维度表处理
案例目的
通过本节内容的学习,介绍如何使用 UDI Studio 来管理维度表,尤其要了解 UDI Studio 的一些非常有用的功能,使用这些功能可以转换或生产维度表数据,并把这些数据加载到维度表里。
数据介绍
示例数据基于一个虚拟的 DVD 出租连锁店 Sakila,sakila 示例数据库的作者是 Mike Hillyer,他当时是 MySQL AB的技术文档工程师。自 sakila 示例数据库在2006年3月发布以来,便由 MySQL文档团队维护和销售。读者可以参考有关 MySQL 的文档来获得更多关于示例数据库的信息。也可参考 Uniplore 帮助文档里对 sakila 数据集的介绍2.7.1 sakila示例数据库和租赁业务星型模型。为了方便起见,读者可直接使用下方提供的 sakila 数据库 SQL 脚本。
其中,sakila-schema.sql 与 sakila-data.sql 用于创建 sakila 数据库,sakila_snowflake_schema.sql 用于创建演示中所用的雪花模型。在本示例中,系统从源数据库 sakila 抽取增量数据,然后添加到雪花维度表中。
生成代理键的两种方法
数据仓库最佳实践表明,原则上,维度表应该使用自动生成的无意义的整型数值作为代理键。但也有一些维度表不必遵循这个原则,但在本案例中,我们的代理键都遵循这个原则。
UDI Studio 提供了一些功能可以直接在转换里生成代理键,另外也支持通过数据库生成代理键。本节我们学习能生成代理键的步骤。
基于转换的第一种方式
下面介绍生�成代理键的第一种方法,该方法是使用“增加序列”和内部计数器生成代理键,工作流程如下所示:
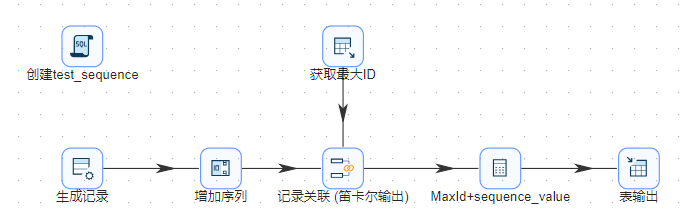
在运行该转换时,会在运行转换的初始化阶段,先执行 "创建test_sequence" 步骤里的 SQL 语句。这是一个用来执行 SQL 脚本的组件,里面的内容创建了一个名为 wy_test_sequence 的维度表。
