文本分类
组件介绍
**“文本分类”(Text Classification)**控件主要用于训练文本分类模型。
文本分类是一种常见的 NLP 任务,文本分类模型将文本依据规则和标准划分到为特定的类别空间,文本分类任务可用于垃圾邮件识别,情感分析等场景。
- 输入:
- text: 文本数据集
- 输出:
- dpmod:深度学习模型
**“文本分类”(Text Classification)**控件读取文本分类数据集,通过指定要训练的模型及相关的训练参数进行文本分类模型的训练。 训练集目录结构如下:
|- train.txt
|- val.txt
train.txt用于记录训练集数据信息,包括标注及文本信息,其中第一列为标注(label),第二列为文本内容(text),数据集要求列名固定,两列之间以\t为分隔符,train.txt内容示例如下:
label text
0 #广州#【广州游行打砸抢罪犯资料公布!居然是日本间谍!】
0 哈佛墙上的话:我荒废的今日,正是昨天殒身之人祈求的明天;请享受无法�回避的痛苦;觉得自己为时已晚的时候,恰恰是最早的时候;谁也不可能轻易成功,它来自彻底的自我管理和毅力;现在流的口水,将成为明天的眼泪;今天不走,明天要跑;即使此刻,对手也在不停地翻动书页。(转)
1 有木有人和我一样。睡觉时头总爱靠在枕头的一角。据说这样的孩纸,都没安全感。
val.txt用于记录验证集数据信息,包括标注及文本信息,val.txt内容示例如下:
label text
1 住在四季酒店,才驚覺广州的夜景真美,酒店的安排亦很贴心;👏👍唯一要投诉的就是這些套房中間是有相連的門連接往其他房間,隣居的年轻朋友可能正在庆祝平安度过世界没日,氣氛非常熱鬧,我完全感受得到![汗][吃惊](我在懷疑,這不是雙重門嗎?為什么隔声這样差?[疑问])[做鬼脸]
1 某人对你的恶毒,源于嫉妒,说明在某些方面你给他添了堵。
0 吃榴莲后,喝可口可乐,毒过眼镜蛇! 又一游客,客死泰国异乡!
测试集目录结构如下:
|- test.txt
test.txt用于记录测试集数据信息,包括文本信息,test.txt内容示例如下:
text
演唱结束,麻衣接受了主持人吴大维的采访,九连拍的麻衣仍旧是那么可爱[鼓掌]
2月30号,我们在休假,蒙牛却在为我们生产良心奶[泪]via:钢铁侠Z
页面介绍
点击**“文本分类”(Text Classification)**控件查看参数配置页面,如下图所示:
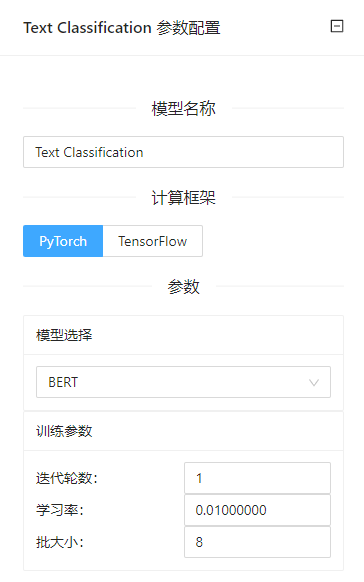
参数选项
| 选项 | 说明 | 取值范围 | 样例值 | |
|---|---|---|---|---|
| 模型名称 | 设置模型名称,用于在其他组件中区分不同的模型 | 非空字符串 | Text Classification | |
| 计算框架 | 选择模型训练采用的训练框架,控件支持如下计算框架: | PyTorch | PyTorch | |
| 模型选择 | PyTorch | 支持的用于文本分类的深度学习模型 | BERT | BERT |
| Tensorflow | BERT | BERT | ||
| 训练参数 | 迭代轮数 | 训练迭代轮数(epoch) | 1~100000 | 10 |
| 学习率 | learning rate | 0.00000001~1 | 0.001 | |
| 批大小 | 一个epoch训练的样本大小 | 1~840 | 8 | |
使用案例
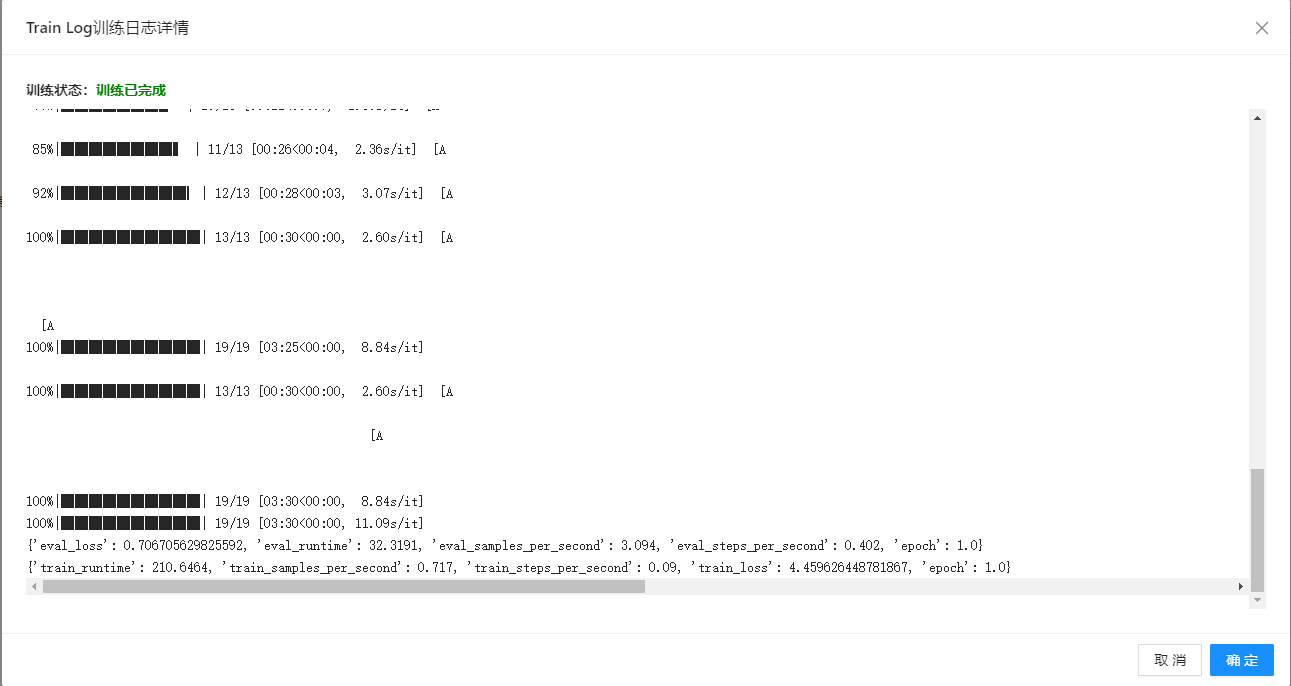
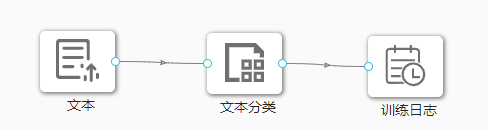
在下图所示的案例中,使用**“文本”(Text)控件加载数据集,连接“文本分类”(Text Classification)控件构建模型,再将“文本分类”(Text Classification)控件与“训练日志”(Train Log)**控件连接起来查看模型的训练日志。
案例中控件执行结果如下图所示: