文本文件输入
组件介绍
步骤文本文件输入用来读取各种各种的文本文件。最常用的文件格式包括表格文件、csv文件、定宽扁平文件等。
使用正则表达式,组件文本文件输入能读取一批文件或一批目录中的文件,另外,你也能从前面的一个步骤中读取文件名称。
- 输入:需要读取的任何文本文件
- 输出:读取的文本文件的数据
页面介绍
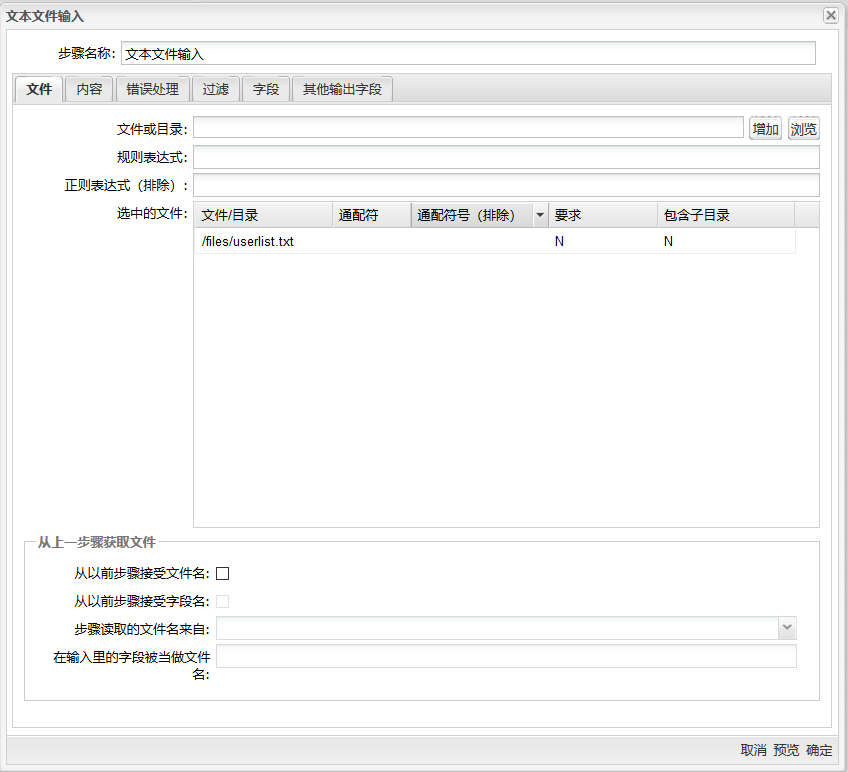
文件标签
文件标签用于配置要读取的文件。
参数选项
文本文件输入组件文件标签页面包含如下选项:
| 选项 | 说明 | 样例值 |
|---|---|---|
| 文件或目录 | 指定输入文本文件的位置或者是路径 | |
| 规则表达式 | 指定你想用来选择文件的正则表达式,文件夹路径为字段“文件或目录”中提供的目录。例如,选择所有的 .txt 文件 | |
| 正则表达式(排除) | 指定你想用来排除文件的正则表达式,文件夹路径为字段“文件或目录”中提供的目录。例如,排除所有的 .log 文件 | |
| 选中的文件 | 这个表格包含了已经选择文件(也可以是正在表达式) | |
| 从以前步骤接受文件名 | 启用该选项,可以从前一个步�骤获取文件名 | |
| 从以前步骤接受字段名 | 启用该选项,可以从前一个步骤获取字段名 | |
| 步骤读取的文件名来自 | 选择文件名来自于哪个步骤 | |
| 在输入里的字段被当做文件名 | 确定哪个字段用来作为步骤“文本文件输入”的输入 |
使用正则表达式选择文件 ** 步骤文本文件输入可以使用正则表达式来模糊匹配文件名。正则表达式比通配符“*”、“?”复杂。下面是一些正则表达式的例子:
| 文件名 | 正则表达式 | 选择的文件 |
|---|---|---|
| /dirA/ | .userdata.\.txt | 查找目录 /dirA/ 中所有文件名包含 userdata 且以 .txt 结尾的文件。 |
| /dirB/ | AAA.* | 查找目录 /dirb/ 中所有以 AAA 开头的文件 |
| /dirC/ | [ENG:A-Z][ENG:0-9].* | 查找目录 /dirC/ 中文件名字以大写字母开头,并且紧跟一个数字的文件。 |