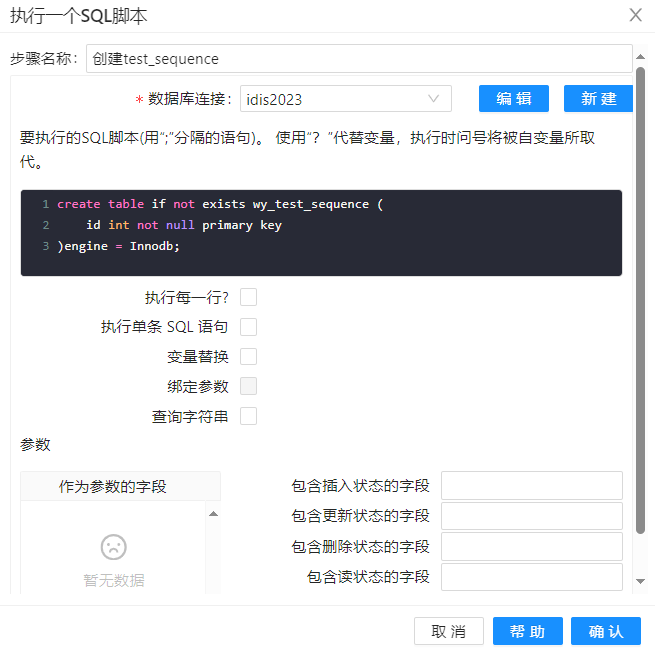
里面的 SQL 代码如下
create table if not exists wy_test_sequence (
id int not null primary key
)engine = Innodb;
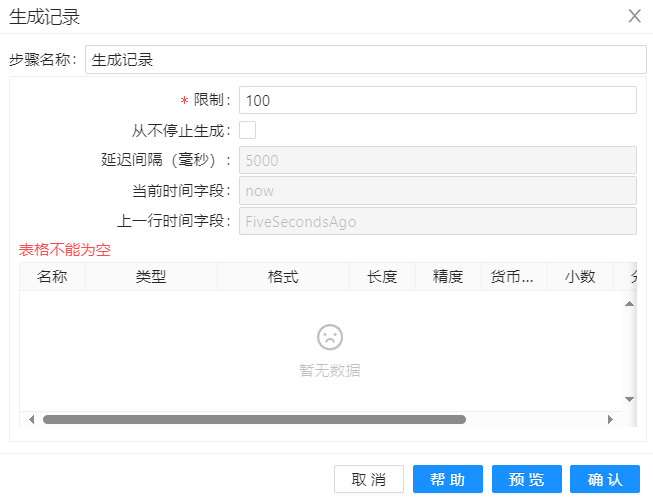
初始化阶段完成后,在“生成记录”步骤中生成了 100 行空记录,这些行代表了要加载到 "wy_test_sequence" 维度表里的数据行。
紧接着通过"增加序列"步骤,给数据流添加了一个 "sequence_value" 自增序列字段。
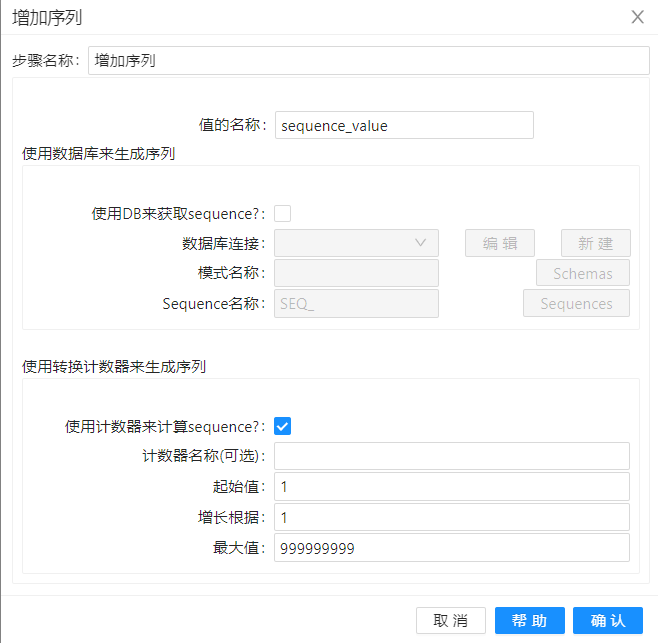
sequence_value 字段只是一些预备数据,还不��能直接作为代理键。每次转换运行时,这些序列的起始值都是 1,和数据库里已有数据的代理键重复。为解决这个问题,需要把序列值和表里的最大值相加。我们使用一个"表输入"组件来获取 test_sequence 表里的代理键最大值。
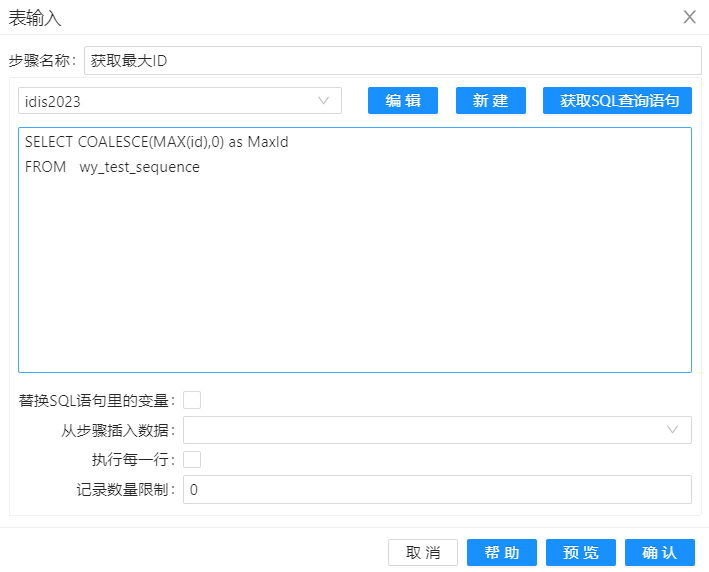
表输入步骤里的SQL语句如下,如果维度表中存在数据返回最大 id,如果维度表中无数据返回为 0:
SELECT COALESCE(MAX(id),0) as MaxId
FROM wy_test_sequence
此时用 “记录关联(笛卡尔输出)” 可在生成的数据集中增加一列 MaxId, 右键点击【预览】,可得下图:
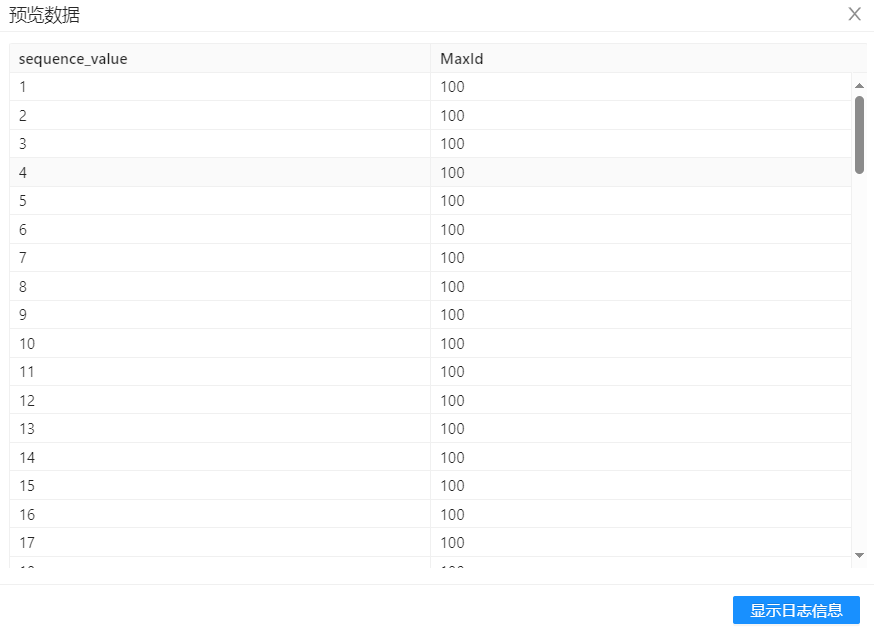
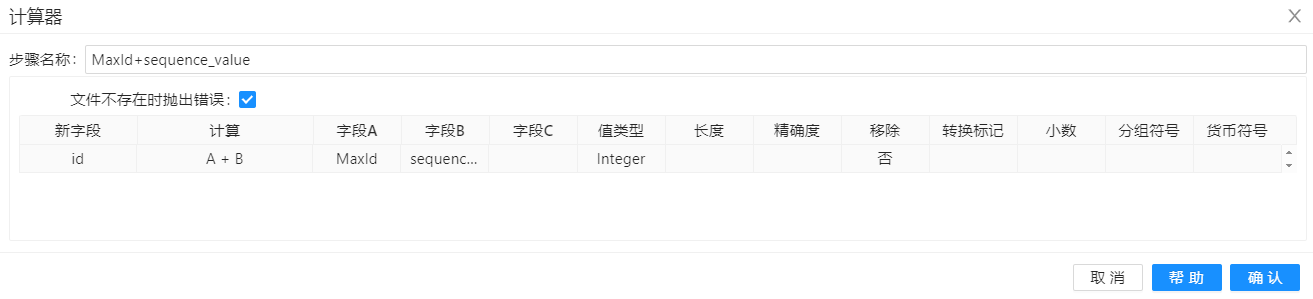
下一个步骤是利用"计算器"组件将 sequence_value 与 MaxId 进行相加,这样就可以得到真正的代理键了。计算器组件配置如下所示:
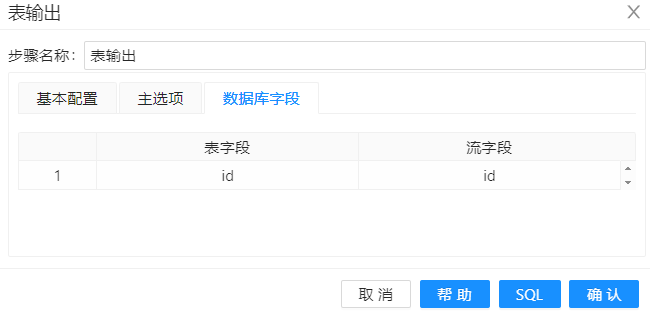
