支持向量机
组件介绍
**“支持向量机”(SVM)**控件支持构建支持向量机模型。可用于分类任务或回归任务。
支持向量机(Support Vector Machine,简称 SVM)是一种机器学习基础算法,它使用超平面分割属性空间,从而最大化不同类别或类别值的实例之间的边界。该技术经常产生超高的预测性能结果。对于回归任务,SVM 使用 ε 不敏感损失在高维特征空间中执行线性回归。其估计精度取决于 C,ε 和内核参数的设置。
- 输入:
- data:数据集
- pre: 预处理方法
- 输出:
- lrn: 在交互页面中配置参数后的支持向量机学习算法
- mod: 已训练的模型(仅当输入端data存在时,才会有输出信息)
- sv:来自训练集的数据实例的子集,被用作训练模型中的支持向量
页面介绍
点击**“支持向量机”(SVM)**控件查看参数配置页面,如下图所示:
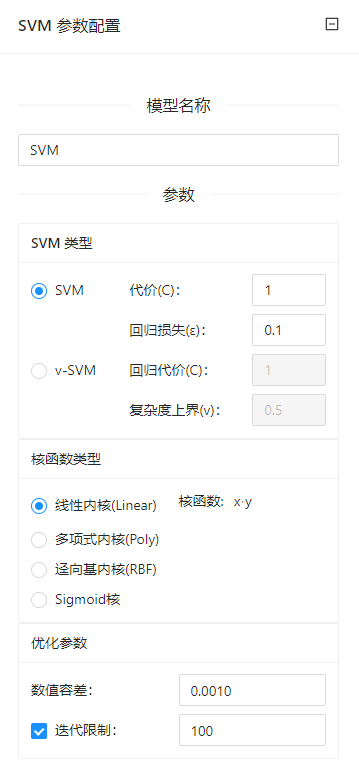
参数选项
| 选项 | 说明 | 取值范围 | 样例值 | |
|---|---|---|---|---|
| 模型名称 | 设置模型名称,用于在其他组件中区分不同的模型 | 非空字符串 | SVM | |
| SVM类型 | SVM | 代价(C):损失函数的惩罚因子,适用于分类和回归任务 | 代价(C):0.01 | 代价(C):1 |
| v-SVM | 回归代价(C):损失函数的惩罚因子,仅适用于回归任务 | 回归代价(C):0.01 | 回归代价(C):1 | |
| 核函数类型 | 线性内核(Linear) | 指定内核的函数会涉及以下常量: | g:0 | g:0 |
| 多项式内核(Poly) | ||||
| 径向基内核(RBF) | ||||
| sigmoid核 | ||||
| 优化参数 | 数值容差 | 设置允许的偏差 | 0.0001~1 | 0.001 |
| 迭代限制 | 设置允许的最大迭代次数 | 5~100000 | 100 |
使用案例
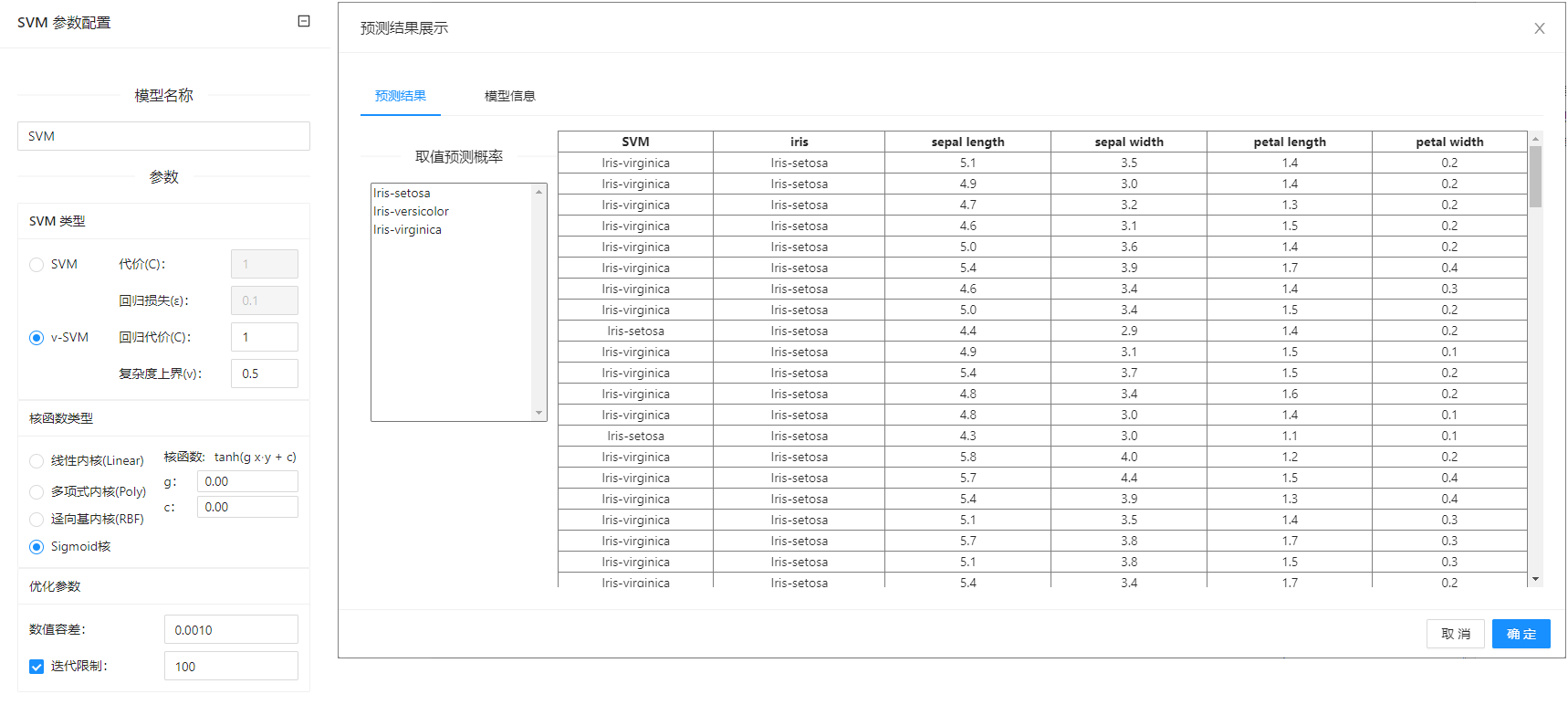
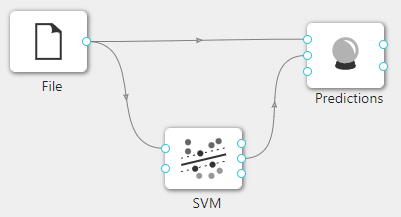
在下图所示的案例中,使用**“加载文件”(File)控件加载数据集,连接“支持向量机”(SVM)控件构建模型,之后把“加载文件”(File)控件以及“支持向量机”(SVM)控件与“预测”(Predictions)**控件连接起来查看基于已经构建的 SVM 模型对输入数据进行预测的结果。
案例中加载 iris 数据集,对于**“支持向量机”(SVM)**控件的配置,设置名称为 SVM,选择 v-SVM 类型,内核函数选择 Sigmoid 核,其他使用默认参数。案例中控件的配置及运行结果如下图所示。