重复执行
组件介绍
此作业步骤会重复执行你选择的管道或工作流程,直到满足某个条件。
- 输入:无
- 输出:无
- 参数:无
组件图标

页面介绍
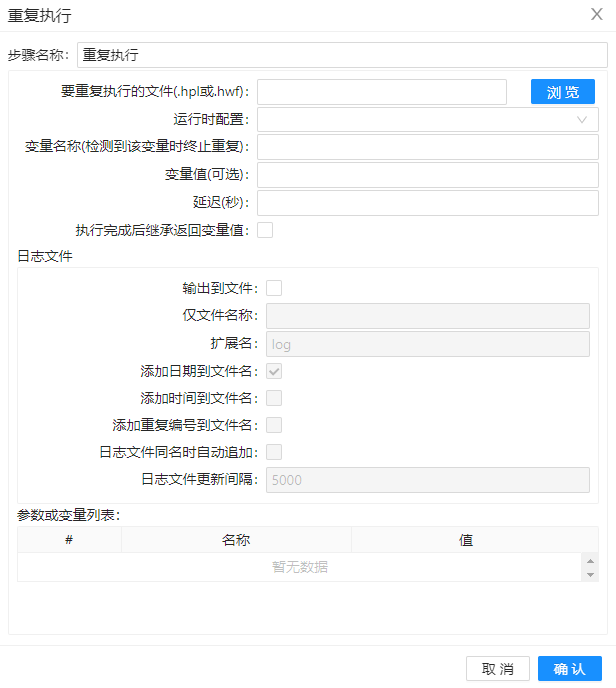
参数选项
| 选项 | 说明 | 样例值 |
|---|---|---|
| 要重复执行的文件(.hpl或.hwf) | 要重复执行的 pipeline 或 workflow 的文件名。 | |
| 运行时配置 | 要使用的pipeline或workflow运行配置。请注意,如果你在远程服务器上设置一个变量,该值目前不会被反馈,所以目前只支持本地工作流引擎。 | |
| 变量名称(检测到该变量时终止重复) | 指定你想在停止重复循环前检查的变量 | |
| 变量值(可选) | 该选项在一个(重复的)管道或工作流执行后保留变量值,以注入到下一个迭代。 | |
| 延迟(秒) | ||
| 执行完成后继承返回变量值 | ||
| 输出到文件 | 在这个组中,你可以指定是否要将日志记录到一个文件中,以及应该如何做。 | |
