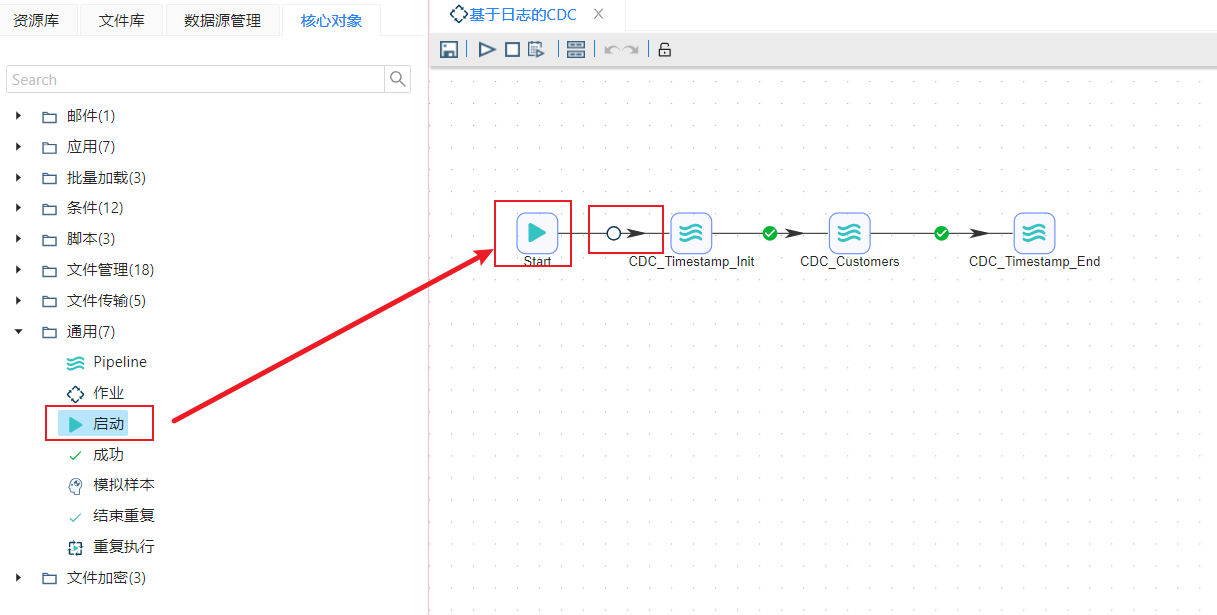
2、从左侧步骤栏中将转换步骤拖过去,双击编辑如下图所示,在转换文件名中选中之前完成好的转换即可,后面的转换也是如此,如下图所示:
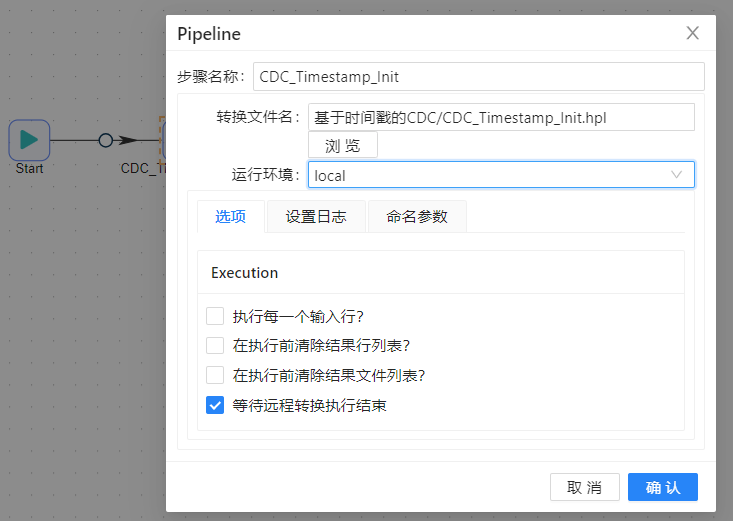
3、最后的结果如下图所示:
基于快照的CDC
如果没有时间戳,可以使用快照表,通过比较来获得变化。快照表是一次性抽取源系统中全部数据,把这些数据加载到数据仓库的缓冲区中,下一次需要同步时,再从源系统中抽取全部数据,并把全部数据也放到数据仓库的缓冲区中,作为这个表的第二个版本,然后再比较这两个版本的数据,找到变化。
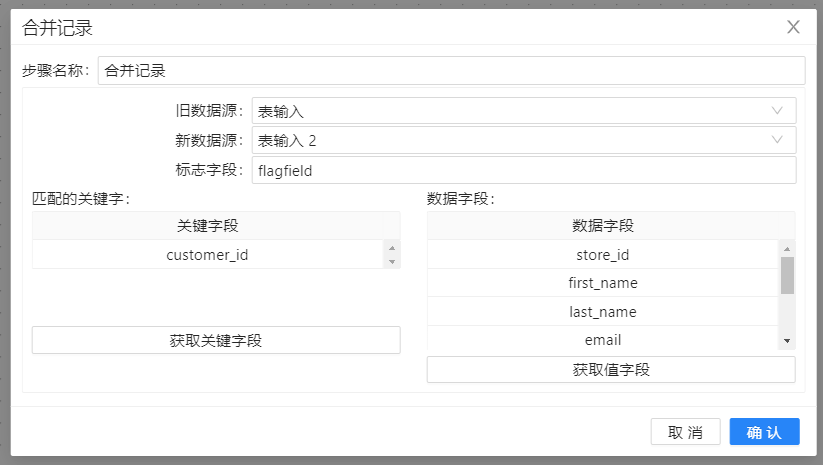
目前,大部分ETL工具都可以比较两个表之间的差异,并增加一个字段,人们一般更喜欢使用这种 ETL 功能而不是 SQL 语句来比较两个表的差异。Uniplore 里的**“合并记录”**步骤也有这个功能。这个步骤读取两个使用关键字排序的输入数据流,并基于数据流里的关键字比较其他字段。可以选择要比较的字段,并设置一个标志字段,作为比较结果输出字段。
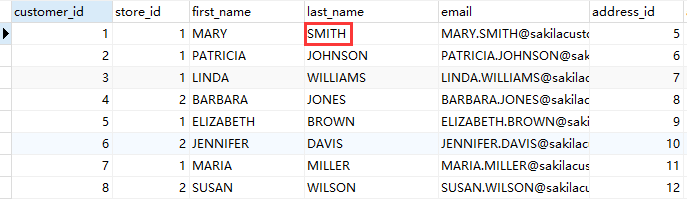