最后一步是"表输出",用来加载 wy_test_sequence 表,代表了加载维度表。在表输出中首先选择目标表为 "wy_test_sequence", 并勾选指定数据库字段
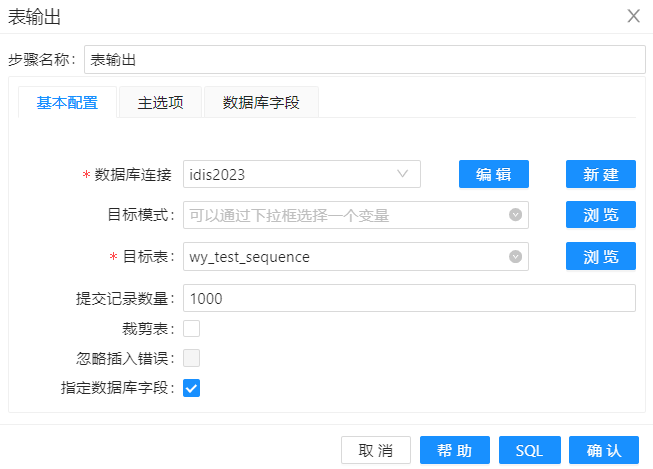
另外在数据库字段中,建立表字段与流字段与流字段的对应关系。
点击运行后,使用数据库连接工具查看 wy_test_sequence 中所加载的数据。

这正是我们期望的结果,由于 wy_test_sequence 中没有数据,所以代理键中1开始。
基于作业的第二种方式
在方法一中,通过获取维度表中代理键的最大值,并将最大值和现有序列相加来解决序列的偏移问题。尽管这个方法在这个转换里运行得很好,但在现实中,这个转换却有变得混乱的风险,因为有很多步骤和真正的加载维度表无关。除此之外另有一个缺点,最大值+现有序列Id 的做法给每个数据行都做了运算,降低了转换的整体性能。
除了方法一,还有一个方法能让“增加序列”步骤只产生新的键值。而且在一开始就可以生成正确的键值而不用一遍一遍地给每一行计算键值。这种方法需要“增加序列”步骤的“起始值”在初始化时是正确的值。所以要动态配置“起始值”,整个过程不是很直观,但是这种方法使主转换比较清晰,而且会提高一些性能,其作业流程如下:
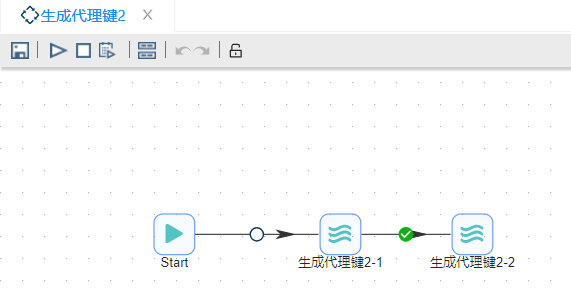
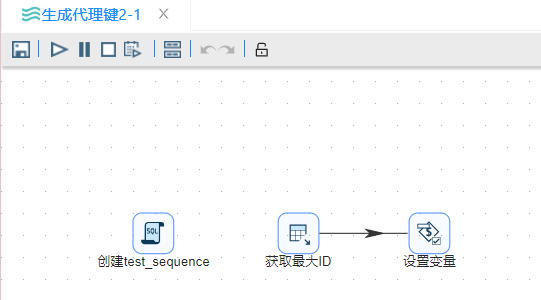
通过一个"**START"**连接两个 转换 组件,其中"生成代理键2-1" 的内容如下:
"生成代理键2-2" 的内容如下:
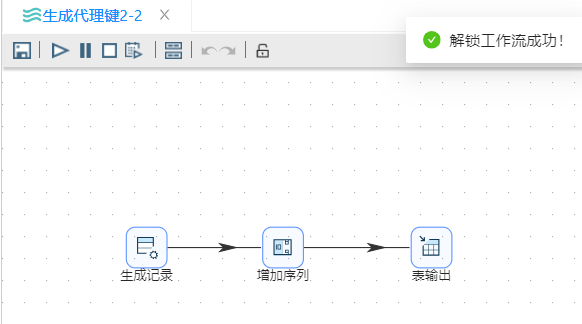
该方法与基于作业�的第一种方式不同的地方在于,在转换"生成代理键2-1"中使用了"设置变量"组件。将最大ID传递给了下一个转换"生成代理键2-2",并在"增加序列"中设置该变量为起始值,来生成的代理键。
