混淆矩阵
组件介绍
**“混淆矩阵”(Confusion Matrix)**控件显示预测类和实际类之间的比例。
混淆矩阵是一种特殊的, 具有两个维度的(实际和预测)列联表(英语:contingency table),并且两维度中都有着一样的类别的集合。从混淆矩阵可得出预测类和实际类之间实例的数量或比例。通过这种方式可以得到哪些实例被错误分类以及被分成了哪一类。矩阵的每一列代表一个类的实例预测,而每一行表示一个实际的类的实例。
- 输入:
- evr:分类器对数据的测试结果
- 输出:
- 无
页面介绍
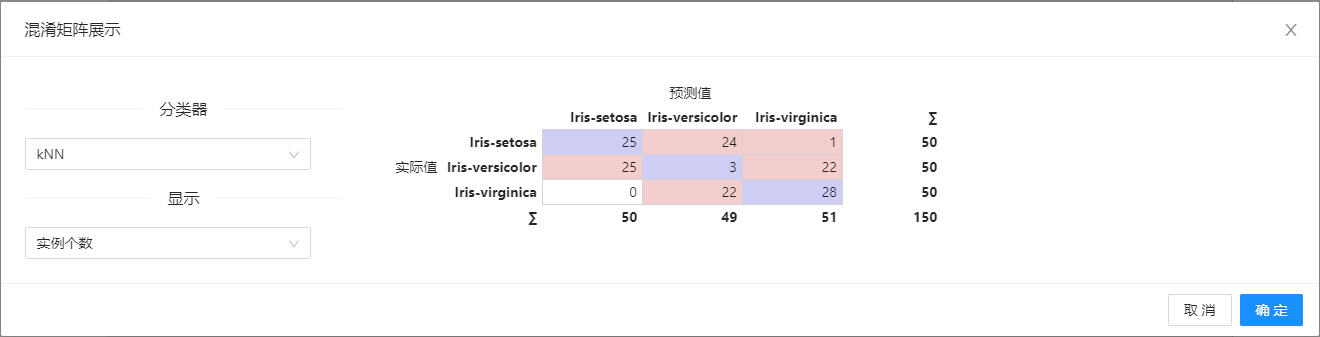
点击**“混淆矩阵”(Confusion Matrix)**控件查看参数配置页面,如下图所示:

点击**“查看结果”**按钮,查看曲线:
参数选项
| 选项 | 说明 | 样例值 | |
|---|---|---|---|
| 分类器 | 要评估的数据挖掘模型,当选择后会绘制该模型的混淆矩阵 | 要评估的数据挖掘模型 | |
| 显示 | 选择在矩阵中显��示的数据: | 实例个数 | 实例个数 |
使用案例
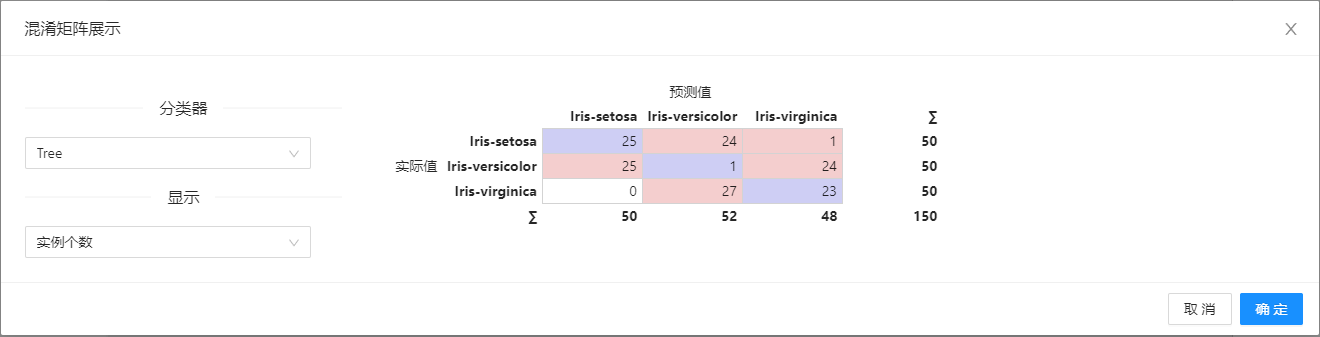