字段表
| 列名 | 说明 | 样例值 |
|---|---|---|
| 文件/目录 | 文件或者目录的名称 | |
| 通配符号 | 与参数中的正则表达式部分相同 | |
| 通配符号(排除) | 与参数中的正则表达式(排除)部分相同 | |
| 要求 | 是否必须 | |
| 包含子目录 | 是否匹配子目录 |
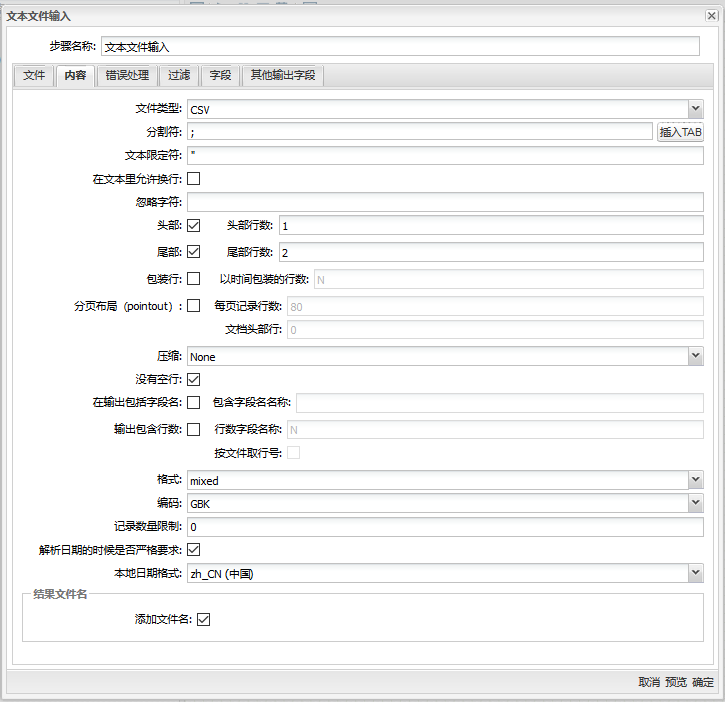
内容标签
内容标签可以指定读取文件的类型。
参数选项
文本文件输入组件内容标签页面包含如下选项:
| 选项 | 说明 | 样例值 |
|---|---|---|
| 文件类型 | 文件类型可以是 CSV 或者是定长文件 | |
| 分割符 | 在一行文本中,用来分开字符串的一个或多个字符。通常的分隔符是“;”或者 tab | |
| 文本限定符 | 有些字段可以用一对字符串括起来,以允许字段中使用分隔符,称为“文本限定符”。文本限定符是可选的 | |
| 在文本里允许换行 | 允许文本中的换行符 | |
| 忽略字符 | 指定在你的数据中要忽略的字符或者字符串。如果存在要忽略的字符“\”,文本'Not the nine o\'clock news'(包含引号)将被解析为 not the nine o'clock news | |
| 头部 & 头部行数 | 如果你的头文件有头信息的话(文件开始的行),你可以启动该选项。你也能指定头行出现��的次数 | |
| 尾部 & 尾部行数 | 如果你的文件有尾信息的话(文件尾部的行),你可以启动该选项。你也能指定尾行出现的次数 | |
| 包装行 | 当处理的数据行包装超出了特定的页面限制,需启用该选项。请注意,页眉和页脚永远不会被认为是包装的 | |
| 分页布局 | 当要在行式打印机上处理事,需要启用该选项 | |
| 压缩 | 如果你的数据是在一个压缩包如 Zip 或 GZip中,需要启动该选项。注意:压缩包中的文件只有第一个会被读取 | |
| 没有空行 | 不发送空行到下一个步骤 | |
| 在输出包括字段名 | 如果你想将文件名作为一部分,需要启用该选项 | |