需要留意的是,在转换"生成代理键2-1"中的"设置变量"中需要设置"字段名称"、"变量名"、"变量活动类型"三个信息,设置如下:
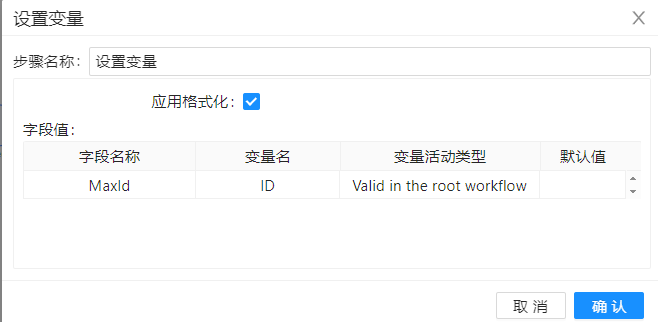
另外在转换"生成代理键2-2"中"增加序列"将最大ID设置为起始值,配置如下:
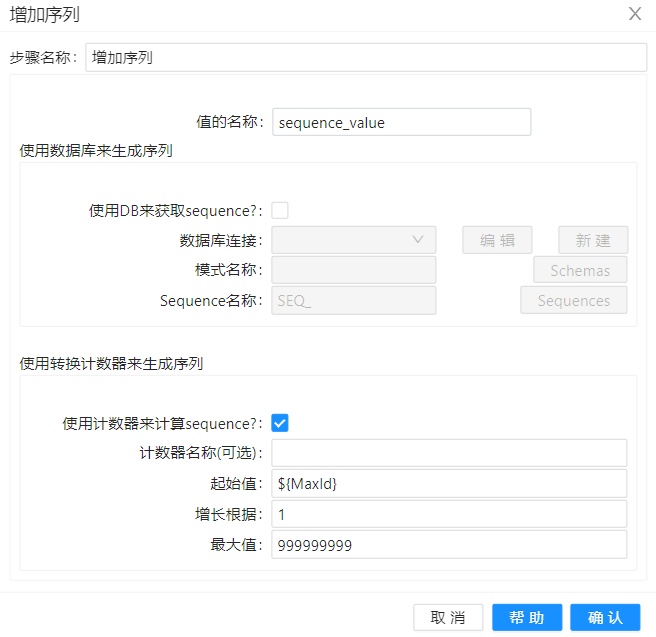
其余组件的配置与基于转换的第一种方式一致。
维度表的自顶向下加载
使用数据介绍中的 sakila_snowflake_schema.sql 脚本创建的雪花维度表如下所示:
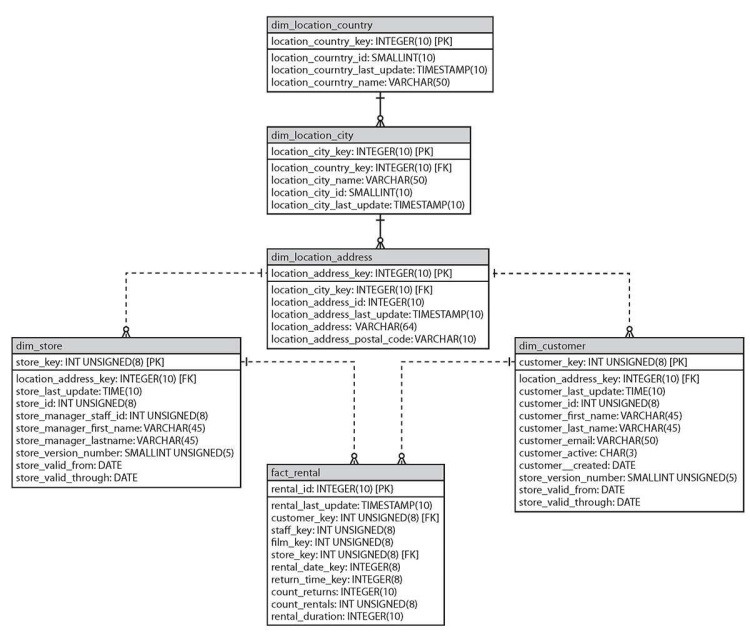
雪花状的地址维度包括三个表:dim_location_address、dim_location_city和dim_location_country。dim_location_address表是主维度表。从依赖关系上,不难发现这三个维度之间的加载应该满足这样的顺序: dim_location_country -> dim_location_city -> dim_location_address 。
作业示例
在处理自顶向下逐级加载的维度表时,一种较好的方法是把每个单独的维度表放在一个转换里。每个转换都抽取该维度表所代表层次的增量数据。如果要加载的维度表不是维度的顶层,还需要使用一个或多个查询步骤从上一层次中获取代理键。 以下是解决 dim_location_country -> dim_location_city -> dim_location_address 加载顺序的作业的流程结构:
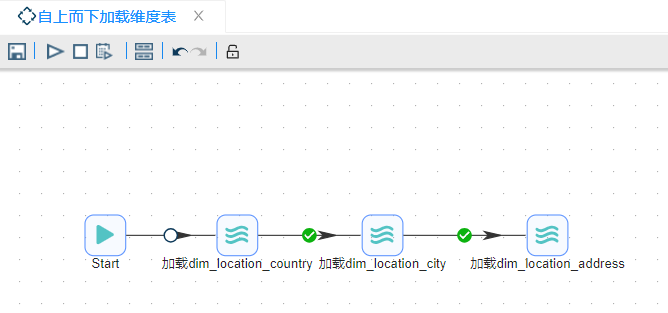
作业中从 START 组件开始,依次加载运行转换 "加载 dim_location_contry"、"加载 dim_location_city"、"加载 dim_location_address"
其中转换 "加载 dim_location_contry" 的转换流程如下
