正则表达式
组件介绍
组件作用
正则表达式组件步骤将输入字段的字符串与您使用正则表达��式(regex)定义的文本模式进行匹配。您可以使用此步骤来解析复杂的文本字符串,并使用捕获组(由括号定义)在输入字段之外创建新字段。 例如,如果您有一个输入字段,其中包含用引号引起的作者姓名和他们发表的帖子数量,则可以在转换中创建两个新字段-一个用于姓名,另一个用于帖子数量,如下所示:
- 输入文本:"Author, Ann" - 53 posts
- 正则表达式:^"([^"])" - (\d) posts$
- 结果:Ann 和 53.
输入输出描述
- **输入:**前一步骤带来的数据信息
- **输出:**经过正则表达式匹配的数据信息
组件图标

页面介绍
双击正则表达式组件可得到如下界面:
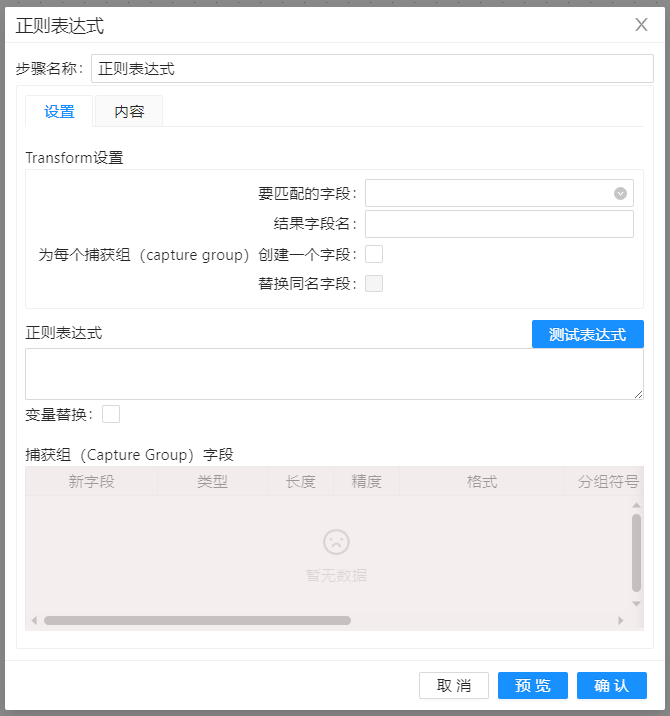
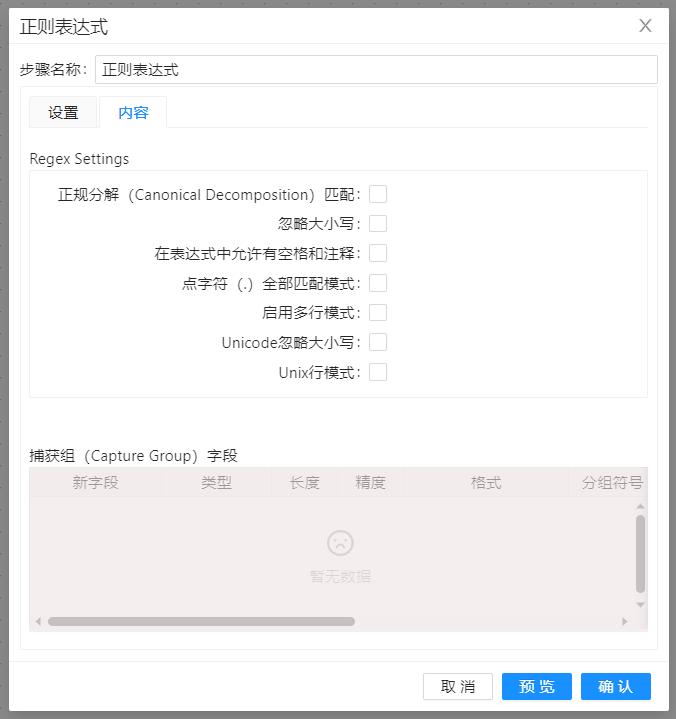
参数选项
正则表达式组件页面包含如下选项:
| 选项 | 说明 | 样例值 |
|---|---|---|
| 步骤名称 | 指定画布上的“正则表达式”步骤的唯一名称。您可以自定义名称或保留其默认值 | 正则表达式 |
| 要匹配的字段 | 指定要与正则表达式匹配的传入 PDI 流中的字段的名称 | |
| 结果字段名称 | 指定输出字段的名称。此字段将添加到传出 PDI 流,并且具有Y 的值,以指示与正则表达式匹配的输入字段的值,或 N表示其不匹配 | |