| 输出包含行数 | 如果你想要行序号,需要启动该选项 | |
| 格式 | 可以是 DOS, UNIX , 或者 mixed。UNIX 文件的行结尾符号是换行符,DOS 文件的换行符是回车和换行。如果你使用 mixed,将不进行验证 | |
| 编码 | 指定文本文件的编码。为空时表示使用系统的默认编码。可以使用 Unicode、UTF-8 或 UTF-16 | |
| 记录数量限制 | 指定从文件中读取的最大行数。0 表示不限制 | |
| 解析日期的时候是否严格要求 | 如果想要严格解析时间格式,你需要禁用该选项 | |
| 本地日期格式 | 设置本地日期的格式 | |
| 添加文件名 | 添加文件名到内部的文件名结果集。内部的结果集能在后面的步骤中使用,例如处理所有读取的文件 |
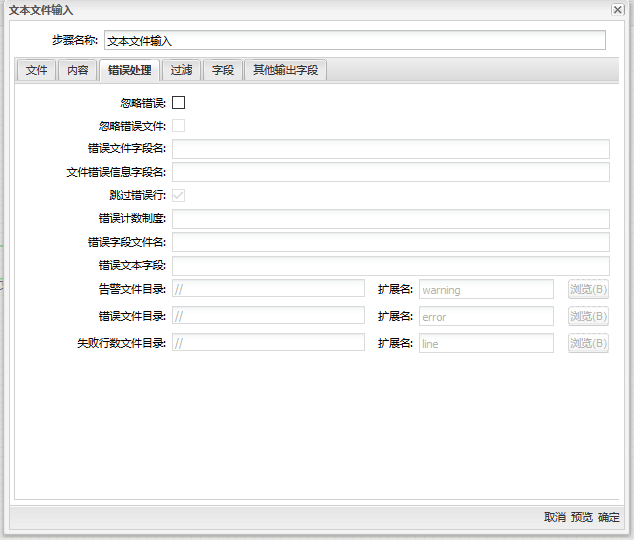
错误处理标签
当错误发生时,错误处理标签允许你设置本步骤如何处理错误。
参数选项
“文本文件输入”组件错误处理标签页面包含如下选项:
| 选项 | 说明 | 样例值 |
|---|---|---|
| 忽略错误 | 当解析的时候,如果你想忽略错误,可以启用该选项 | |
| 忽略错误文件 | 解析出错时,将忽略该文件 | |
| 错误文件字段名 | 增加一个字段到输出流中,该字段表示错误文件的字段名 | |
| 文件错误信息字段名 | 增加一个字段到输出流中,该字段表示文件错误信息字段名 | |
| 跳过错误行 | 当某行出现错误时,启动该选项跳过出错行。当然,可以将出错的行另存为一个文件。带有错误的行不会被跳过,有错误的字段将被解析为 null | |
| 错误计数制度 | 以何种方式进行错误计数 | |
| 错误字段文件名 | 增加一个字段到输出流中,这个字段包含错误文件的文件名 | |
| 错误文本字段 | 增加一个字段到输出流中,这个字段包含错误文本字段的描述 | |
| 告警文件目录 & 扩展名 | 当警告产生时,他们将会被放到该目录中。文件名称是: 错误行目录/文件名.当前时间.扩展名 | |