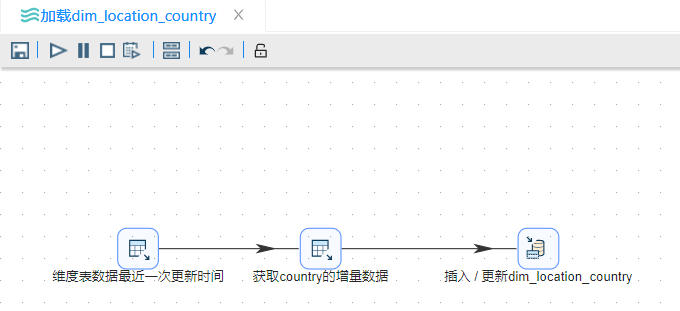
"加载 dim_location_city"的转换流程如下:
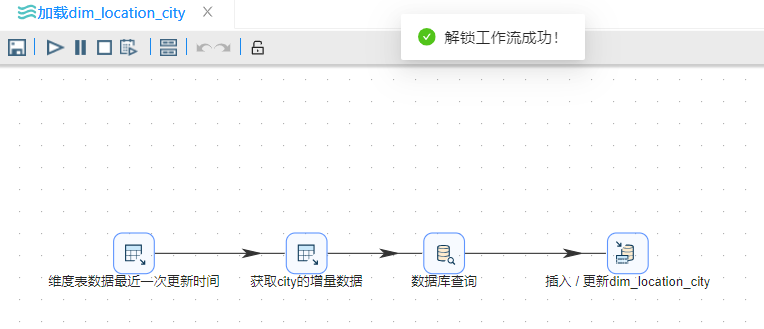
"加载 dim_location_address"的转换流程如下:
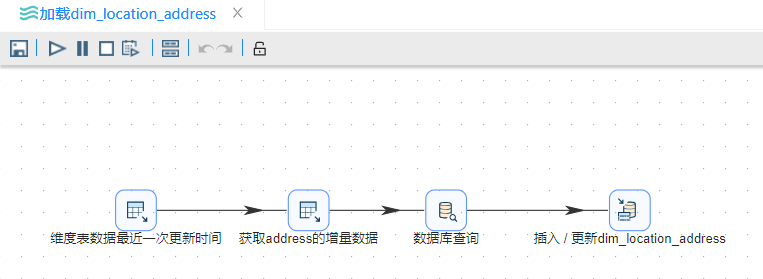
在"加载 dim_location_contry"、"加载 dim_location_city" 和 "加载 dim_location_address" 转换中利用"表输入"组件来获取维度表中数据的最新一次更新时间。因其逻辑相同,仅仅以 "加载 dim_location_address" 组件来做展示。
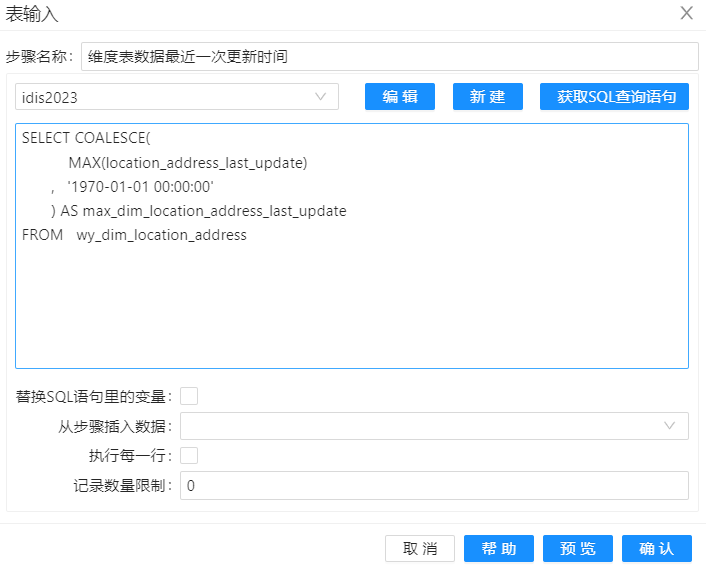
如果 dim_location_address 中没有数据,那么返回 '1970-01-01 00:00:00' 其中的 SQL 代码如下所示。
SELECT COALESCE(
MAX(location_address_last_update)
, '1970-01-01 00:00:00'
) AS max_dim_location_address_last_update
FROM wy_dim_location_address
接下来就是使用表输入,根据 "维度表数据最近一次更新时间" 的结果,来从事实表中获取对应的增量数据,组件配置如下图所示:
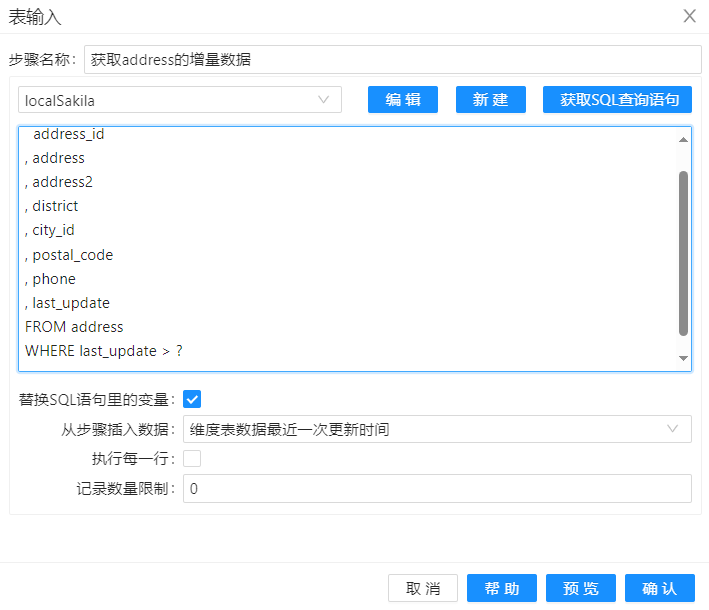
只筛选出事实表中新增的数据,其中的 SQL 代码如下
SELECT
address_id
, address
, address2
, district
, city_id
, postal_code
, phone
, last_update
FROM address
WHERE last_update > ?