| 仅文件名称 | ||
| 扩展名 | ||
| 添加日期到文件名 | ||
| 添加时间到文件名 | ||
| 添加重复编号到文件名 | ||
| 日志文件同名时自动化追加 | ||
| 日志文件更新间隔 | ||
| 参数或变量列表 |
表格字段说明:
| 选项 | 说明 | 样例值 |
|---|---|---|
| 名称 | 字段名 | |
| 值 | 字段值 |
案例示例
该案例用于介绍一个pipeline的重复执行。
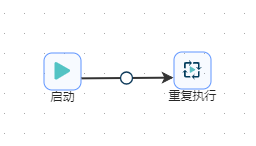
总体执行流程如下图所示:
数据准备
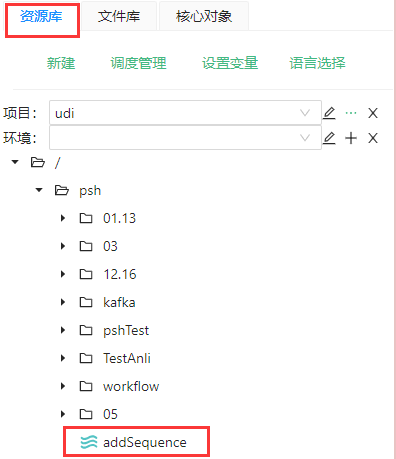
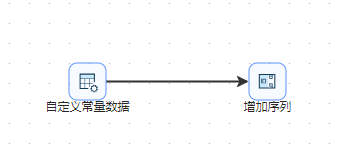
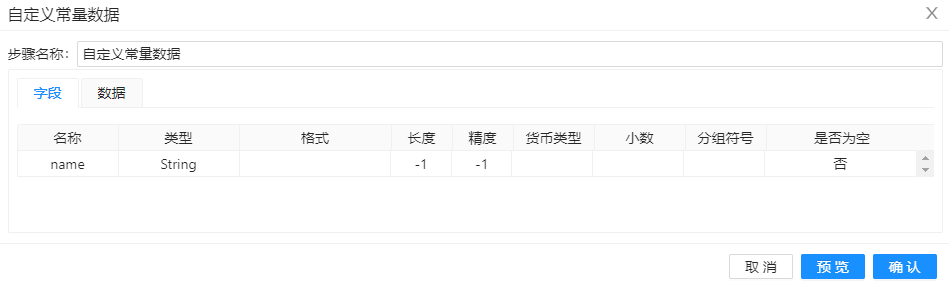
这里提供了一个pipeline的文件,这个pipeline是从【资源库】中选择的一个文件。这个pipeline具体包含两个组件,分别是“自定义常量数据”和“增加序列”��组件。