| 错误文件目录 & 扩展名 | 当文件不存在或不可访问时,将会被放到该目录中。文件名称是: 错误行目录/文件名.当前时间.扩展名 | |
| 失败行数文件目录 & 扩展名 | 当在某一行发生错误是,行号将会被放置到该目录中。文件名称是: 错误行目录/文件名.当前时间.扩展名 |
过滤标签
过滤标签可以设置你想要跳过的行。
字段表
该表包含以下列:
| 列名 | 说明 | 样例值 |
|---|---|---|
| 过滤器字符串 | 想要搜索的字符串 | |
| 过滤器位置 | 字符串的位置必须在指定的行中。0 表示第一行。如果指定小于 0 的值,过滤器将在整个字符串中搜索 | |
| 停止在过滤器 | 当遇到过滤字符串时,如果你不想处理档期的文本文件,填 ”Y“ 可以停止过滤 | |
| 积极匹配 | 当匹配到过滤的行的时候,如果你想处理该行,那么需要填 ”Y“,填”N“表示不处理该行 |
字段标签�
该标签可以设置读取字段的名字或者格式。
字段表
该表包含以下列:
| 列名 | 说明 | 样例值 |
|---|---|---|
| 名称 | 字段名 | |
| 类型 | 字段类型(String、Date、Number 等) | |
| 格式 | 数字的格式。请参考 java 的 Number Formatting | |
| 位置 | 当处理定长文件是,该参数是必须的。每行的位置是从 0 开始的 | |
| 长度 | 对于 Number:有效数的数量;对于 String:字符的长度;对于 Date:打印输出字符的长度(例如 4 代表返回年份) | |
| 精度 | 对于 Number:浮点数的数量;对于 String,Date,Boolean:未使用 | |
| 货币 | 用来解释如$10,000.00 的数字 | |
| 小数 | 小数点可以是”.”(10;000.00)或者”,”(5.000,00) | |
| 分组 | 分组可以是”.”(10;000.00)或者”,”(5.000,00) | |
| Null if | 将该值视为 NULL | |
| 默认 | 字段为空的时候的默认值 | |