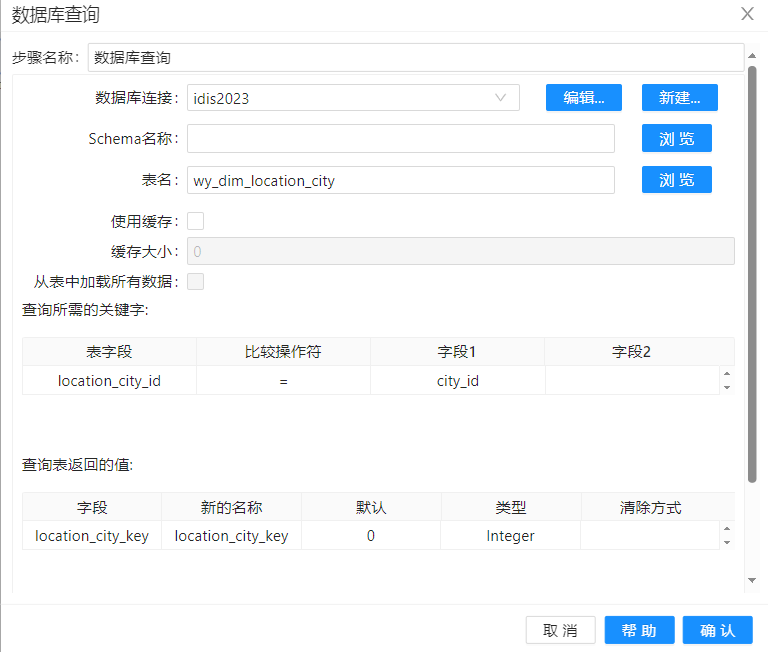
接下来就是要将筛选出的增量数据插入到维度表中,此处 "加载 dim_location_city" 和 "加载 dim_location_address" 中使用"数据库查询"组件的目的主要是保证数据的一致性。确保 dim_location_address 所处的 city 存在与 dim_location_city 中,同时也确保 dim_location_city 所处的 contry 在 dim_location_address 中。以 "加载 dim_location_address" 为例子:
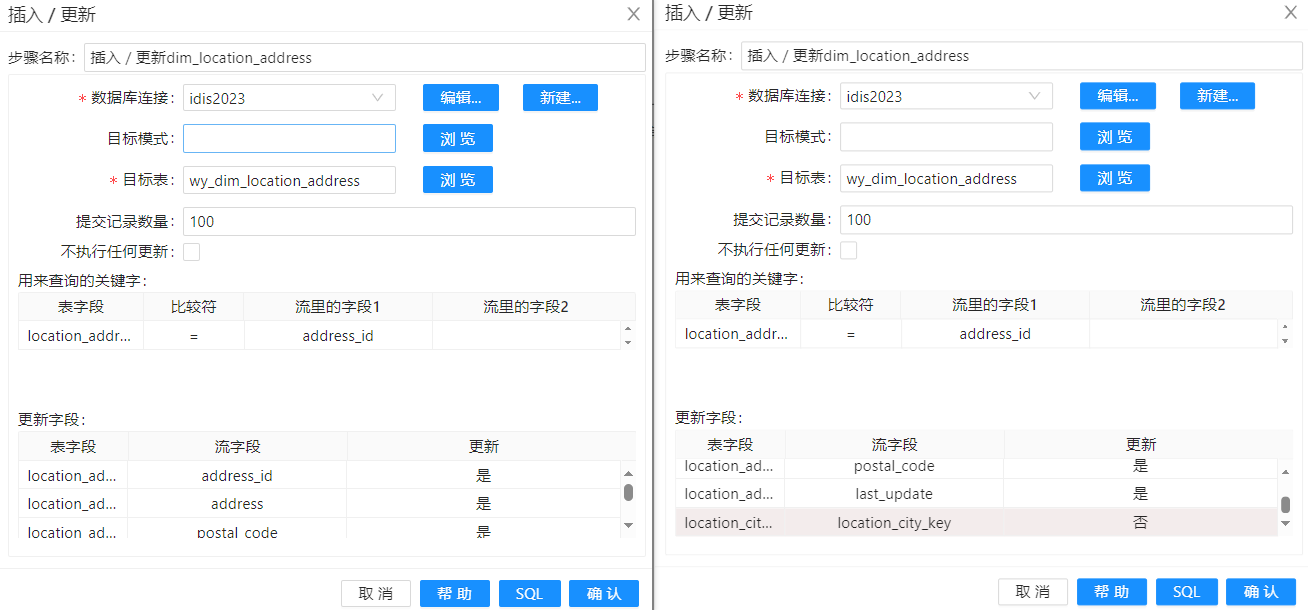
接下来就是用 "插入更新"组件,将增量数据真正的添加到维度表中。
至此基于作业的第二种方式讲解完毕,在作业中点击运行,通过数据库查看工具即可发现原本空空如也的维度表中出现了维度数据。
缓慢变更维度
根据Kimball的理论,有三种类型的缓慢变更维:类型1、类型2、类型3
- 类型1 : 对源系统的更新,也会直接更新目标的维度表
- 类型2 : 对源系统的更新,会往目标维度表里插入一行数据,通过不同的时间戳来维护同一条维度数据的多个版本。在任何一个给定的时间点,都可以找到一行对应的维度数据。
- 类型3 : 对源系统的更新,会在目标维度里增加列,在目标维度表同一行新增的列里保存新的数据。
接下来的内容将讲解 Uniplore 中如何实现类型1与类型2的缓慢变更维度。
缓慢渐变类型1
在类型1的缓慢变更维里,维度表总是保存当前的状态,如果发生变化就直接覆盖,在 Uniplore 中可以"插入/更新"组件实现。例如"维度表的自顶向下加载"中 "加载 dim_location_address" 转换做的一样。
事实上,如果你只是想插入数据,而且并不担心主键或唯一约束的冲突,就不要使用插入/更新步骤。应该直接使用“表输出”步骤。可以给“表输出”步骤定义错误处理,来捕获插入过程中的错误。这个方法不必花费时间去查询,所以要比“插入/更新”步骤快。