| 为捕获组创建字段 | 选择此选项可根据捕获组在正则表达式中创建新字段。选择此选项后,将提取捕获组中的子字符串,并存储在"捕获组字段"表中指定的新输出字段中。每个捕获组都必须在捕获组字段表中定义一个字段。表中字段的顺序必须与正则表达式中捕获组的顺序相同。您可以使用表中的列更改数据类型 | |
| 替换以前的字段 | 如果字段具有相同的名称,则选择此选项可将传入 PDI 流中的字段替换为为捕获组字段名称创建的字段。 | |
| 正则表达式 | 指定正则表达式 | |
| 变量替换 | 选择此选项可在计算正则表达式模式之前展开对其值的变量引用 | |
| 正规分解匹配 | 选择此选项可忽略不同的 Unicode 字符编码。此操作可能会提高性能,但您的数据只能包含 US ASCII 字符 | |
| 忽略大小写 | 选择此选项可使用不区分大小写匹配。只有美国 ASCII 字符集中的字符��才匹配。可以通过指定"Unicode 感知大小写..."来启用 Unicode 感知不区分大小写匹配标志与此标志结合使用,执行标志是 (?i) | |
| 在表达式中允许有空白和注释 | 选择此选项可忽略以 # 到行末尾以 # 开始的空格和嵌入注释。在此模式下,必须使用 \s 令牌来匹配空白,执行标志是(?x) | |
| 启用点模式 | 选择以包括具有点字符表达式匹配的行终止符,执行标志是 (?s) | |