本节将利用 sakila 数据库里的表为例,先把这个表里的全部数据抽取出来,再修改源表里的几条记录,便可以创建基于快照的 CDC 转换。具体操作如下: 1、先把 customer 表里的全部数据保存在另一个数据库里的 customer2 表中,也可以直接保存在 sakila 库里。但在实际场景中,一般不允许直接保存在源数据库系统或数据仓库中。所以最好保存在缓冲数据库中。并对原�来的数据做一些修改,例如改变【last_name】字段,使一个用户失效,或添加新的用户,这些都要在源数据库系统上进行修改,修改【last_name】将“SMITH”改为“RIOS”, 如下图所示:
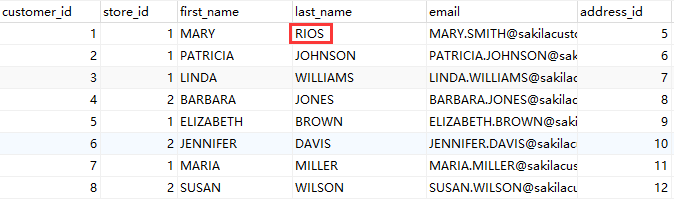
为了 Uniplore 能检测出删除的数据,可以在 customer2 表里增加一行,这行在源系统中不存在,这样可以模拟出在源系统中删除一条的情况;

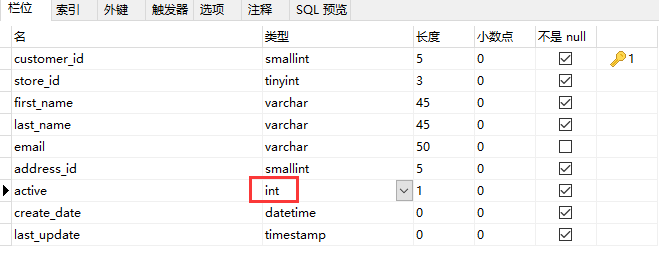
2、还需要将这些数据库表中的 active 字段修改为 int 类型,否则 Uniplore 将会自动识别成 boolean 类型,运行时会报错;
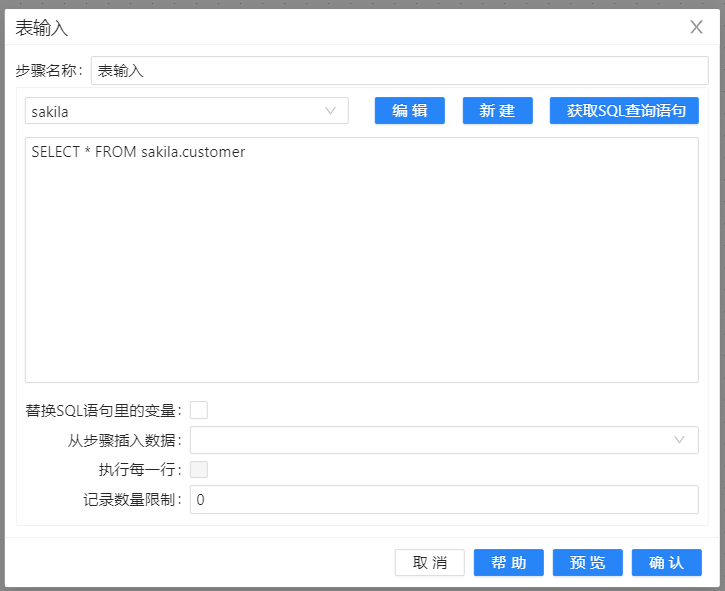