缓慢渐变类型2
类型2缓慢变更维的特点是它可以按照时间跟踪到维度的变化。类型1的缓慢变更维不会保留历史数据,新的数据会把旧的数据覆盖,而类型2缓慢变更维每当数据更新,会在维度表里增加一行。通过这种方式,类型2缓慢变更维保存了维度的一组不同版本,这些同一个维度的不同版本有相同的业务键。
“维度查询/更新”步骤位于“数据仓库”类别下,该组件可以用于两种不同的模式。
- 可以用于增加或更新维度表里的数据。这个功能用于类型1和类型2缓慢变更维。这个模式也被称为“更新”模式。
- 可以用于查询步骤,用来抽取类型2缓慢变更维的代理键。这个功能在加载事实表时非常有用,这个模式也被�称为“查询”模式。
因为“维度查询/更新”步骤把这些不同的功能合成到了一起,所以从表面上看它就像是“插入/更新”步骤和“数据库查询”步骤的混合体。但是,这个步骤实际比表面上看上去更复杂。“插入/更新”步骤和“数据库查询”步骤完成的工作就和这两个步骤的名字一样,而“维度查询/更新”步骤可以满足类型2缓慢变更维的保留历史版本的要求。在“更新”模式下,当向维度表里加载数据时,这个步骤可以判断是否要向历史版本中增加新的数据,并自动给维度表里的版本控制列赋值。在“查询”模式下,这个步骤可以自动根据输入流里的日期或时间字段从维度表里获取适当版本的维度记录,而不用再去实现复杂的逻辑。我们也可以使用Kettle的一组其他步骤来实现与“维度查询/更新”步骤同样的功能。但是,这样的转换非常复杂,需要为每一个类型2的缓慢变更维都使用这组步骤,这样转换将变得难以维护。
使用该组件首先要在基本配置中设置数据库连接的相关信息。
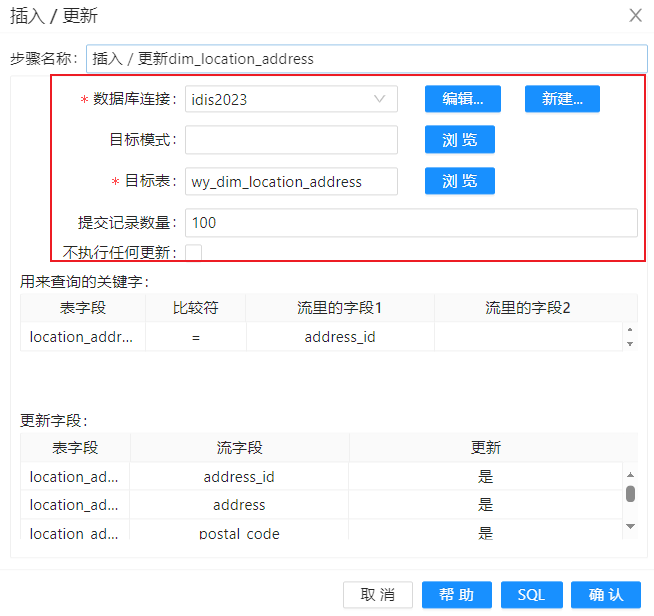
紧接着,在“关键字标签页中设置匹配字段。“维字段”是指维度表里的业务主键。“流里的字段”是指数据流里的字段,用来匹配维度表里的业务主键字段,默认的匹配规则只有等于。
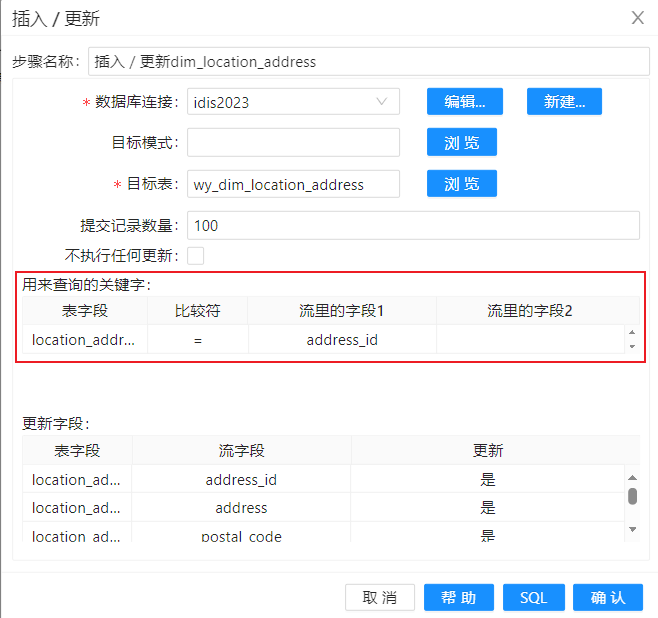
在“其它配置”中还有一些重要设置,让我们来看看吧!