在这个案例里面的子pipeline设置如下。
“自定义常量数据”设置如下图所示。
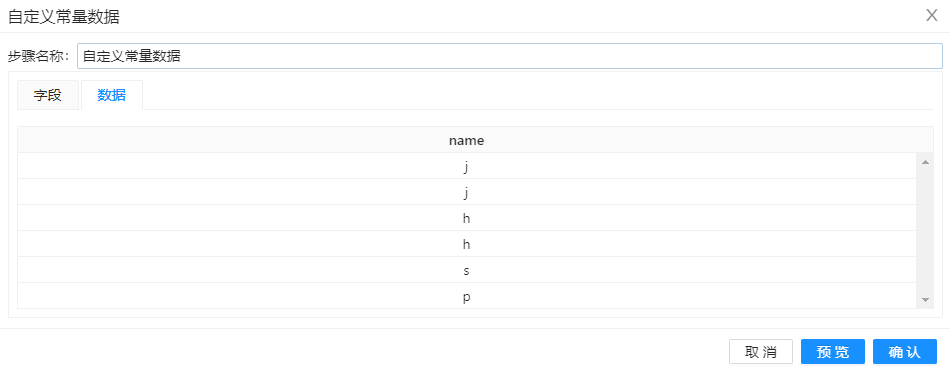
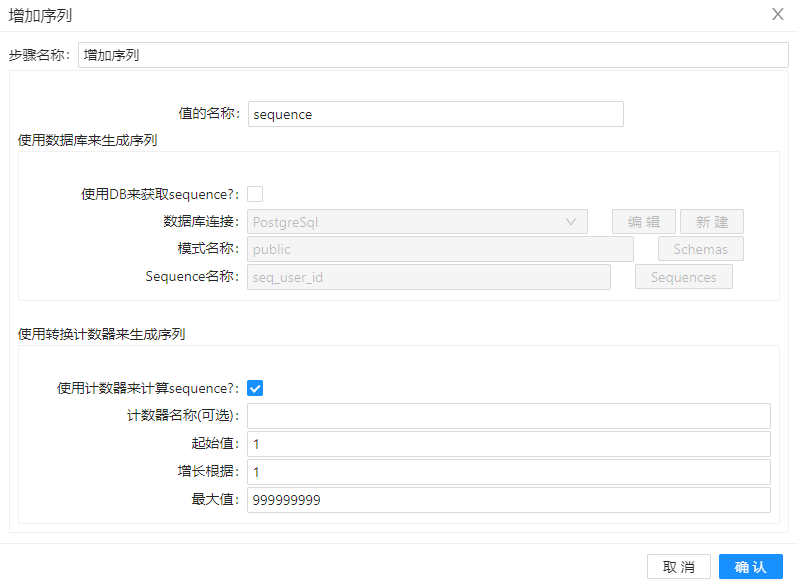
“增加序列”组件设置如下图所示。
案例操作
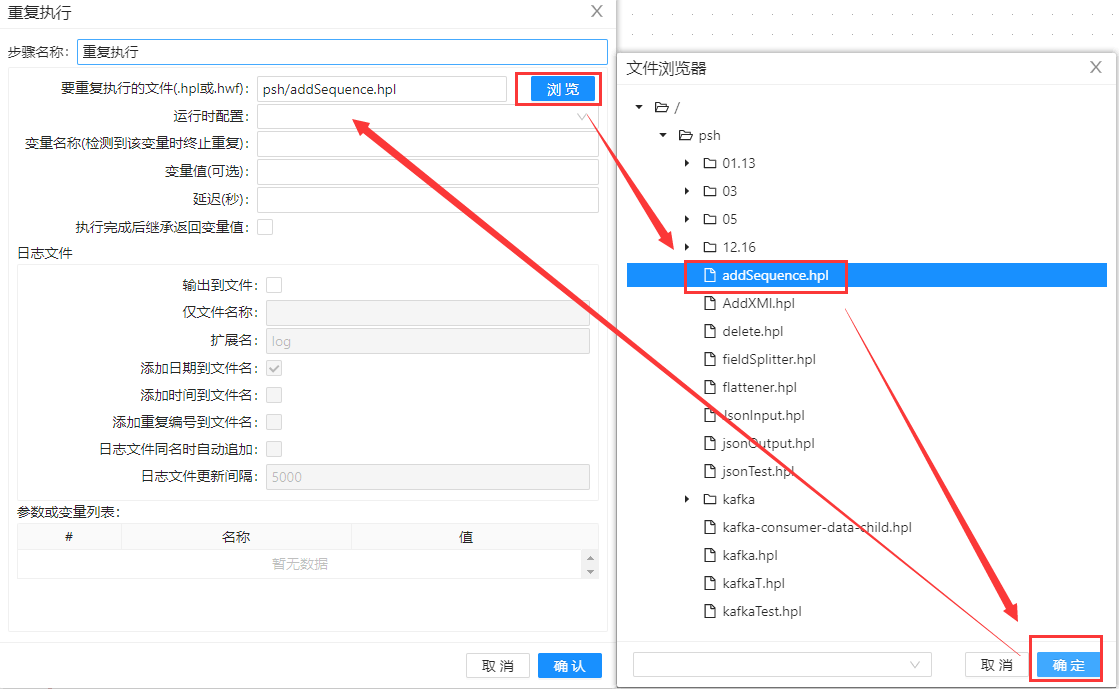
第一步、拖动“重复执行”组件到工作区,双击打开,点击浏览,选择要重复执行的hpl文件或hwf文件。在这个示例里面具体操作如下图所示:
第二步、拖动“启动”组件到工作区,这个组件在前,将其和“检查目录是否为空”组件连接起来。这个组件在这里没有特别的功能,只是作为执行workflow的其实组件。这里不用这个组件也可以。详情如下图所示。
第三步、点击运行,在“从...开始执行作业”选择“启动”,点击确定。
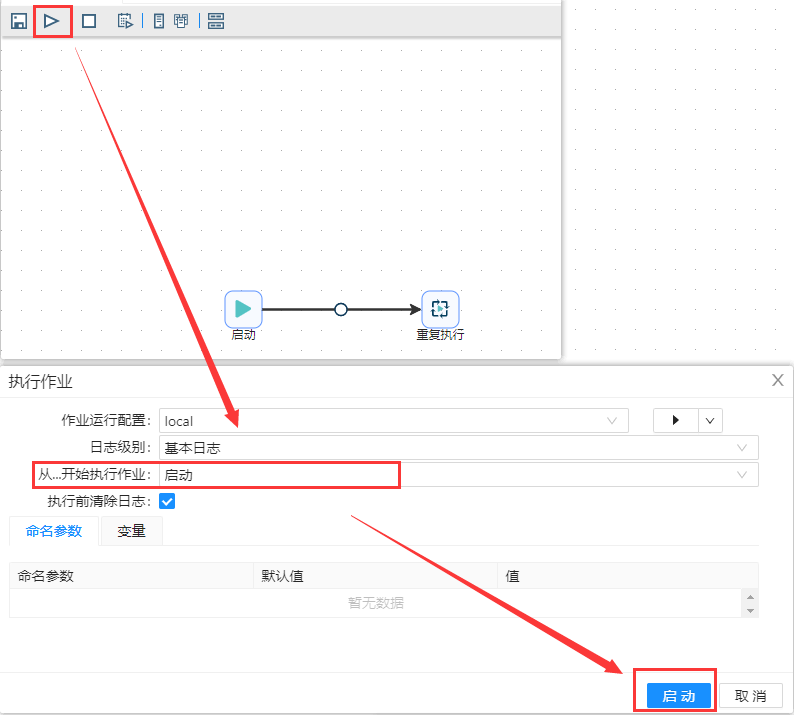
第四步、点击确定可以看到运行结果。如下图所示。