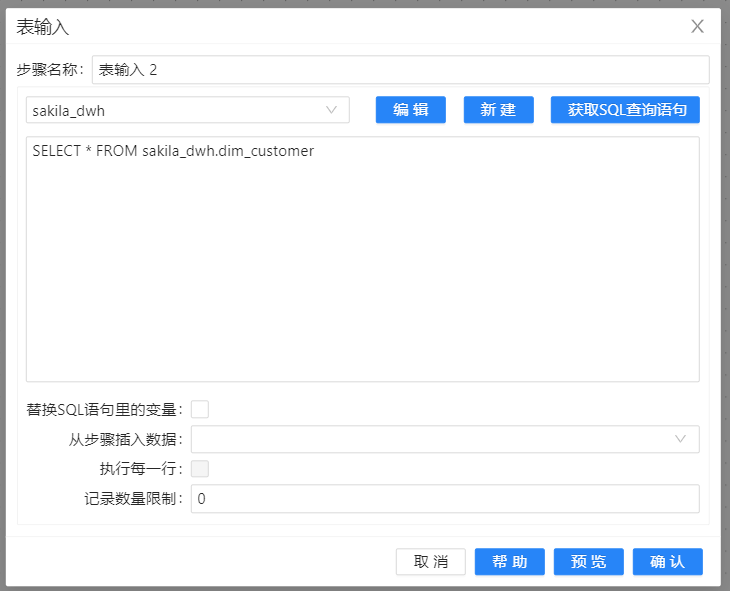
3、新建转换,将 **“表输入”**组件拖两次至画布,一个是 sakila 库的表输入,另一个是 sakila_dwh 库的表输入,并需要选中所有字段。双击组件,在弹出的对话框中选择数据库连接,单击 “获取SQL查询语句”,在对应的文本框中即可获得对应表的查询。当然,也可以在文本框中编写自定义SQL查询语句。配置如下图所示:
4、将**“合并记录”拖至画布,把两个“表输入”步骤都连接到“合并记录”**步骤。双击组件来选择哪个步骤是旧数据来源,哪个步骤是新数据来源,选择标志字段,另外设置关键字段和需要比较的字段。配置如下图所示:
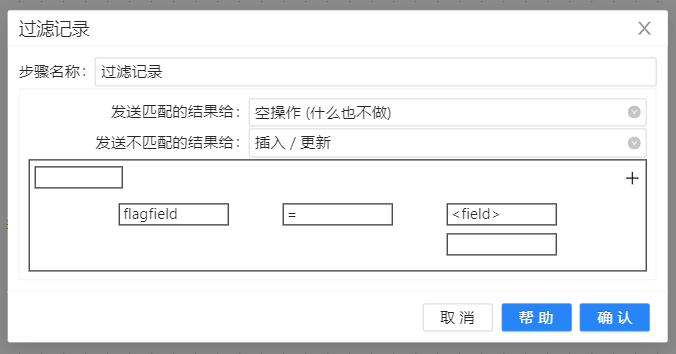
5、为了过滤没有发生变化的数据,需要在后面再增加一个过滤步骤。将**“过滤记录”拖至画布。双击组件,设置过滤条件为“flagfield=identical”,值是 String 类型,我们把所有没有变化的数据都发送到“空操作(什么也不做)”步骤,把新增、删除、修改的数据发送到“插入/更新”**步骤,根据操作对目标表进行更新。“过滤记录”配置如下图所示:
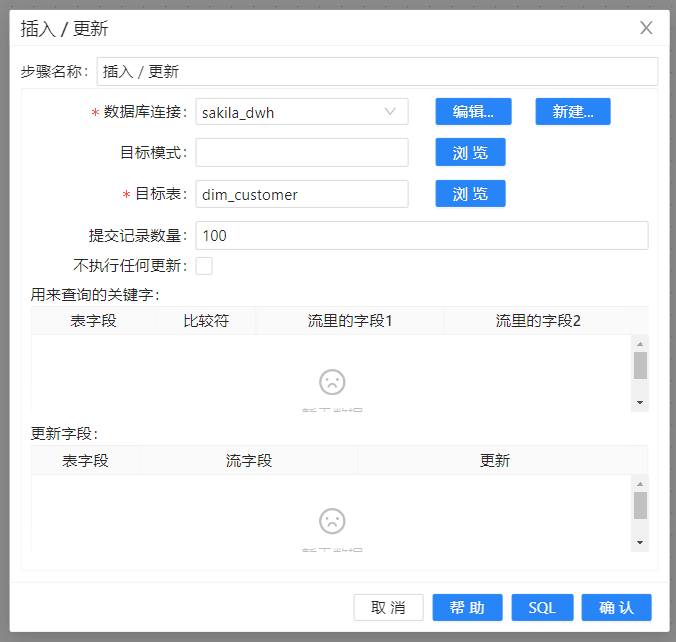