| 去除空字符串的方式 | 处理之前先去空(左、右、两边)。如字符 a (两边都有空格),如果裁剪方式为“左”,那么左边的空格将会被去掉 | |
| 重复 | 如果在当前行中对应的值为空,则重复最后一次不为空的值 |
其他输出字段
参数选项
“文本文件输入”组件其他输出字段标签页面包含如下选项:
| 选项 | 说明 | 样例值 |
|---|---|---|
| 文件名字段 | 包含文件名的字段名,不带路径信息,但带有扩展名 | |
| 扩展名字段 | 包含文件名字段名称 | |
| 路径字段 | 包含操作系统格式的路径的字段名称 | |
| 文件大小字段 | 包含文件大小的字段名称 | |
| 是否为隐藏文件字段 | 包含文件是否隐藏的字段名称(布尔值) | |
| 最后修改时间字段 | 最后修改时间的字段名称 | |
| Uri字段 | 仅包含URI根部分的字段名称 | |
| Root uri 字段 | 指定仅包含URI根部分的字段。 |
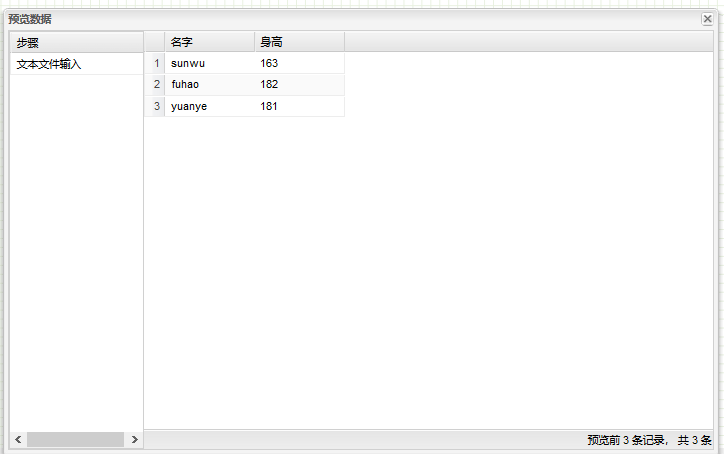
使用案例
使用组件“文本文件输入”读取 userlist.txt 文件,文件类容如下
名字;身高
sunwu;163
fuhao;182
yuanye;181
# 名字以拼音代表
# 身高的单位为 cm
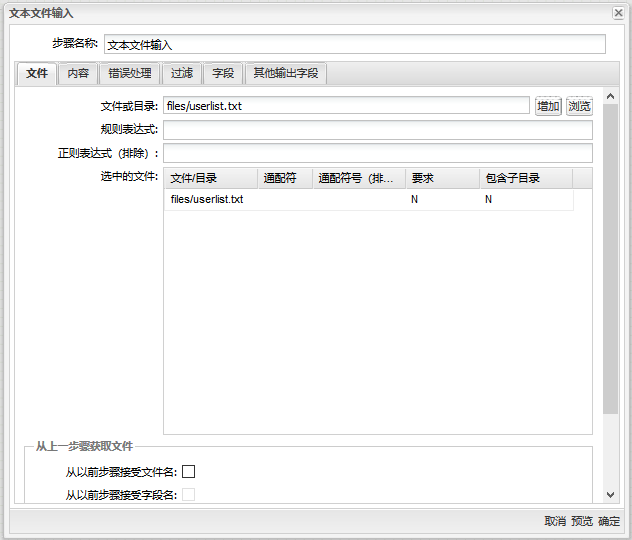
1、点击按钮”浏览“,选择文件”userlist.txt“。再点击按钮”添加“,将文件添加到“选择的文件”列表中。
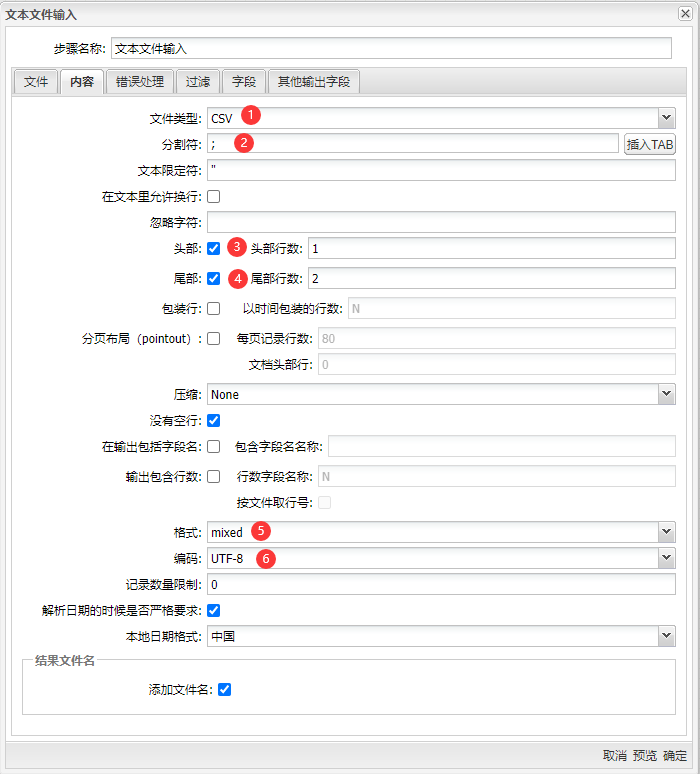
2、做以下配置: 1)设置文件格式为 CSV; 2)设置分割符为“;”; 3)设置去除头部一行; 4)设置去除尾部两行; 5)格式��设置为 “mixed“; 6)设置编码为 GBK。
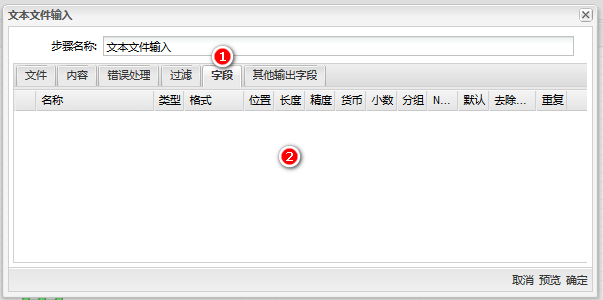
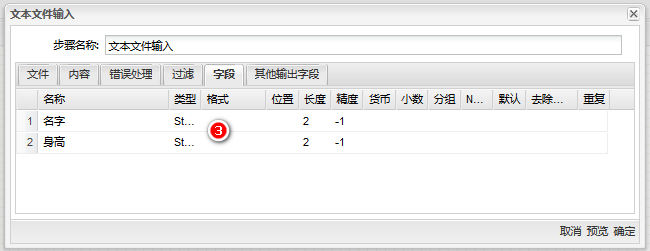
3、做以下配置:1)切换到”字符“ 标签页;2)右击内容区;3)单击“获取字段”,即可获取文件中的表头。
4、右击工作区,单击浏览,即可获得结果,如下图。