随机森林
组件介绍
**“随机森林”(Random Forest)**控件使用决策树集合进行预测。可用于分类任务或回归任务。
随机森林是一种用于分类、回归和其他任务的集合学习方法。由 Tin Kam Ho 首先提出,并由 Leo Breiman (Breiman,2001) 和 Adele Culter 进一步发展。随机森林构建了一组决策树,每棵树都是从训练数据的 bootstrap 样本开发而来的。在开发独立的树时,绘制任意属性子集,从中选择分割的最佳属性。最终的模型是基于森林中独立的树的大多数投票。随机森林适合用于分类和回归任务。
- 输入:
- data:数据集
- pre: 预处理方法
- 输出:
- lrn: 在交互页面中配置参数后的随机森林学习算法
- mod: 已训练的模型(仅当输入端data存在时,才会有输出信息)
页面介绍
点击**“随机森林”(Random Forest)**控件查看参数配置页面,如下图所示:
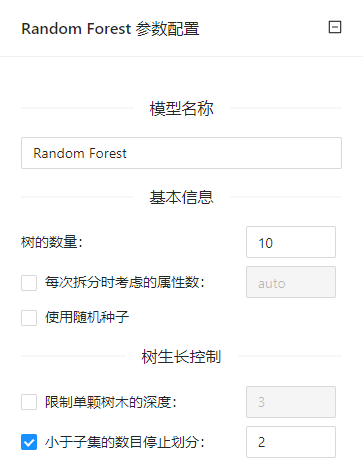
参数选项
| 选项 | 说明 | 取值范围 | 样例值 |
|---|---|---|---|
| 模型名称 | 设置模型名称,用于在其他组件中区分不同的模型 | 取值范围 | Random Forest |
| 树的数量 | 随机森林模型中树的个数 | 1~1000 | 10 |
| 每次拆��分时考虑的属性数 | 若未指定“随机发生器的固定种子”,则此数字等于数据中属性数量的平方根 | 2~50 | 3 |
| 使用随机种子 | 控制建树时的随机性 | 勾选/不勾选 | 勾选 |
| 限制单颗树木的深度 | 单颗树的最大深度 | 1~50 | 5 |
| 小于子集的树目停止划分 | 最大叶子结点数 | 2~1000 | 10 |
使用案例
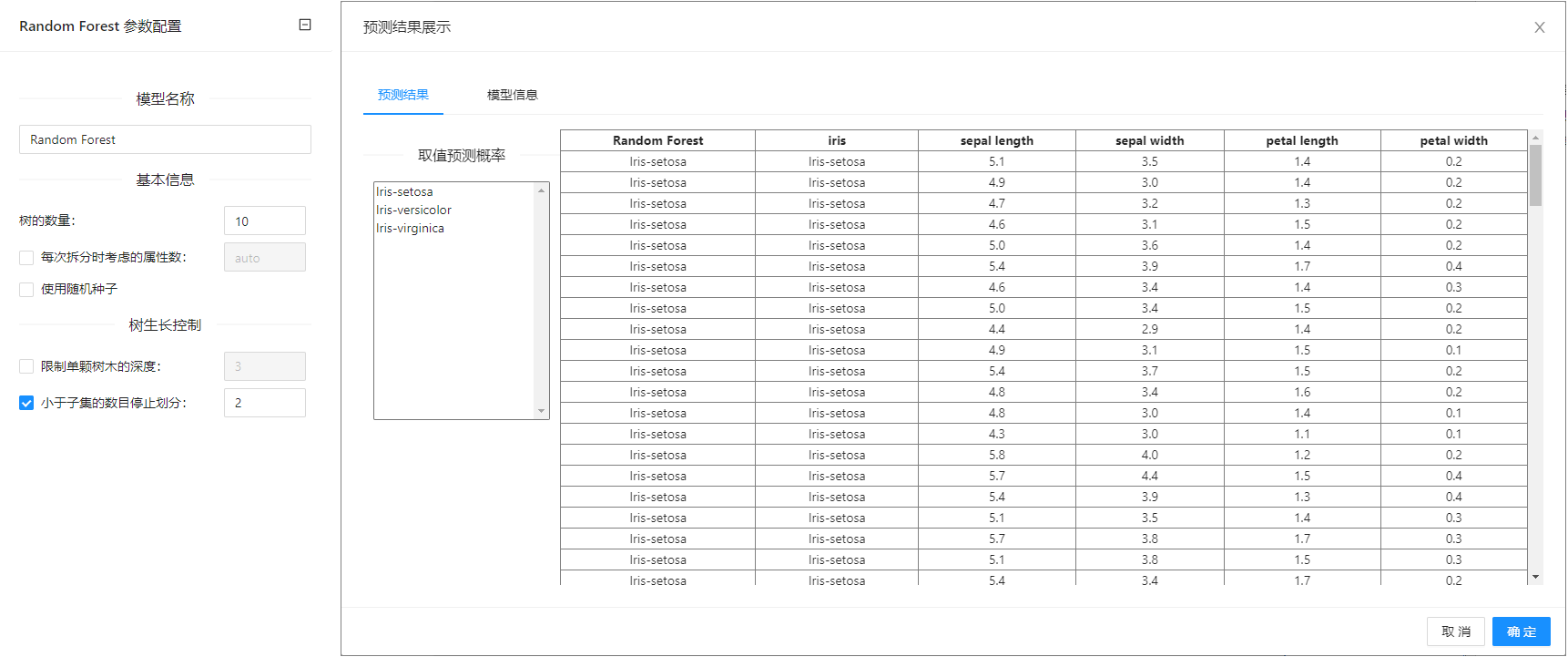
在下图所示的案例中,使用**“加载文件”(File)控件加载数据集,连接“随机森林”(Random Forest)控件构建模型,之后把“加载文件”(File)控件以及“随机森林”(Random Forest)控件与“预测”(Predictions)**控件连接起来查看预测的结果。
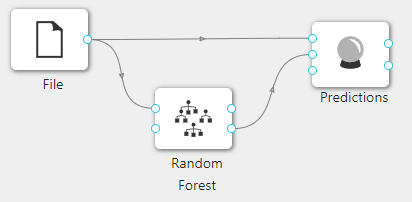
案例中加载 iris 数据集,**“随机森林”(Random Forest)**控件参数使用默认值。案例中控件的配置以及执行结果如下图所示。