正则表达式检测
组件介绍
组件图标

组件作用
“正则表达式检测”组件用于给定字段进行正则匹配。并分别输出匹配的解雇和不匹配的结果。
- 输入:前一步骤输出的字段
- 输出:分别输出匹配的结果和不匹配的结果
- 参数:无
页面介绍:
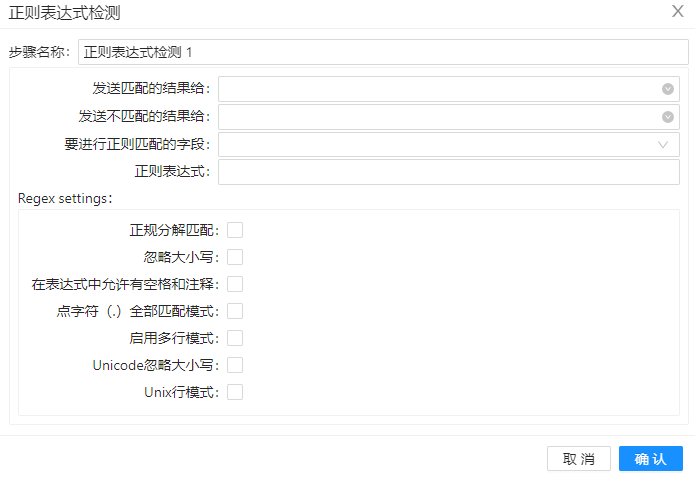
参数选项
| 选项 | 说明 | 样例值 |
|---|---|---|
| 发送匹配的结果给 | 定义匹配的结果输出流向 | |
| 发送不匹配的结果给 | 定义不匹配的结果输出流向 | |
| 要进行正则匹配的字段 | 来源于前一个步骤的输出字段 | |
| 正则表达式 | 设置正则规则 | |
| 正规分解匹配 | 选择此选项可忽略不同的 Unicode 字符编码。此操作可能会提高性能,但您的数据只能包含 US ASCII 字符 | |
| 忽略大小写 | 选择此选项可使用不区分大小写匹配。只有美国 ASCII 字符集中的字符才匹配。可以通过指定"Unicode 感知大小写..."来启用 Unicode 感知不区分大小写匹配标志与此标志结合使用,执行标志是 (?i) | |
| 在表达式中允许有空白和注释 | 选择此选项可忽略以 # 到行末尾以 # 开始的空格和嵌入注释。在此模式�下,必须使用 \s 令牌来匹配空白,执行标志是(?x) | |
| 点字符(.)全部匹配模式 | 选择以包括具有点字符表达式匹配的行终止符,执行标志是 (?s) | |
| 启用多行模式 | 选择此选项可匹配输入序列的行""或行"的末尾。默认情况下,这些表达式仅匹配整个输入序列的开头和结束,执行标志是 (?m) | |
| Unicode 忽略大小写 | 结合启用不区分大小写匹配选项选择此选项,以执行与 Unicode 标准一致的不区分大小写匹配,执行标志是 (?u). | |