| 启用多行模式 | 选择此选项可匹配输入序列的行""或行"的末尾。默认情况下,这些表达式仅匹配整个输入序列的开头和结束,执行标志是 (?m) | |
| Unicode 忽略大小写 | 结合启用不区分大小写匹配选项选择此选项,以执行与 Unicode 标准一致的不区分大小写匹配,执行标志是 (?u). | |
| Unix 行模式 | 选择此选项仅识别'.', '^',和 '$'.\,执行标志是(?d) |
字段表
组件底部表格为字段表,右击选择“获取字段”,组件可根据当前指定设置从源文件获取相应内容填充字段表。该表包含以下列:
| 列名 | 说明 | 样例值 |
|---|---|---|
| 新字段 | 从正则表达式生成的新字段的名称 | |
| 类型 | 字段类型,可以是String、Date或Number等类型。 | |
| 长度 | 字段的长度取决于以下字段类型:Number��:数字中有效数字的总数。String:字符串的总长度。Date:字符串的打印输出长度。 | |
| 精度 | 数字类型字段的浮点位数。 | |
| 格式 | 用于转换原始字段格式的可选掩码。 | |
| 组 | 分组可以是“,”(例如10,000.00)或“.”(例如5.000,00) | |
| 十进制 | 用作小数点的字符 | |
| 货币类型 | 用于表示货币的符号(例如¥或$)。 | |
| 是否为空 | 将此值视为null | |
| 默认 | 未指定传入文件中的字段时默认值(空) | |