6、将**“插入/更新”**组件拖至画布,双击组件,选择缓冲数据库中另一张表,为了观察变化数据,配置如下图所示:
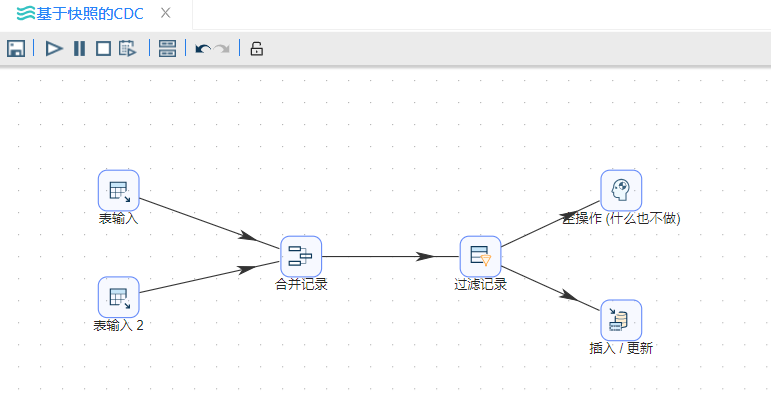
7、将**“空操作(什么也不做)”组件拖至画布,并按顺序连接。若提示选择步骤,依然选择“主输出步骤”**。完整转换如下图所示:
8、运行转换,结果如下图所示:
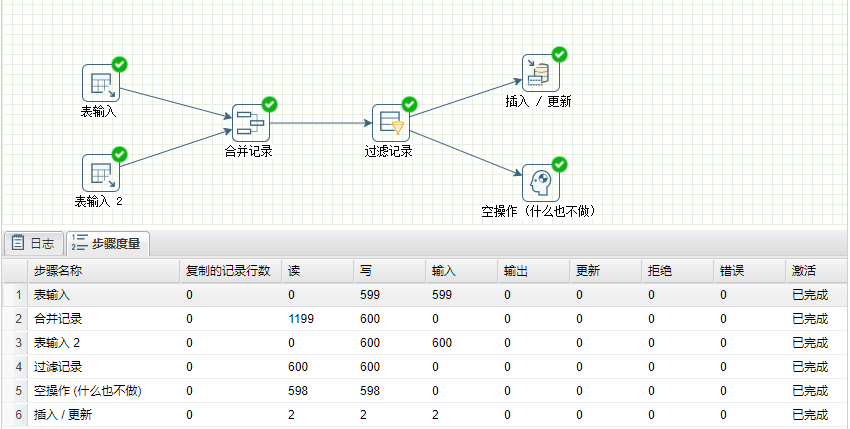
9、选中**“插入/更新”**组件,右击并选中“预览”,可以查看两个表中的变化数据,一条是被更改了【last_name】字段的数据,一条是模拟旧数据被删除的情况。结果如下图所示:
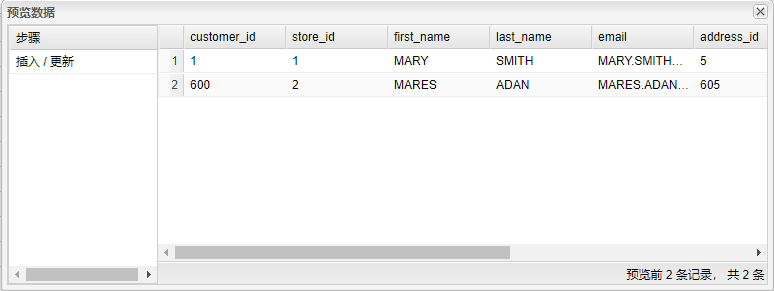
从本小节的例子中可以看出,基于快照的 CDC 可以检测到插入、更新和删除的数据,这是相对于基于时间戳的 CDC 方案的优点,但它的缺点是要大量的存储空间来保存这些快照。另外,在表比较大时,也会有比较严重的性能问题。因为会有这种性能问题,所以我们前面演示了如何使用 SQL 来做比较,数据库引擎的性能往往比 ETL 引擎的性能更好。之后还会介绍使用 Uniplore 在Data Vault模型下做CDC的例子(2.8Data Vault 管理案例)。