| Unix 行模式 | 选择此选项仅识别'.', '^',和 '$'.\,执行标志是(?d) |
使用案例
该案例演示正则表达式检测的使用方法,将匹配“name”字段至少包含数字和字符的数据行
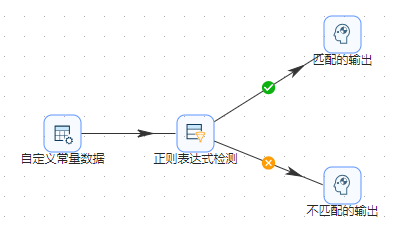
总体流程如下图所示:
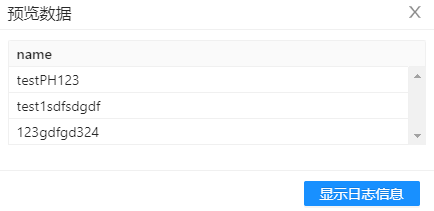
输出结果预览:
匹配的结果输出如下图所示:
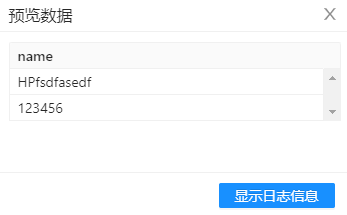
不匹配的结果输出如下图所示:
案例数据
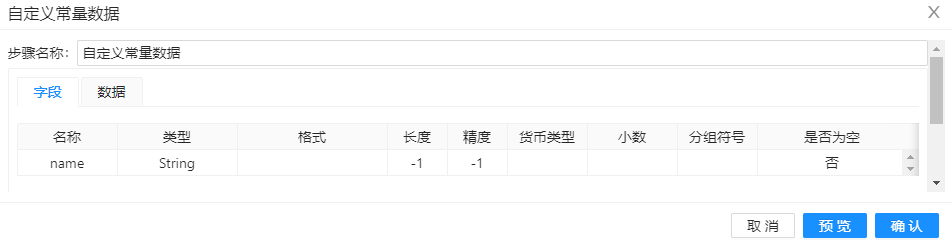
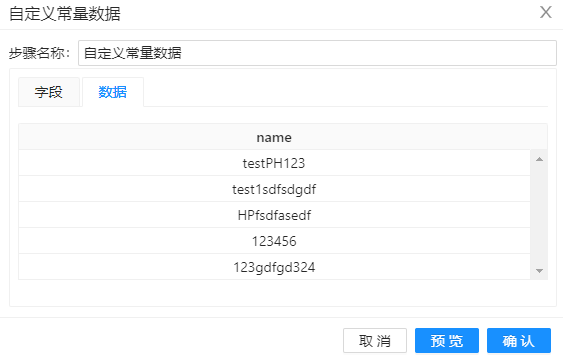
本案例用“自定义常量数据”组件生成了5行数据,包含“name”字段。 具体配置如下图所示:
正则表达式为:
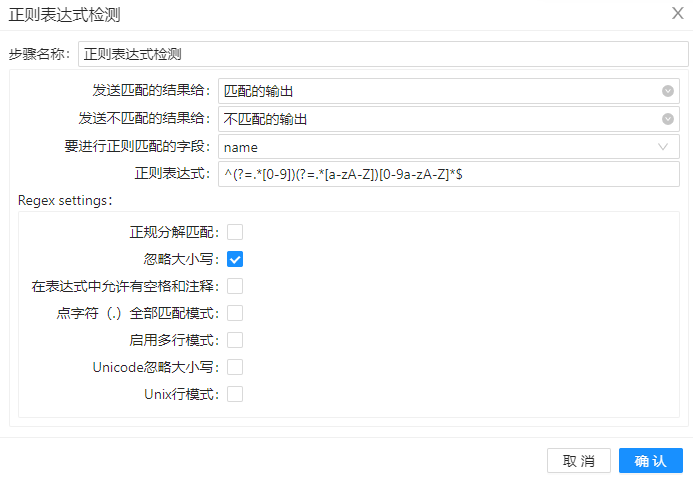
^(?=.*[0-9])(?=.*[a-zA-Z])[0-9a-zA-Z]*$
案例操作
1、拖动"自定义常量组件"到工作区,双��击编辑组件参数,首先编辑元数据
2、再点击“数据”标签页添加数据,编辑完成后点击右下角确定保持组件设置。
3、拖动"正则表达式检测"组件到工作区,再拖动两个“空操作(什么也不做)”组件到工作区,分别改为“匹配的输出”和“不匹配的输出”。然后将几个组件连接起来,具体连接如下图所示:
4、双击"正则表达式检测"组件,选择要进行匹配的字段,并输入对应正则表达式,勾选“忽略大小写”。具体设置如下图所示:
5、分别在“匹配的输出”和“不匹配的输出”两个组件下,右键点击预览,可以看到结果如下图所示。 匹配的输出:
不匹配的输出:
常见问题
无