| 删除空格 | 应用于字符串 |
案例示例
读入自定义常量数据,对"Str"字段的值进行正则表达式匹配:

案例操作
自定义常量数据
该步骤定义需要用正则表达式匹配的数据。
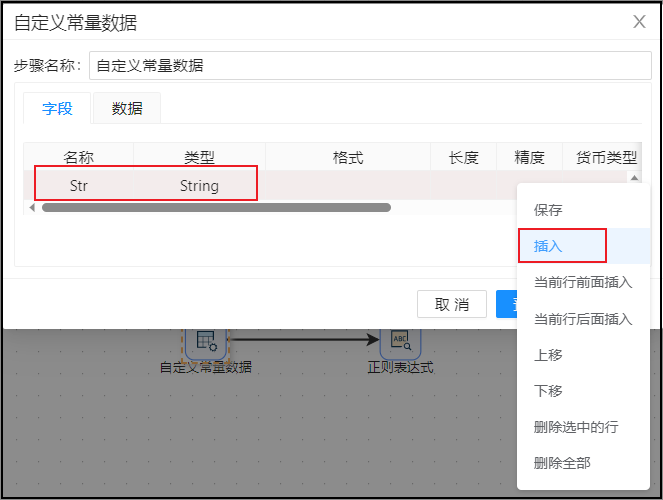
该组件配置主要分为 2 步: 第一步:在字段标签页插入需要生成的字段名称并设置字段类型,这里插入"Str"字段,类型选择为"String"。
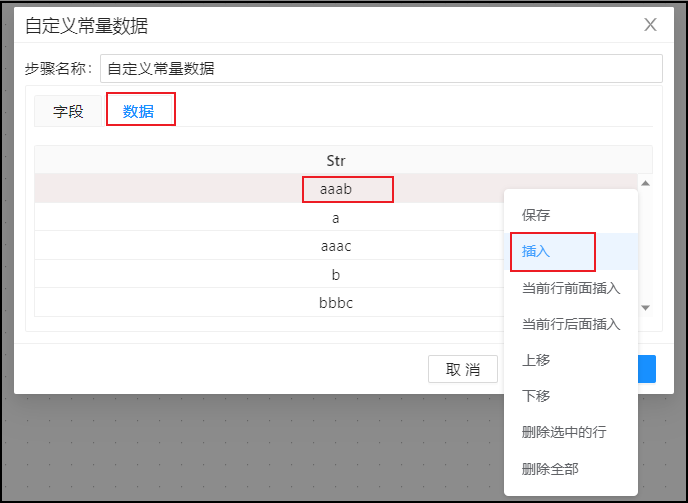
第二步:在数据标签页插入需要生成的数据;
正则表达式
该步骤主要是接收前一个组件传过来的数据并对需要匹配的字段进行正则表达式匹配并输出匹配结果。
该组主要配置主要分为 3 步:
第一步:在输"要匹配的字段"配置需要使用正则表达式匹配的字段,在"结果字段名"配置最后输出的匹配结果的字段名;
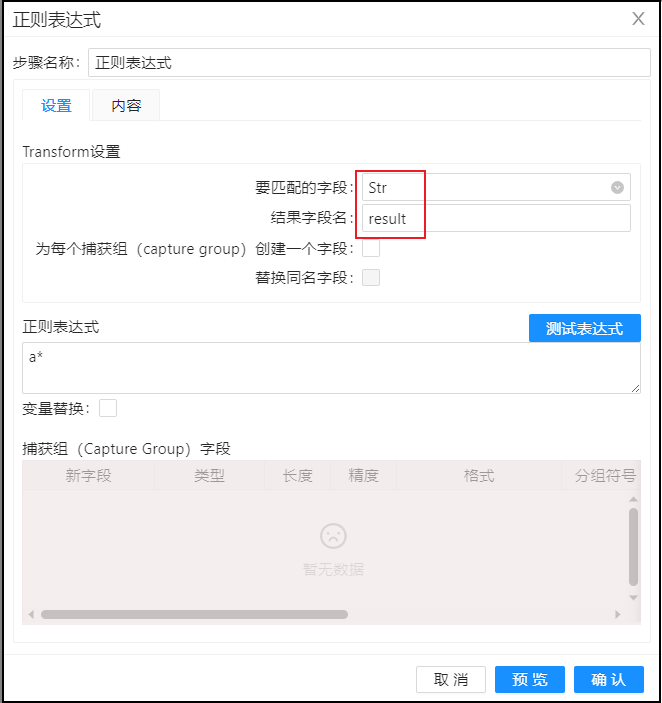
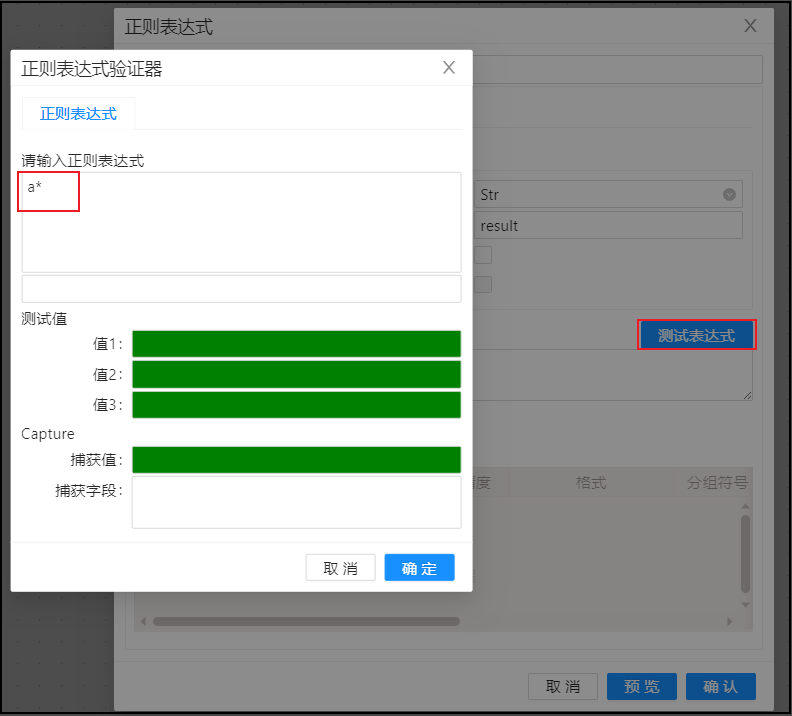
第二步:在正则表达式输入框输入正则表达式的判定规则,或点击"测试表达式按钮"进行正则表达式的验证,点击弹出框的确定按钮输入正则表达式;
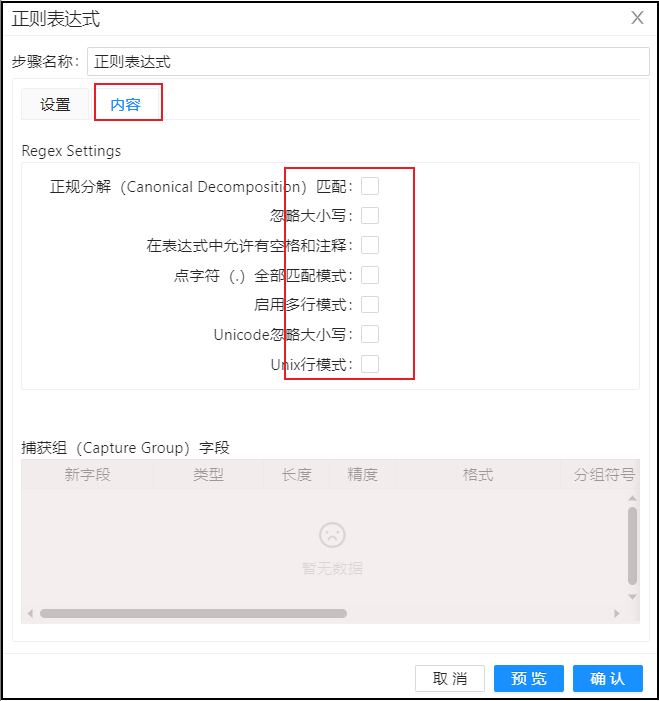
第三步:点击最上方的内容标签配置其他正则表达式其他选项;
结果预览
最终的正�则表达式匹配结果如下图所示:
