MongoDB Input
组件介绍
MongoDB Input组件用于从MongoDB中的集合中检索文档或记录。
- 输入:MongoDB中的数据集合
- 输出:根据要求检索到的文档或记录
页面介绍
运行MongoDB Input组件得到下图所示的界面:
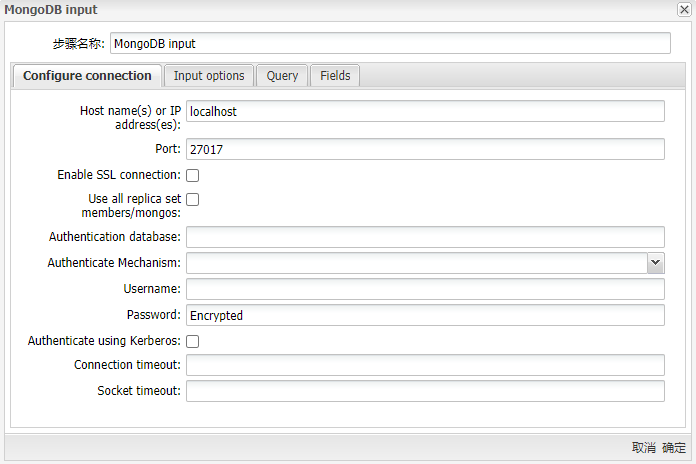

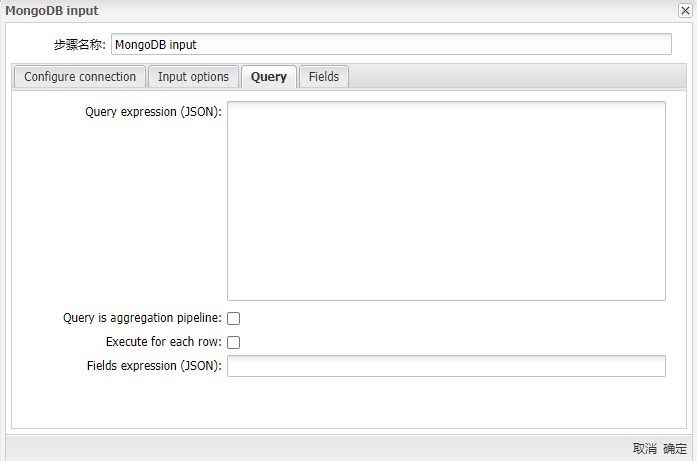

参数选项
MongoDB Input组件页面包含如下选项:
| 选项 | 说明 | 样例值 |
|---|---|---|
| 步骤名称 | 在画布上指定MongoDB Input步骤的唯一名称,可以自定义名称或保留默认名称。 | MongoDB Input |
| Host name(s) or IP address(es) | 指定一个或多个MongoDB实例的网络名称或地址。您还可以通过用冒号分隔主机名和端口号来为每个主机名指定不同的端口号。您可以输入多个主机名或IP地址,以逗号分隔 | localhost |
| Port | 指定一个或多个MongoDB实例的端口号。如果在主机名或IP地址字段中未提供任何端口,请使用此选项指定默认端口 | 27017 |
| Enable SSL connection | 指定连接到配置了SSL的MongoDB服务器 | |
| Use all replica set members/mongos | 当在“主机名”或“ IP地址”字段中指定了多个主机时,选择以使用所有副本集。 | |
| 如果副本集包含多个主机,则Java驱动程序会自动发现所有主机。如果所选集不可用,驱动程序将连接到列表中的下一个副本集。 | ||
| Authentication database | 指定身份验证数据库) | |
| Authenticate Mechanism | 选择用于验证用户身份的方法。值为SCRAM-SHA-1和MONGODB-CR | |
| Username | 指定访问数据库所需的用户名。使用Kerberos身份验证时,输入Kerberos主体 | |
| Password | 指定与用户名关联的密码。如果使用Kerberos身份验证,则无需输入密码 | |
| Authenticate using Kerberos | 选择以指定使用Kerberos的身份验证。选择后,输入Kerberos主体作为Username | |
| Connection timeout | 指定(以毫秒为单位)在终止连接尝试之前等待与数据库连接的时间。留空以永不终止连接 | |
| Socket timeout | 指定(以毫秒为单位)终止写入操作之前等待写操作的时间。留空以永不终止操作 | |
| Preview | 显示此步骤生成的行。输入要预览的最大记录数,然后单击确定。预览数据出现在“检查预览数据”窗口中 | |
| Database | 要从中检索数据的数据库的名称。单击获取数据块与服务器上的数据库列表来填充下拉菜单 | db |
| Collection | 要从中检索数据的集合的名称。单击获取集合,以使用数据库中的集合列表填充下拉菜单 | collection |
| Read preference | 指定首先读取哪个节点:主要,主要首选,次要,首选次要或最近 | primary |
| Query expression (JSON) | 在此字段中输入查询表达式以限制输出 | |
| Aggregation pipeline specification (JSON) | 选择“查询是聚合管道”选项以显示“聚合管道规范(JSON)”字段。然后输入管道表达式以执行聚合或选择。方法名称,包括您在“输入选项”选项卡中选择的数据库的集合名称,出现在此字段的标签之后 | |
| Query is aggregation pipeline | 选择此选项以使用聚合管道框架 | |
| Execute for each row | 选择此选项可对每行数据执行查询 | |
| Fields expression (JSON) | 输入参数以控制查询的投影(要返回的字段)。如果为空,则返回所有字段。该字段仅可用于查询表达式 | |
| Output single JSON field | 指定查询结果是具有String数据类型(默认)的单个JSON字段 | 勾选 |
| Name of JSON output field | 指定包含服务器的JSON输出的字段名称 | json |
| Name | 基于“路径”字段中的值的字段名称。此处显示的名称将PDI转换中显示的字段名称与MongoDB数据库中显示的字段进行映射,可以编辑名称 | |
| Path | 指示MongoDB中字段的JSON路径。如果显示的路径是数组,则可以通过在数组的方括号部分中传递键值来指定数组的特定元素,要显示所有数组值,请使用星号作为键 | |
| Type | 指示数据类型 | |
| Indexed values | 为字符串字段指定逗号分隔的合法值列表。在此字段中指定值时,水壶索引数据类型将应用于数据。如果未指定任何值,则将应用String数据类型。通常,仅在将Weka元数据用于名义字段时才需要修改此字段 | |
| Sample: array min: max index | 指示样本文档中索引的最小值和最大值 | |
| Sample: #occur/#docs | 指示该字段出现的频率和处理的文档数 | |
| Sample: disparate types | 指示是否有不同的数据类型填充样本文档中的相同字段。当对多个文档进行采样并且同一字段包含不同的数据类型时,在Sample:disparate types字段中填充“ Y”,并且Type字段显示String数据类型。对于不同的输出值类型,该字段的Kettle类型设置为String数据类型 |