- “创建代理键”栏中的一组字段用来设置如何生成代理键的值。这些仅在插入一行数据时才有用,所以仅用于“��更新”模式。可以选择下面三种方式之一来生成代理键。
- 使用表最记录数+1(最大值+1):正如这个名字,查找出代理键字段的最大值,然后加1,作为新数据行的代理键。
- 使用sequence:指定一个数据库序列的名称。该选项需要数据库支持序列。(见本章前面的“基于数据库序列的代理键”),这里的序列应该位于数据库连接的默认模式下,如果不在默认模式下,需要在上面指定“目标模式”。
- 使用自增字段:如果维度表的代理键使用的是自增列,如auto_increment或IDENTITY列,可以选择这个选项
- “Version字段”用来指定维度表里版本字段的名称,这个字段存储相同业务键的每行记录的版本号。业务主键和版本号字段可以唯一标识出维度表里的一行。在“更新”模式下,如果插入一行新的数据,“维度查询/更新”步骤会自动生成一个版本号。
- “Stream日期字段”用来指定流里的日期字段,这个字段提供了维度变化的时间先后顺序。用来说明在源系统中记录的最后变化时间。
- 对话框里的“开始日期字段”和“截止日期字段”,可以用来指定维度的有效期。
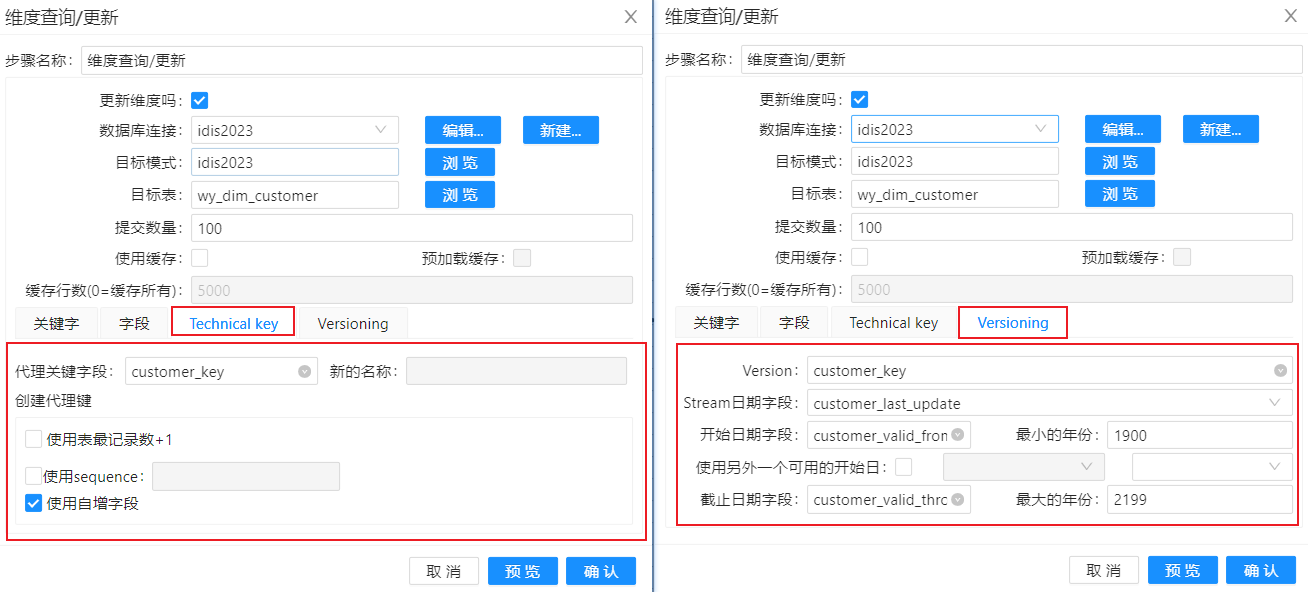
在“字段”标签页下可以指定流里字段和表里字段的映射关系。有一点像“插入/更新”步骤里的“更新字段”部分和“数据库查询”步骤里的“查询表返回的值”部分。
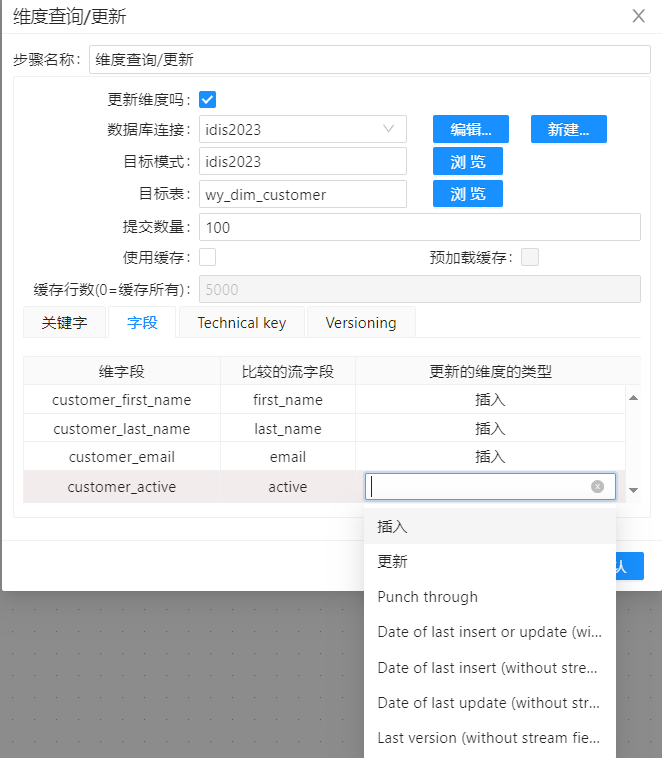
无论是在“查询”还是“更新”模式下,“维字段”里的数据,都会从维度表里取出来。��只有在“更新”模式下,“比较的流字段”里的数据才会从数据流中取出来,并和“维字段”相比较,以判断是否是发生变化的维度。如果比较“维字段”和“比较的流字段”后发现不一样,那么要从“更新的维度的类型”里选择一种操作方式。可以为每个列选择不同的更新方式,例如有些列可以按照类型1的缓慢变更维管理,有些列可以按照类型2的缓慢变更维管理。
上面讨论的类型1和类型2的缓慢变更维是最常使用的,但也存在其他一些缓慢变更维。实际上,很多情况下,一个维度并不是一个纯粹的类型1或类型2的缓慢变更维。要根据属性选择不同的策略,这个要依靠读者对业务的理解与经验来自行判断。
小结
本案例讨论了 Uniplore 如何管理数据仓库的维度表
- Kimball的ETL子系统的理论框架如何应用到实践中,来完成维度表的加载和管理。
- 代理键在数据仓库中的作用。
- 使用 Uniplore 生成代理键的两种方式。
- 使用 Uniplore 自顶向下逐层加载维度表。
- 不同类型的缓慢变更维,主要是类型1和类型2。
- 使用 Uniplore 的“插入/更新”步骤来加载类型1的缓慢变更维。
- 使用 Uniplore 的“维度查询/更新”步骤来加载类型1和类型2的缓慢变更维,以及查询类型2的缓慢变更维。