分组
组件介绍
“分组”组件基于指定的字段或字段集合将源中的行分组。每个组都会生成一个新行。它还可以为组生成一个或多个聚合值。常见用途是计算每种产品的平均销售额,并计算您有库存的物品的数量。
- 输入:数据流
- 输出:分组集合后的数据流
页面介绍
运行“分组”组件得到下图所示的界面:
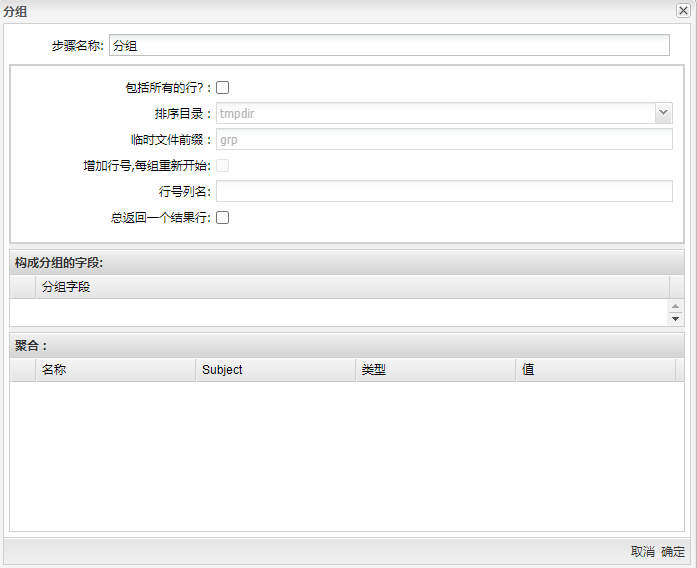
参数选项
“分组”组件主要包括如下参数:
| 选项 | 说明 | 样例值 |
|---|---|---|
| 步骤名称 | 指定画布上步骤的唯一名称。 | |
| 包括所有行? | 选择是否要在输出中包括所有行,而不是仅包括聚合行。除非选择了“包括所有行”选项,否则以下选项不可用:
| |
| 临时文件前缀 | 指定存储临时文件的目录。默认值为系统的标准临时目录。选择“包括所有行”选项并且分组的行数超过5000行时,必须指定目录。 | |
| 增加行号,每组重新开始 | 在每个组中重新在每个组中添加以1重新开始的行号。当选择包括所有行并且此选项都被选中时,所有行都包括在输出中,并且每行都有一个行号。 | |
| 行号列名 | 指定要在其中为每个新组添加行号的字段的名称。 | |
| 总返回一个结果行 | 返回结果行,即使没有输入行也是如此。没有输入行时,此选项将返回零(0)的计数。 | |
| 分组字段 | 指定要分组的字段。 | |
| 名称 | 聚合字段的名称。 | |
| subject | 您要在其上使用聚合方法的主题。 | |
| 类型 | 填写聚合方法,聚合方法可以是以下方法:
| |
| 值 | 集合值 |
使用案例
本案例中,用“自定义常量数据”组件生成了原始数据,用“分组”组件对其进行了简单分组。
“自定义常量数据”生成的数据如下所示:
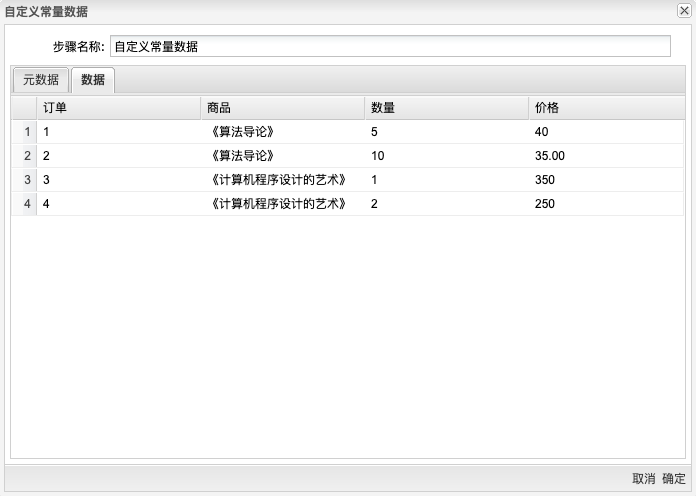
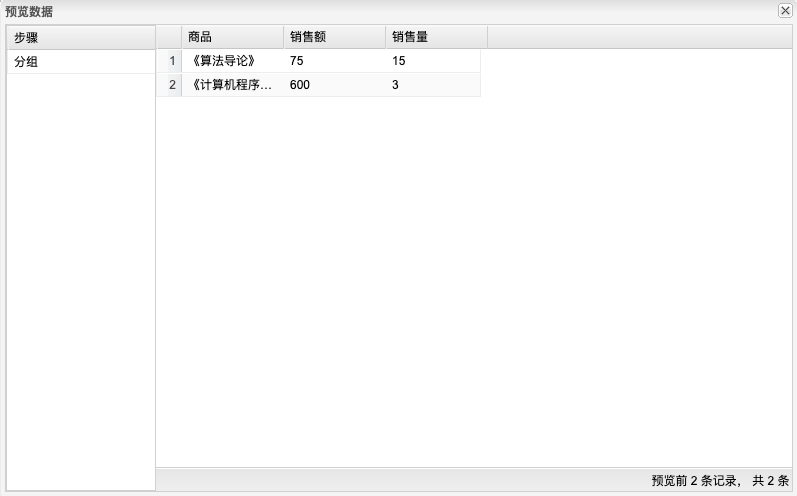
在分组中设置按“商品”分类,“数量”求和生成“销售量”,“价格”求和生成“销售额”
右键“分组”,点击“预览”可得下图
至此“分组”组件的使用案例介绍完毕。