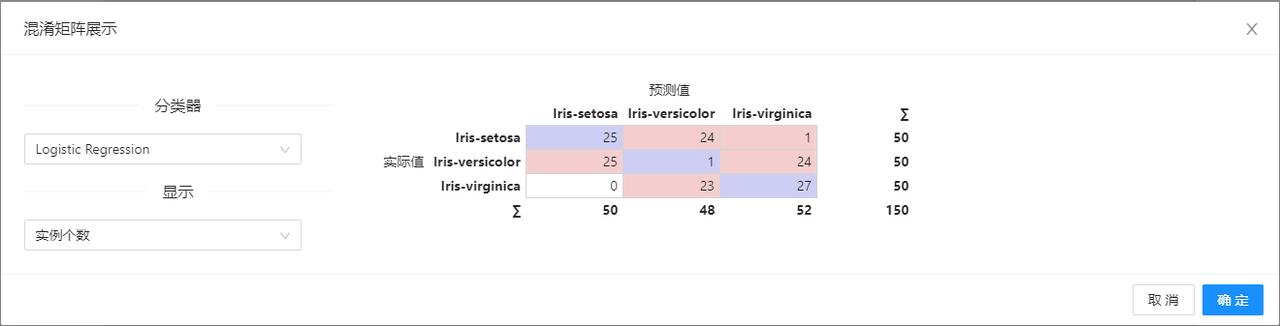
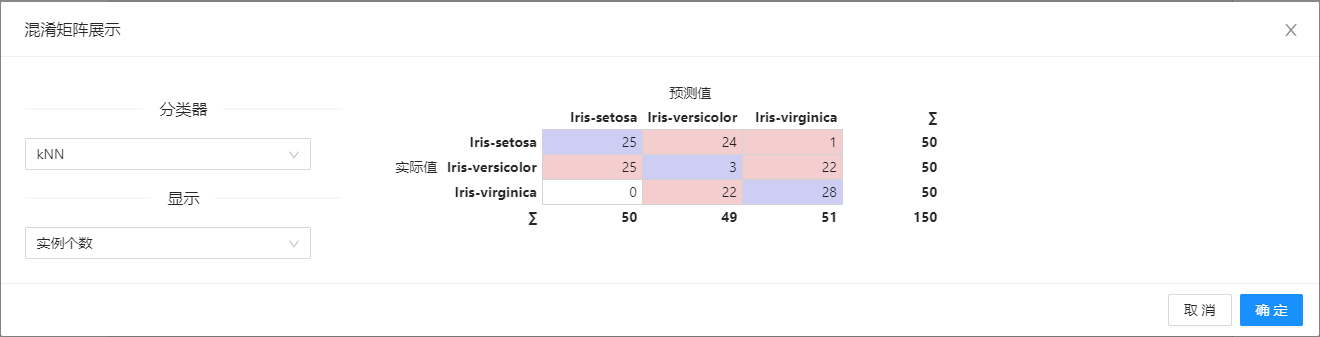
在下图所示的案例中,使用**“加载文件”(File)控件加载数据,使用“K近邻”(KNN)、“决策树”(Tree)、“逻辑回归”(Logistic Regression)等模型在“评分和测试”(Test & Score)控件中进行测试和评估,最后将评估结果在“混淆矩阵”(Confusion Matrix)**控件中进行展示。
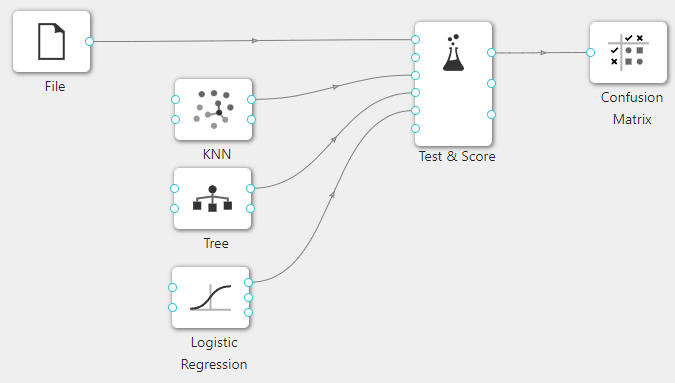
案例中加载 titanic 数据集,针对**“K近邻”(KNN)、“决策树”(Tree)、“逻辑回归”(Logistic Regression)算法进行测试和评估,“评分和测试”(Test & Score)显示每个分类器的评估结果。然后根据“评分和测试”(Test & Score)的结果绘制混淆矩阵,以进一步交叉验证算法的预测结果。“混淆矩阵”(Confusion Matrix)**可以查看有多少实例被错误分类以及错误的类型,案例中控件的配置以及执行结果如下图所示。