自动化机器学习
组件介绍
**“自动化机器学习”(AutoML Training)**控件根据数据集以及用户的配置进行自动化机器学习,自动构建合适的算法模型。可用于分类任务或回归任务。
**“自动化机器学�习”(AutoML Training)**控件支持速建模,无需选择特定的算法模型及参数配置,组件会根据输入数据自动进行算法选择及参数调优。在自动化机器学习过程中,包含特征选择、特征预处理、特征构建,同时还支持模型选择和参数调优。自动化机器学习利用遗传算法进行自动化的特征选择和模型选择,能够智能地探索数千个可能的pipeline和超参数组合,为数据集找到最好的pipeline,完成搜索之后,提供合适的算法模型。
- 输入:
- data:数据集
- 输出:
- mod: 已训练的模型(仅当输入端data存在时,才会有输出信息)
页面介绍
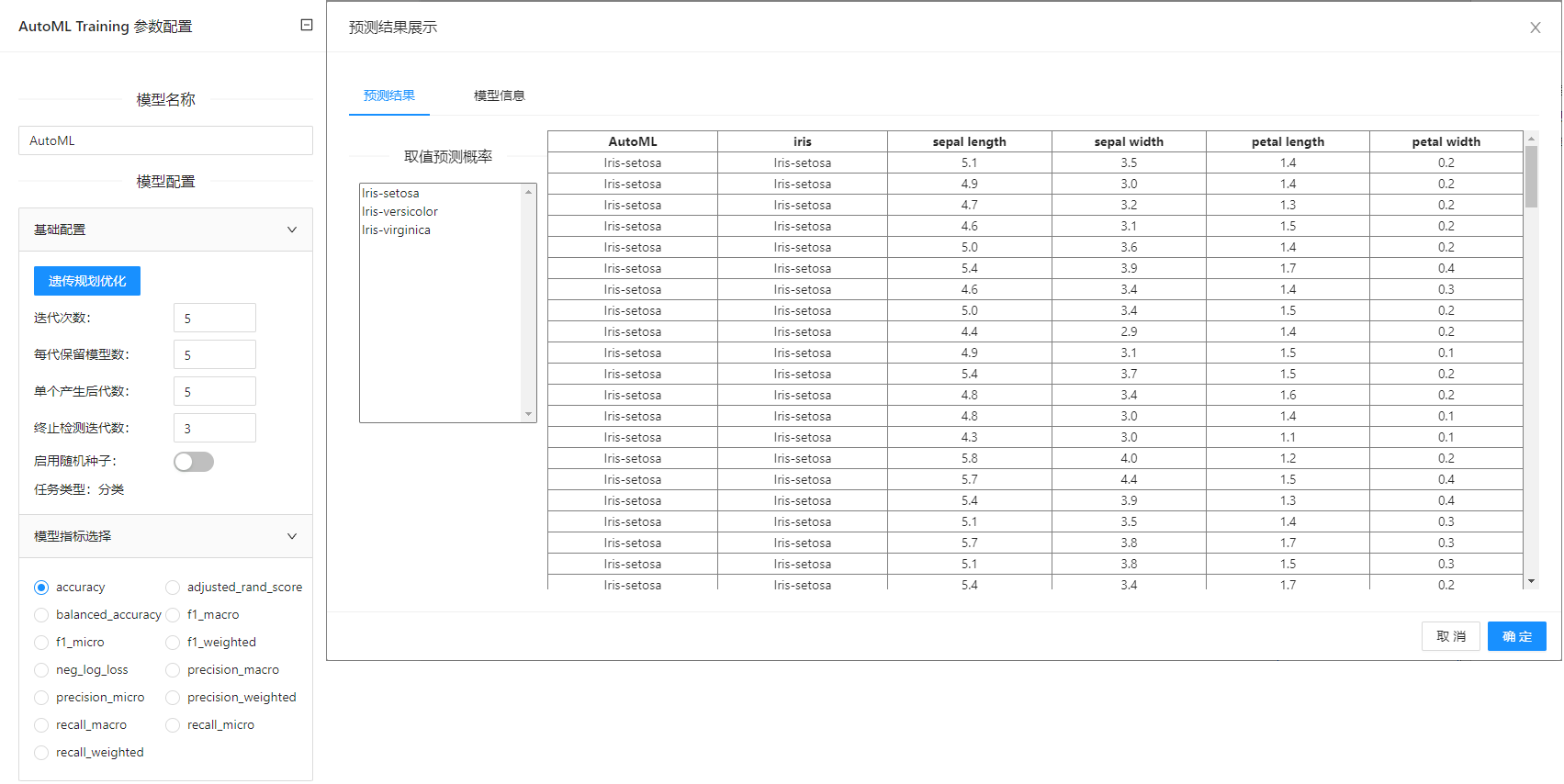
点击**“自动化机器学习”(AutoML Training)**控件查看参数配置页面,如下图所示:
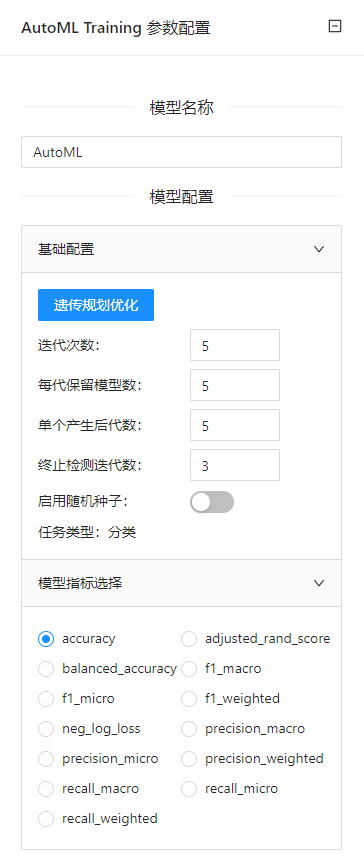
参数选项
| 选项 | 说明 | 取值范围 | 样例值 |
|---|---|---|---|
| 模型名称 | 设置模型名称,用于在其他组件中区分不同的模型 | 字符串 | AutoML |
| 基本配置 | 迭代次数:自动化机器学习优化过程的迭代次数 | 迭代次数:1 | 迭代次数:5 |
| 模型指标选择 | 用于比较生成的机器模型的效果 | 分类任务: | accuracy |
使用案例
在下图所示的案例中,使用**“加载文件”(File)控件加载数据集,连接“自动化机器学习”(AutoML Training)控件构建模型,之后把“加载文件”(File)控件以及“自动化机器学习”(AutoML Training)控件与“预测”(Predictions)**控件连接起来查看预测的结果。
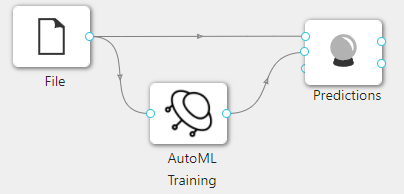
案例中加载 iris 数据集,使用**“自动化机器学习”(AutoML Training)**控件默认参数运行。案例中控件的配置以及运行结果如下图所示。